jsoup如何爬取图片到本地
因为项目需求,需要车辆品牌信息和车系信息,昨天用一天时间研究了jsoup爬取网站信息。项目是用maven+spring+springmvc+mybatis写的。
这个是需要爬取网站的地址 https://car.autohome.com.cn/zhaoche/pinpai/
1.首先在pom.xml中添加依赖
因为需要把图片保存到本地所以又添加了commons-net包
<!-- https://mvnrepository.com/artifact/org.jsoup/jsoup -->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.10.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/commons-net/commons-net -->
<dependency>
<groupId>commons-net</groupId>
<artifactId>commons-net</artifactId>
<version>3.3</version>
</dependency>
2.爬虫代码的实现
@Controller
@RequestMapping("/car/")
public class CarController {
//图片保存路径
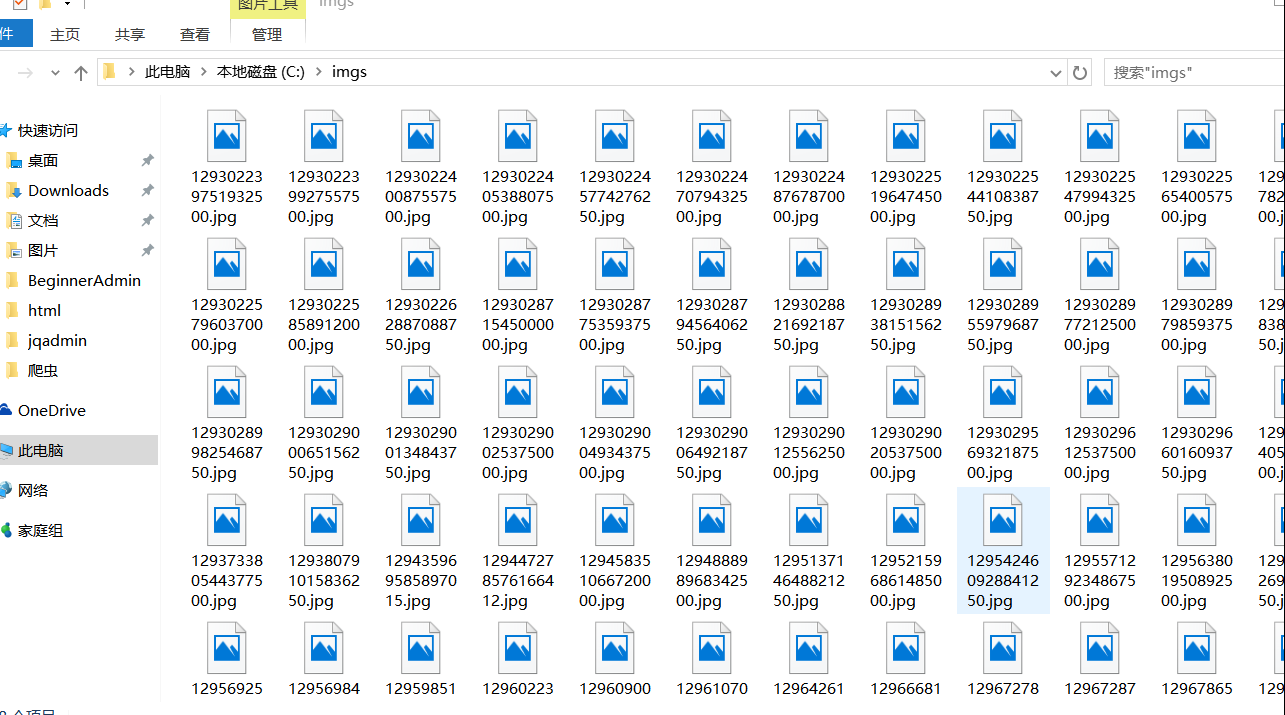
private static final String saveImgPath="C://imgs";
/**
* @Title: insert 品牌名称 和图片爬取和添加
* @Description:
* @param @throws IOException
* @return void
* @throws
* @date 2018年1月29日 下午4:42:57
*/
@RequestMapping("add")
public void insert() throws IOException {
//定义想要爬取数据的地址
String url = "https://car.autohome.com.cn/zhaoche/pinpai/";
//获取网页文本
Document doc = Jsoup.connect(url).get();
//根据类名获取文本内容
Elements elementsByClass = doc.getElementsByClass("uibox-con");
//遍历类的集合
for (Element element : elementsByClass) {
//获取类的子标签数量
int childNodeSize_1 = element.childNodeSize();
//循环获取子标签内的内容
for (int i = 0; i < childNodeSize_1; i++) {
//获取车标图片地址
String tupian = element.child(i).child(0).child(0).child(0).child(0).attr("src");
//获取品牌名称
String pinpai = element.child(i).child(0).child(1).text();
//输出获取内容看是否正确
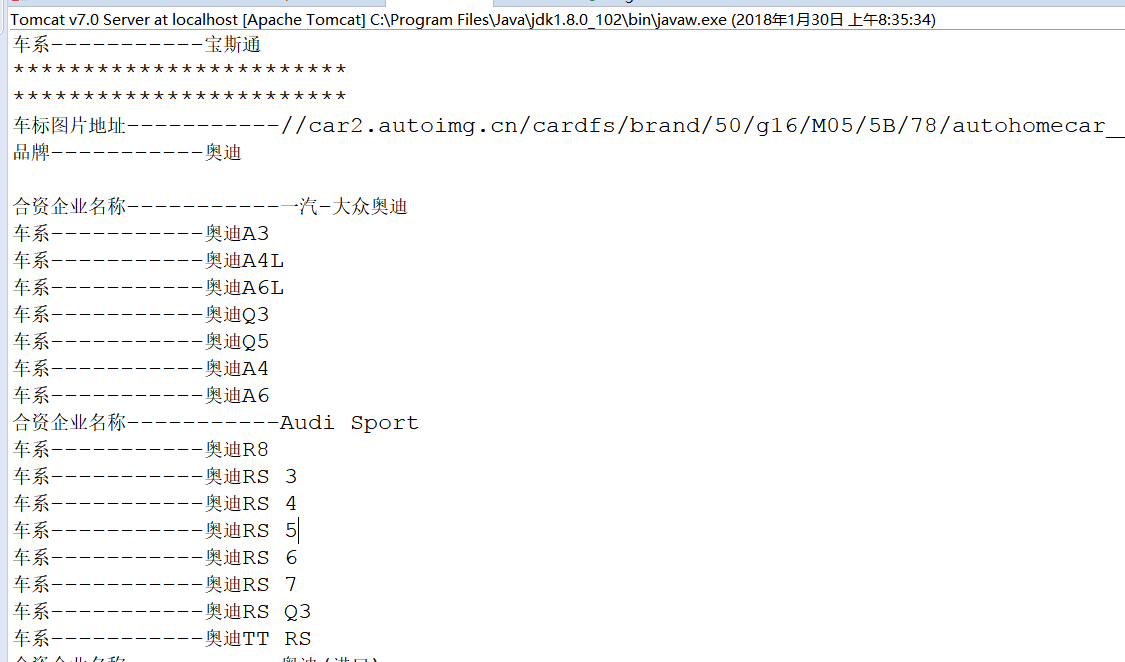
System.out.println("车标图片地址-----------" + tupian);
System.out.println("品牌-----------" + pinpai);
System.out.println();
//把车标图片保存到本地
String tupian_1 = "http:"+tupian;
//连接url
URL url1 = new URL(tupian_1);
