pytorch下的unsqueeze和squeeze的用法说明
#squeeze 函数:从数组的形状中删除单维度条目,即把shape中为1的维度去掉
#unsqueeze() 是squeeze()的反向操作,增加一个维度,该维度维数为1,可以指定添加的维度。例如unsqueeze(a,1)表示在1这个维度进行添加
import torch a=torch.rand(2,3,1) print(torch.unsqueeze(a,2).size())#torch.Size([2, 3, 1, 1]) print(a.size()) #torch.Size([2, 3, 1]) print(a.squeeze().size()) #torch.Size([2, 3]) print(a.squeeze(0).size()) #torch.Size([2, 3, 1]) print(a.squeeze(-1).size()) #torch.Size([2, 3]) print(a.size()) #torch.Size([2, 3, 1]) print(a.squeeze(-2).size()) #torch.Size([2, 3, 1]) print(a.squeeze(-3).size()) #torch.Size([2, 3, 1]) print(a.squeeze(1).size()) #torch.Size([2, 3, 1]) print(a.squeeze(2).size()) #torch.Size([2, 3]) print(a.squeeze(3).size()) #RuntimeError: Dimension out of range (expected to be in range of [-3, 2], but got 3) print(a.unsqueeze().size()) #TypeError: unsqueeze() missing 1 required positional arguments: "dim" print(a.unsqueeze(-3).size()) #torch.Size([2, 1, 3, 1]) print(a.unsqueeze(-2).size()) #torch.Size([2, 3, 1, 1]) print(a.unsqueeze(-1).size()) #torch.Size([2, 3, 1, 1]) print(a.unsqueeze(0).size()) #torch.Size([1, 2, 3, 1]) print(a.unsqueeze(1).size()) #torch.Size([2, 1, 3, 1]) print(a.unsqueeze(2).size()) #torch.Size([2, 3, 1, 1]) print(a.unsqueeze(3).size()) #torch.Size([2, 3, 1, 1]) print(torch.unsqueeze(a,3)) b=torch.rand(2,1,3,1) print(b.squeeze().size()) #torch.Size([2, 3])
补充:pytorch中unsqueeze()、squeeze()、expand()、repeat()、view()、和cat()函数的总结
学习Bert模型的时候,需要使用到pytorch来进行tensor的操作,由于对pytorch和tensor不熟悉,就把pytorch中常用的、有关tensor操作的unsqueeze()、squeeze()、expand()、view()、cat()和repeat()等函数做一个总结,加深记忆。
1、unsqueeze()和squeeze()
torch.unsqueeze(input, dim,out=None) → Tensor
unsqueeze()的作用是用来增加给定tensor的维度的,unsqueeze(dim)就是在维度序号为dim的地方给tensor增加一维。例如:维度为torch.Size([768])的tensor要怎样才能变为torch.Size([1, 768, 1])呢?就可以用到unsqueeze(),直接上代码:
a=torch.randn(768) print(a.shape) # torch.Size([768]) a=a.unsqueeze(0) print(a.shape) #torch.Size([1, 768]) a = a.unsqueeze(2) print(a.shape) #torch.Size([1, 768, 1])
也可以直接使用链式编程:
a=torch.randn(768) print(a.shape) # torch.Size([768]) a=a.unsqueeze(1).unsqueeze(0) print(a.shape) #torch.Size([1, 768, 1])
tensor经过unsqueeze()处理之后,总数据量不变;维度的扩展类似于list不变直接在外面加几层[]括号。
