MYSQL row_number()与over()函数用法详解
语法格式:row_number() over(partition by 分组列 order by 排序列 desc)
row_number() over()分组排序功能:
在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where 、group by、 order by 的执行。
例一:
表数据:
create table TEST_ROW_NUMBER_OVER(
id varchar(10) not null,
name varchar(10) null,
age varchar(10) null,
salary int null
);
select * from TEST_ROW_NUMBER_OVER t;
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a',10,8000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(1,'a2',11,6500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b',12,13000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(2,'b2',13,4500);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c',14,3000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(3,'c2',15,20000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(4,'d',16,30000);
insert into TEST_ROW_NUMBER_OVER(id,name,age,salary) values(5,'d2',17,1800);
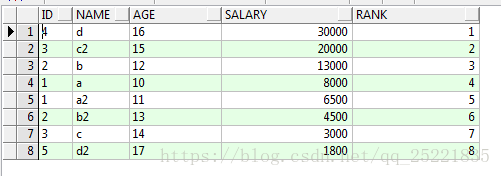
一次排序:对查询结果进行排序(无分组)
select id,name,age,salary,row_number()over(order by salary desc) rn from TEST_ROW_NUMBER_OVER t
结果:
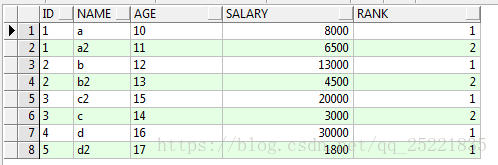
进一步排序:根据id分组排序
select id,name,age,salary,row_number()over(partition by id order by salary desc) rank from TEST_ROW_NUMBER_OVER t
结果:
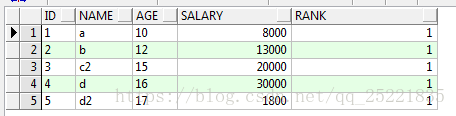
再一次排序:找出每一组中序号为一的数据
select * from(select id,name,age,salary,row_number()over(partition by id order by salary desc) rank from TEST_ROW_NUMBER_OVER t) where rank <2
结果:
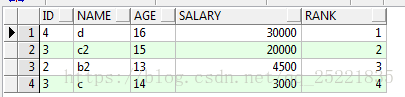
排序找出年龄在13岁到16岁数据,按salary排序
select id,name,age,salary,row_number()over(order by salary desc) rank from TEST_ROW_NUMBER_OVER t where age between '13' and '16'
结果:结果中 rank 的序号,其实就表明了 over(order by salary desc) 是在where age between and 后执行的
例二:
1.使用row_number()函数进行编号,如
select email,customerID, ROW_NUMBER() over(order by psd) as rows from QT_Customer
原理:先按psd进行排序,排序完后,给每条数据进行编号。
2.在订单中按价格的升序进行排序,并给每条记录进行排序代码如下:
select DID,customerID,totalPrice,ROW_NUMBER() over(order by totalPrice) as rows from OP_Order
3.统计出每一个各户的所有订单并按每一个客户下的订单的金额 升序排序,同时给每一个客户的订单进行编号。这样就知道每个客户下几单了:
select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order
4.统计每一个客户最近下的订单是第几次下的订单:
with tabs as ( select ROW_NUMBER() over(partition by customerID order by totalPrice) as rows,customerID,totalPrice, DID from OP_Order ) select MAX(rows) as '下单次数',customerID from tabs group by customerID
5.统计每一个客户所有的订单中购买的金额最小,而且并统计改订单中,客户是第几次购买的:
思路:利用临时表来执行这一操作。
1.先按客户进行分组,然后按客户的下单的时间进行排序,并进行编号。
2.然后利用子查询查找出每一个客户购买时的最小价格。
3.根据查找出每一个客户的最小价格来查找相应的记录。
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by insDT)
as rows,customerID,totalPrice, DID from OP_Order
)
select * from tabs
where totalPrice in
(
select MIN(totalPrice)from tabs group by customerID
)
6.筛选出客户第一次下的订单。
思路。利用rows=1来查询客户第一次下的订单记录。
with tabs as
(
select ROW_NUMBER() over(partition by customerID order by insDT) as rows,* from OP_Order