URLConnection uri=url1.openConnection();
//获取数据流
InputStream is=uri.getInputStream();
//获取后缀名
String imageName = tupian.substring(tupian.lastIndexOf("/") + 1,tupian.length());
//写入数据流
OutputStream os = new FileOutputStream(new File(saveImgPath, imageName));
byte[] buf = new byte[1024];
int p=0;
while((p=is.read(buf))!=-1){
os.write(buf, 0, p);
}
/**
* 因为每个品牌下有多个合资工厂
* 比如一汽大众和上海大众还有进口大众
* 所有需要循环获取合资工厂名称和旗下
* 车系
*/
//获取车系数量
int childNodeSize_2 = element.child(i).child(1).child(0).childNodeSize();
/**
* 获取标签下子标签数量
* 如果等于1则没有其他合资工厂
*/
int childNodeSize_3 = element.child(i).child(1).childNodeSize();
if(childNodeSize_3==1){
//循环获取车系信息
for (int j = 0; j < childNodeSize_2; j++) {
String chexi = element.child(i).child(1).child(0).child(j).child(0).child(0).text();
System.out.println("车系-----------" + chexi);
}
}else{
/**
* 如果childNodeSize_3大于1
* 则有多个合资工厂
*/
//分别获取各个合资工厂旗下车系
for (int j = 0; j < childNodeSize_3; j++) {
int childNodeSize_4 = element.child(i).child(1).child(j).childNodeSize();
/**
* 如果j是单数则是合资工厂名称
* 否则是车系信息
*/
int k = j%2;
if(k==0){
//获取合资工厂信息
String hezipinpai = element.child(i).child(1).child(j).child(0).text();
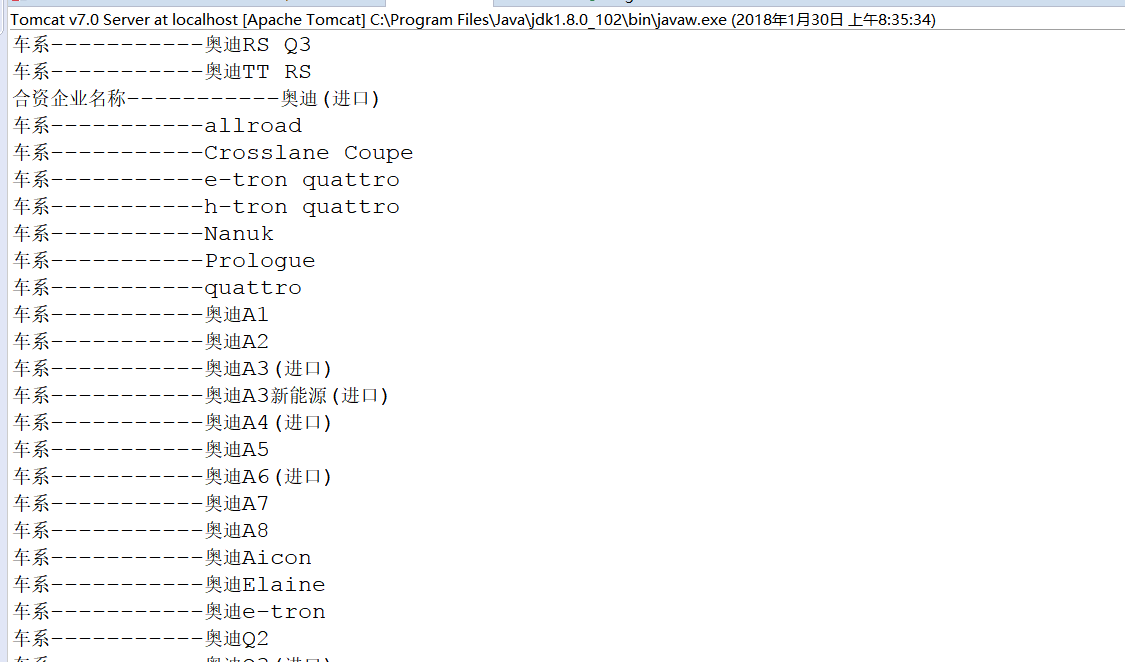
System.out.println("合资企业名称-----------" + hezipinpai);
}else{
//int childNodeSize_5 = element.child(i).child(1).child(0).childNodeSize();
//循环获取合资工厂车系信息
for(int l = 0; l < childNodeSize_4; l++){
String chexi = element.child(i).child(1).child(j).child(l).child(0).child(0).text();
System.out.println("车系-----------" + chexi);
}
}
}
}
System.out.println("************************");
System.out.println("************************");
}
}
}
}
3.运行结果
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
详解Java两种方式简单实现:爬取网页并且保存