torch.squeeze(input, dim=None, out=None) → Tensor
squeeze()的作用就是压缩维度,直接把维度为1的维给去掉。形式上表现为,去掉一层[]括号。
同时,输出的张量与原张量共享内存,如果改变其中的一个,另一个也会改变。
a=torch.randn(2,1,768) print(a) print(a.shape) #torch.Size([2, 1, 768]) a=a.squeeze() print(a) print(a.shape) #torch.Size([2, 768])
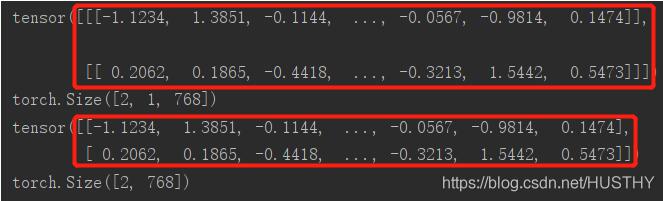
图片中的维度信息就不一样,红框中的括号层数不同。
注意的是:squeeze()只能压缩维度为1的维;其他大小的维不起作用。
a=torch.randn(2,768) print(a.shape) #torch.Size([2, 768]) a=a.squeeze() print(a.shape) #torch.Size([2, 768])
2、expand()
这个函数的作用就是对指定的维度进行数值大小的改变。只能改变维大小为1的维,否则就会报错。不改变的维可以传入-1或者原来的数值。
torch.Tensor.expand(*sizes) → Tensor
返回张量的一个新视图,可以将张量的单个维度扩大为更大的尺寸。
a=torch.randn(1,1,3,768) print(a) print(a.shape) #torch.Size([1, 1, 3, 768]) b=a.expand(2,-1,-1,-1) print(b) print(b.shape) #torch.Size([2, 1, 3, 768]) c=a.expand(2,1,3,768) print(c.shape) #torch.Size([2, 1, 3, 768])
可以看到b和c的维度是一样的
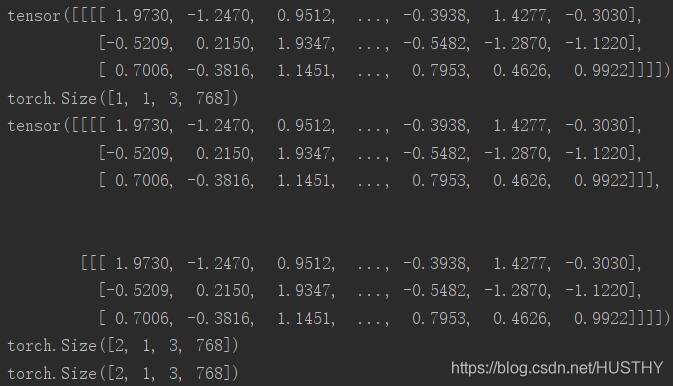
第0维由1变为2,可以看到就直接把原来的tensor在该维度上复制了一下。
3、repeat()
repeat(*sizes)
沿着指定的维度,对原来的tensor进行数据复制。这个函数和expand()还是有点区别的。expand()只能对维度为1的维进行扩大,而repeat()对所有的维度可以随意操作。
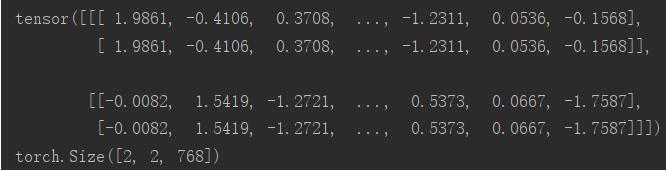
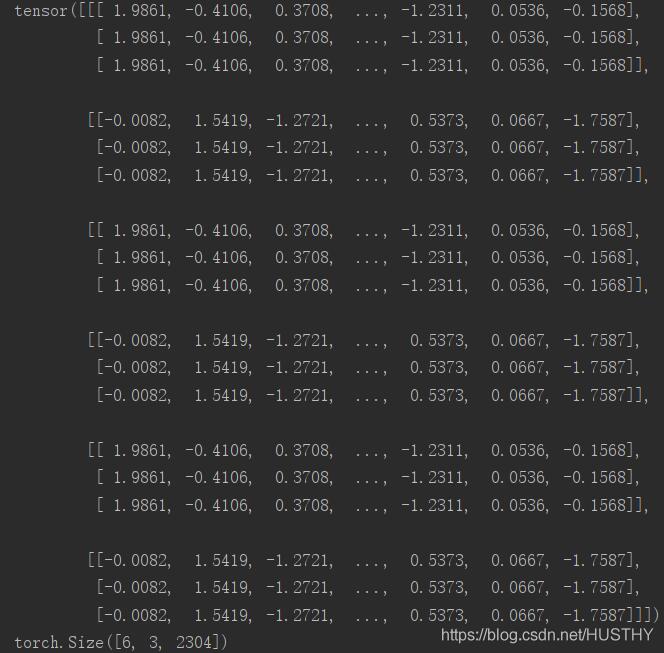
a=torch.randn(2,1,768) print(a) print(a.shape) #torch.Size([2, 1, 768]) b=a.repeat(1,2,1) print(b) print(b.shape) #torch.Size([2, 2, 768]) c=a.repeat(3,3,3) print(c) print(c.shape) #torch.Size([6, 3, 2304])
b表示对a的对应维度进行乘以1,乘以2,乘以1的操作,所以b:torch.Size([2, 1, 768])
c表示对a的对应维度进行乘以3,乘以3,乘以3的操作,所以c:torch.Size([6, 3, 2304])
a:

b
c
4、view()
tensor.view()这个函数有点类似reshape的功能,简单的理解就是:先把一个tensor转换成一个一维的tensor,然后再组合成指定维度的tensor。例如:
word_embedding=torch.randn(16,3,768) print(word_embedding.shape) new_word_embedding=word_embedding.view(8,6,768) print(new_word_embedding.shape)
当然这里指定的维度的乘积一定要和原来的tensor的维度乘积相等,不然会报错的。16*3*768=8*6*768
另外当我们需要改变一个tensor的维度的时候,知道关键的维度,有不想手动的去计算其他的维度值,就可以使用view(-1),pytorch就会自动帮你计算出来。
word_embedding=torch.randn(16,3,768) print(word_embedding.shape) new_word_embedding=word_embedding.view(-1) print(new_word_embedding.shape) new_word_embedding=word_embedding.view(1,-1) print(new_word_embedding.shape) new_word_embedding=word_embedding.view(-1,768) print(new_word_embedding.shape)
结果如下:使用-1以后,就会自动得到其他维度维。
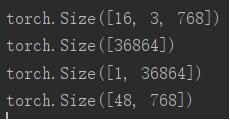