)
select * from tabs where rows = 1
select * from OP_Order
7.注意:在使用over等开窗函数时,over里头的分组及排序的执行晚于“where,group by,order by”的执行。
select
ROW_NUMBER() over(partition by customerID order by insDT) as rows,
customerID,totalPrice, DID
from OP_Order where insDT>'2011-07-22'
到此这篇关于MYSQL row_number()与over()函数用法详解的文章就介绍到这了,更多相关MYSQL row_number()与over()函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Django搭建MySQL主从实现读写分离
目录 一.MySQL主从搭建 操作步骤 二.Django实现读写分离 自动指定 一.MySQL主从搭建 主从配置原理: 主库写日志到 BinLog 从库开个 IO 线程读取主库的 BinLog 日志,并写入 RelayLog 再开一个 SQL 线程,读 RelayLog 日志,回放到从库中 主从配置流程: master 会将变动记录到二进制日志里面: master 有一个 I/O 线程将二进制日志发送到 slave: salve 有一个 I/O 线程把 master 发送的二进制写入到 rela
-

一篇文章带你了解MySQL数据库基础
目录 1. 数据库概念 1.1 数据库是干嘛的? 1.2 数据库和数据结构是啥关系? 1. 数据库是一个软件/程序 2. 数据结构是一个学科~ 1.3 两种类型的数据库 2. MySQL数据库 2.1 MySQL数据库概念 2.2 MySQL基本操作 2.2.1 建立数据库 2.2.2 查看数据库 2.2.3 选中数据库 2.2.4 删除数据库 2.3 MySQL数据类型 总结 1. 数据库概念 1.1 数据库是干嘛的? 数据库的功能就是用来组织数据,组织很多很多的数据.这些数据通常都是存储在外
-
mysql之group by和having用法详解
GROUP BY语法可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表. select子句中的列名必须为分组列或列函数,列函数对于group by子句定义的每个组返回一个结果. 某个员工信息表结构和数据如下: id name dept salary edlevel hiredate 1 张三 开发部 2000 3 2009-10-11 2 李四 开发部 2500 3 2009-10-01 3 王五 设计部 2600 5 2010-10-02 4 王六 设计部 2300 4
-
MySQL隐式类型转换导致索引失效的解决
目录 问题 复现 隐式转换 总结 参考 问题 在工作中发现,有一个接口只执行一条SQL查询语句,并且SQL明明使用了主键列,但是速度很慢. 在MySQL中EXPLAINN后发现,执行时并没有使用主键索引,而是进行了全表扫描. 复现 数据表DDL如下,使用 user_id 作为主键索引: CREATE TABLE `user_message` ( `user_id` varchar(50) NOT NULL COMMENT '用户ID', `msg_id` int(11) NOT NULL COM
-
Mysql row number()排序函数的用法和注意
虽然使用不多,但是也有情况是需要在mysql 里面写语句开发功能的.在sql server 使用惯了,习惯了使用row_number() 函数进行排序,但是mysql 确没有这样一个函数.然后找到了po主写的一篇 文章.通过变量赋值来查询的.(PS 我测试的版本是mysql 5.6) 先建表 CREATE TABLE `test` ( `ID` int(11) NOT NULL AUTO_INCREMENT, `Col1` varchar(50) DEFAULT NULL, `Col2` var
-
MySQL多表连接查询详解
目录 多表连接查询 内连接 左连接 右连接 子查询 总结 多表连接查询 表与表之间的连接分为内连接和外连接 内连接:仅选出两张表互相匹配的记录 外连接:既包括两张表匹配的记录,也包括不匹配的记录,同时外连接又分为左外连接(左连接)和右外连接(右连接) 内连接 首先准备两张表 学生student表 分数score表 内连接:在每个表中找出符合条件的共有记录 查询student表中的学生姓名和分数 第一种写法:只使用where select a.s_name, b.s_score from stud
-
MySQL DEFINER具体使用详解
目录 前言: 1.DEFINER简单介绍 2.一些注意事项 总结: 前言: 在 MySQL 数据库中,在创建视图及函数的时候,你有注意过 definer 选项吗?在迁移视图或函数后是否有过报错情况,这些其实都可能和 definer 有关系.本篇文章主要介绍下 MySQL 中 definer 的含义及作用. 1.DEFINER简单介绍 以视图为例,我们来看下官方给出的视图创建基础语法: CREATE [OR REPLACE] [ALGORITHM = {UNDEFINED | MERGE | TE
-
方便快捷实现springboot 后端配置多个数据源、Mysql数据库
目录 1)Test1DataSourceConfig.java 2)Test2DataSourceConfig.java 1.修改application.properties 新建 Mapper.实体类 相应的文件夹,将不同数据源的文件保存到对应的文件夹下 # test1 数据库的配置 test1.spring.datasource.driver-class-name=com.mysql.cj.jdbc.Driver test1.spring.datasource.jdbc-url=jdbc:m
-
浅谈MySQL数据查询太多会OOM吗
目录 全表扫描对server层的影响 全表扫描对InnoDB的影响 InnoDB内存管理 小结 我的主机内存只有100G,现在要全表扫描一个200G大表,会不会把DB主机的内存用光? 逻辑备份时,可不就是做整库扫描吗?若这样就会把内存吃光,逻辑备份不是早就挂了? 所以大表全表扫描,看起来应该没问题.这是为啥呢? 全表扫描对server层的影响 假设,我们现在要对一个200G的InnoDB表db1. t,执行一个全表扫描.当然,你要把扫描结果保存在客户端,会使用类似这样的命令: mysql -h$