对于网络,我一直处于好奇的态度.以前一直想着写个爬虫,但是一拖再拖,懒得实现,感觉这是一个很麻烦的事情,出现个小错误,就要调试很多时间,太浪费时间. 后来一想,既然早早给自己下了保证,就先实现它吧,从简单开始,慢慢增加功能,有时间就实现一个,并且随时优化代码. 下面是我简单实现爬取指定网页,并且保存的简单实现,其实有几种方式可以实现,这里慢慢添加该功能的几种实现方式. UrlConnection爬取实现 package html; import java.io.BufferedReader; i
-

java实现爬取知乎用户基本信息
本文实例为大家分享了一个基于JAVA的知乎爬虫,抓取知乎用户基本信息,基于HttpClient 4.5,供大家参考,具体内容如下 详细内容: 抓取90W+用户信息(基本上活跃的用户都在里面) 大致思路: 1.首先模拟登录知乎,登录成功后将Cookie序列化到磁盘,不用以后每次都登录(如果不模拟登录,可以直接从浏览器塞入Cookie也是可以的). 2.创建两个线程池和一个Storage.一个抓取网页线程池,负责执行request请求,并返回网页内容,存到Storage中.另一个是解析网页线程池,负
-
Java爬虫实现爬取京东上的手机搜索页面 HttpCliient+Jsoup
1.需求及配置 需求:爬取京东手机搜索页面的信息,记录各手机的名称,价格,评论数等,形成一个可用于实际分析的数据表格. 使用Maven项目,log4j记录日志,日志仅导出到控制台. Maven依赖如下(pom.xml) <dependencies> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId>
-
jsoup如何爬取图片到本地
因为项目需求,需要车辆品牌信息和车系信息,昨天用一天时间研究了jsoup爬取网站信息.项目是用maven+spring+springmvc+mybatis写的. jsoup开发指南地址 这个是需要爬取网站的地址 https://car.autohome.com.cn/zhaoche/pinpai/ 1.首先在pom.xml中添加依赖 因为需要把图片保存到本地所以又添加了commons-net包 <!-- https://mvnrepository.com/artifact/org.jsoup/j
-
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 基本上按照文档的流程走一遍就基本会用了. Step1: 在开始爬取之前,必须创建一个新的Scrapy项目. 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMe
-
python3 爬取图片的实例代码
具体代码如下所示: #coding=utf8 from urllib import request import re import urllib,os url='http://tieba.baidu.com/p/3840085725' def get_image(url): #获取页面源码 page = urllib.request.urlopen(url) html = page.read() #解码,否则报错 html = html.decode('utf8') #正则匹配获取()的内容
-
java+selenium爬取图片签名的方法
本文实例为大家分享了java+selenium爬取图片签名的具体实现方法,供大家参考,具体内容如下 学习记录: 1.注意 对应的版本非常重要,使用selenium得下载与游览器版本相对应的插件,有火狐和谷歌我用的谷歌,贴下谷歌driver的插件 查看谷歌版本: 2.插件存放路径 3.获取签名图片存放路径 4.Controller代码如下 @ResponseBody @RequestMapping(value = "signatureGenerationv") public String