需要特别注意的是:view(-1,-1)这样的用法就会出错。也就是说view()函数中只能出现单个-1。
5、cat()
cat(seq,dim,out=None),表示把两个或者多个tensor拼接起来。
其中 seq表示要连接的两个序列,以元组的形式给出,例如:seq=(a,b), a,b 为两个可以连接的序列
dim 表示以哪个维度连接,dim=0, 横向连接 dim=1,纵向连接
a=torch.randn(4,3) b=torch.randn(4,3) c=torch.cat((a,b),dim=0)#横向拼接,增加行 torch.Size([8, 3]) print(c.shape) d=torch.cat((a,b),dim=1)#纵向拼接,增加列 torch.Size([4, 6]) print(d.shape)
还有一种写法:cat(list,dim,out=None),其中list中的元素为tensor。
tensors=[] for i in range(10): tensors.append(torch.randn(4,3)) a=torch.cat(tensors,dim=0) #torch.Size([40, 3]) print(a.shape) b=torch.cat(tensors,dim=1) #torch.Size([4, 30]) print(b.shape)
结果:
torch.Size([40, 3]) torch.Size([4, 30])
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
详解pytorch中squeeze()和unsqueeze()函数介绍
squeeze的用法主要就是对数据的维度进行压缩或者解压. 先看torch.squeeze() 这个函数主要对数据的维度进行压缩,去掉维数为1的的维度,比如是一行或者一列这种,一个一行三列(1,3)的数去掉第一个维数为一的维度之后就变成(3)行.squeeze(a)就是将a中所有为1的维度删掉.不为1的维度没有影响.a.squeeze(N) 就是去掉a中指定的维数为一的维度.还有一种形式就是b=torch.squeeze(a,N) a中去掉指定的定的维数为一的维度. 再看torch.unsque
-
PyTorch安装与基本使用详解
什么要学习PyTorch? 有的人总是选择,选择的人最多的框架,来作为自己的初学框架,比如Tensorflow,但是大多论文的实现都是基于PyTorch的,如果我们要深入论文的细节,就必须选择学习入门PyTorch 安装PyTorch 一行命令即可 官网 pip install torch===1.6.0 torchvision===0.7.0 - https://download.pytorch.org/whl/torch_stable.html 时间较久,耐心等待 测试自己是否安装成功 运行
-
Pytorch损失函数nn.NLLLoss2d()用法说明
最近做显著星检测用到了NLL损失函数 对于NLL函数,需要自己计算log和softmax的概率值,然后从才能作为输入 输入 [batch_size, channel , h, w] 目标 [batch_size, h, w] 输入的目标矩阵,每个像素必须是类型.举个例子.第一个像素是0,代表着类别属于输入的第1个通道:第二个像素是0,代表着类别属于输入的第0个通道,以此类推. x = Variable(torch.Tensor([[[1, 2, 1], [2, 2, 1], [0, 1, 1]]
-

pytorch下的unsqueeze和squeeze的用法说明
#squeeze 函数:从数组的形状中删除单维度条目,即把shape中为1的维度去掉 #unsqueeze() 是squeeze()的反向操作,增加一个维度,该维度维数为1,可以指定添加的维度.例如unsqueeze(a,1)表示在1这个维度进行添加 import torch a=torch.rand(2,3,1) print(torch.unsqueeze(a,2).size())#torch.Size([2, 3, 1, 1]) print(a.size()) #torch.Size([2,
-
解决pytorch下出现multi-target not supported at的一种可能原因
在使用交叉熵损失函数的时候,target的形状应该是和label的形状一致或者是只有batchsize这一个维度的. 如果target是这样的[batchszie,1]就会出现上述的错误. 改一下试试,用squeeze()函数降低纬度, 如果不知道squeeze怎么用的, 可以参考这篇文章.pytorch下的unsqueeze和squeeze用法 这只是一种可能的原因. 补充:pytorch使用中遇到的问题 1. load模型参数文件时,提示torch.cuda.is_available() i
-
pytorch下使用LSTM神经网络写诗实例