-
MYSQL row_number()与over()函数用法详解
语法格式:row_number() over(partition by 分组列 order by 排序列 desc) row_number() over()分组排序功能: 在使用 row_number() over()函数时候,over()里头的分组以及排序的执行晚于 where .group by. order by 的执行. 例一: 表数据: create table TEST_ROW_NUMBER_OVER( id varchar(10) not null, name varchar(1
-
MySQL两种临时表的用法详解
外部临时表 通过CREATE TEMPORARY TABLE 创建的临时表,这种临时表称为外部临时表.这种临时表只对当前用户可见,当前会话结束的时候,该临时表会自动关闭.这种临时表的命名与非临时表可以同名(同名后非临时表将对当前会话不可见,直到临时表被删除). 内部临时表 内部临时表是一种特殊轻量级的临时表,用来进行性能优化.这种临时表会被MySQL自动创建并用来存储某些操作的中间结果.这些操作可能包括在优化阶段或者执行阶段.这种内部表对用户来说是不可见的,但是通过EXPLAIN或者SHOW S
-
JavaScript中eval()函数用法详解
eval() 函数计算 JavaScript 字符串,并把它作为脚本代码来执行. 如果参数是一个表达式,eval() 函数将执行表达式.如果参数是Javascript语句,eval()将执行 Javascript 语句. 语法 复制代码 代码如下: eval(string) 参数 描述 string 必需.要计算的字符串,其中含有要计算的 JavaScript 表达式或要执行的语句. eval()函数用法详解: 此函数可能使用的频率并不是太高,但是在某些情况下具有很大的作用,下面就介绍一下eva
-
Python的Lambda函数用法详解
在Python中有两种函数,一种是def定义的函数,另一种是lambda函数,也就是大家常说的匿名函数.今天我就和大家聊聊lambda函数,在Python编程中,大家习惯将其称为表达式. 1.为什么要用lambda函数? 先举一个例子:将一个列表里的每个元素都平方. 先用def来定义函数,代码如下 def sq(x): return x*x map(sq,[y for y in range(10)]) 再用lambda函数来编写代码 map(lambda x: x*x,[y for y in r
-
Python中flatten( )函数及函数用法详解
flatten()函数用法 flatten是numpy.ndarray.flatten的一个函数,即返回一个一维数组. flatten只能适用于numpy对象,即array或者mat,普通的list列表不适用!. a.flatten():a是个数组,a.flatten()就是把a降到一维,默认是按行的方向降 . a.flatten().A:a是个矩阵,降维后还是个矩阵,矩阵.A(等效于矩阵.getA())变成了数组.具体看下面的例子: 1.用于array(数组)对象 >>> from n
-
pytorch中torch.max和Tensor.view函数用法详解
torch.max() 1. torch.max()简单来说是返回一个tensor中的最大值. 例如: >>> si=torch.randn(4,5) >>> print(si) tensor([[ 1.1659, -1.5195, 0.0455, 1.7610, -0.2064], [-0.3443, 2.0483, 0.6303, 0.9475, 0.4364], [-1.5268, -1.0833, 1.6847, 0.0145, -0.2088], [-0.86
-
python isinstance函数用法详解
这篇文章主要介绍了python isinstance函数用法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 isinstance() 函数来判断一个对象是否是一个已知的类型类似 type(). isinstance() 与 type() 区别: type() 不会认为子类是一种父类类型,不考虑继承关系. isinstance() 会认为子类是一种父类类型,考虑继承关系. 如果要判断两个类型是否相同推荐使用 isinstance(). 语法
-
C++ min/max_element 函数用法详解
同样是O(n)复杂度,但是经过不严谨 测试,使用库函数的速度远超for循环的遍历找最值 /* param begin : 序列起始地址(迭代器) param end : 序列结束地址(迭代器) return : 序列中最小元素地址(迭代器) */ min_element(begin, end); /* param begin : 序列起始地址(迭代器) param end : 序列结束地址(迭代器) return : 序列中最大元素地址(迭代器) */ max_element(begin, en
-
python yield和Generator函数用法详解
这篇文章主要介绍了python yield和Generator函数用法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 首先我们从一个小程序导入,各定一个list,找出其中的素数,我们会这样写 import math def is_Prims(number): if number == 2: return True //除2以外的所有偶数都不是素数 elif number % 2 == 0: return False //如果一个数能被除1和
-
pandas dataframe 中的explode函数用法详解
在使用 pandas 进行数据分析的过程中,我们常常会遇到将一行数据展开成多行的需求,多么希望能有一个类似于 hive sql 中的 explode 函数. 这个函数如下: Code # !/usr/bin/env python # -*- coding:utf-8 -*- # create on 18/4/13 import pandas as pd def dataframe_explode(dataframe, fieldname): temp_fieldname = fieldname