-
Python3直接爬取图片URL并保存示例
有时候我们会需要从网络上爬取一些图片,来满足我们形形色色直至不可描述的需求. 一个典型的简单爬虫项目步骤包括两步:获取网页地址和提取保存数据. 这里是一个简单的从图片url收集图片的例子,可以成为一个小小的开始. 获取地址 这些图片的URL可能是连续变化的,如从001递增到099,这种情况可以在程序中将共同的前面部分截取,再在最后递增并字符串化后循环即可. 抑或是它们的URL都保存在某个文件中,这时可以读取到列表中: def getUrls(path): urls = [] with open(
-
python根据用户需求输入想爬取的内容及页数爬取图片方法详解
本次小编向大家介绍的是根据用户的需求输入想爬取的内容及页数. 主要步骤: 1.提示用户输入爬取的内容及页码. 2.根据用户输入,获取网址列表. 3.模拟浏览器向服务器发送请求,获取响应. 4.利用xpath方法找到图片的标签. 5.保存数据. 代码用面向过程的形式编写的. 关键字:requests库,xpath,面向过程 现在就来讲解代码书写的过程: 1.导入模块 import parsel # 该模块主要用来将请求后的字符串格式解析成re,xpath,css进行内容的匹配 import req
-
使用scrapy ImagesPipeline爬取图片资源的示例代码
这是一个使用scrapy的ImagesPipeline爬取下载图片的示例,生成的图片保存在爬虫的full文件夹里. scrapy startproject DoubanImgs cd DoubanImgs scrapy genspider download_douban douban.com vim spiders/download_douban.py # coding=utf-8 from scrapy.spiders import Spider import re from scrapy
-
python爬虫爬取图片的简单代码
Python是很好的爬虫工具不用再说了,它可以满足我们爬取网络内容的需求,那最简单的爬取网络上的图片,可以通过很简单的方法实现.只需导入正则表达式模块,并利用spider原理通过使用定义函数的方法可以轻松的实现爬取图片的需求. 1.spider原理 spider就是定义爬取的动作及分析网站的地方. 以初始的URL**初始化Request**,并设置回调函数. 当该request**下载完毕并返回时,将生成**response ,并作为参数传给该回调函数. 2.实现python爬虫爬取图片 第一步
-
Python爬虫之教你利用Scrapy爬取图片
Scrapy下载图片项目介绍 Scrapy是一个适用爬取网站数据.提取结构性数据的应用程序框架,它可以通过定制化的修改来满足不同的爬虫需求. 使用Scrapy下载图片 项目创建 首先在终端创建项目 # win4000为项目名 $ scrapy startproject win4000 该命令将创建下述项目目录. 项目预览 查看项目目录 win4000 win4000 spiders __init__.py __init__.py items.py middlewares.py pipelines
-
Python自动爬取图片并保存实例代码
目录 一.准备工作 二.代码实现 三.总结 一.准备工作 用python来实现对百度图片的爬取并保存,以情绪图片为例,百度搜索可得到下图所示 f12打开源码 在此处可以看到这次我们要爬取的图片的基本信息是在img - scr中 二.代码实现 这次的爬取主要用了如下的第三方库 import re import time import requests from bs4 import BeautifulSoup import os 简单构思可以分为三个小部分 1.获取网页内容 2.解析网页 3.保存