在pytorch下,以数万首唐诗为素材,训练双层LSTM神经网络,使其能够以唐诗的方式写诗. 代码结构分为四部分,分别为 1.model.py,定义了双层LSTM模型 2.data.py,定义了从网上得到的唐诗数据的处理方法 3.utlis.py 定义了损失可视化的函数 4.main.py定义了模型参数,以及训练.唐诗生成函数. 参考:电子工业出版社的<深度学习框架PyTorch:入门与实践>第九章 main代码及注释如下 import sys, os import torch as t fr
-
linux下定时执行任务的方法及crontab 用法说明(收集整理)
linux下定时执行任务的方法 在LINUX中,周期执行的任务一般由cron这个守护进程来处理[ps -ef|grep cron].cron读取一个或多个配置文件,这些配置文件中包含了命令行及其调用时间. cron的配置文件称为"crontab",是"cron table"的简写. 一.cron在3个地方查找配置文件: 1./var/spool/cron/ 这个目录下存放的是每个用户包括root的crontab任务,每个任务以创建者的名字命名,比如tom建的cron
-
Linux下netstat命令的一些常见用法
简介 Netstat 命令用于显示各种网络相关信息,如网络连接,路由表,接口状态 (Interface Statistics),masquerade 连接,多播成员 (Multicast Memberships) 等等. 输出信息含义 执行netstat后,其输出结果为 Active Internet connections (w/o servers) Proto Recv-Q Send-Q Local Address Foreign Address State tcp 0 2 210.34.6
-
Java Swing组件下拉菜单控件JComboBox用法示例
本文实例讲述了Java Swing组件下拉菜单控件JComboBox用法.分享给大家供大家参考,具体如下: JComboBox是Swing中的下拉菜单控件.它永远只能选中一个项目,然而比单选按钮节省空间.如果使用setEditable设置为true则内部选项的文本可以编辑,因此这种组件被称为组合框.注意,对选项的编辑只会影响当前项,而不会改变列表内容.可以使用addItem方法来添加选项列表,或者使用insertItemAt在任何位置插入选项:然而如果有大量选项需要添加,这种方法是非常笨重的,可
-
pytorch下大型数据集(大型图片)的导入方式
使用torch.utils.data.Dataset类 处理图片数据时, 1. 我们需要定义三个基本的函数,以下是基本流程 class our_datasets(Data.Dataset): def __init__(self,root,is_resize=False,is_transfrom=False): #这里只是个参考.按自己需求写. self.root=root self.is_resize=is_resize self.is_transfrom=is_transfrom self.i
-
PyTorch中model.zero_grad()和optimizer.zero_grad()用法
废话不多说,直接上代码吧~ model.zero_grad() optimizer.zero_grad() 首先,这两种方式都是把模型中参数的梯度设为0 当optimizer = optim.Optimizer(net.parameters())时,二者等效,其中Optimizer可以是Adam.SGD等优化器 def zero_grad(self): """Sets gradients of all model parameters to zero.""
-
tensorflow下的图片标准化函数per_image_standardization用法
实验环境:windows 7,anaconda 3(Python 3.5),tensorflow(gpu/cpu) 函数介绍:标准化处理可以使得不同的特征具有相同的尺度(Scale). 这样,在使用梯度下降法学习参数的时候,不同特征对参数的影响程度就一样了. tf.image.per_image_standardization(image),此函数的运算过程是将整幅图片标准化(不是归一化),加速神经网络的训练. 主要有如下操作,(x - mean) / adjusted_stddev,其中x为图
-
pytorch下tensorboard的使用程序示例
目录 一.tensorboard程序实例: 1.代码 2.在命令提示符中操作 3.在浏览器中打开网址 4.效果 二.writer.add_scalar()与writer.add_scalars()参数说明 1.概述 2.参数说明 3.writer.add_scalar()效果 4.writer.add_scalars()效果 我们都知道tensorflow框架可以使用tensorboard这一高级的可视化的工具,为了使用tensorboard这一套完美的可视化工具,未免可以将其应用到Pytorc