mysql 中 replace into 与 insert into on duplicate key update 的用法和不同点实例分析
本文实例讲述了mysql 中 replace into 与 insert into on duplicate key update 的用法和不同点。分享给大家供大家参考,具体如下:
replace into和insert into on duplicate key update都是为了解决我们平时的一个问题
就是如果数据库中存在了该条记录,就更新记录中的数据,没有,则添加记录。
我们创建一个测试表test
CREATE TABLE `test` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID', `name` varchar(32) DEFAULT '' COMMENT '姓名', `addr` varchar(256) DEFAULT '' COMMENT '地址', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
向该表中插入一些数据
INSERT INTO test VALUES (NULL, 'a', 'aaa'), (NULL, 'b', 'bbb'), (NULL, 'c', 'ccc'), (NULL, 'd', 'ddd');
影响行数4,结果如下:

我们运行如下语句:
REPLACE INTO test VALUES(NULL, 'e', 'eee');
结果显示,影响行数1条,记录被插入成功了

注意上面的语句,我们并没有填写主键ID。
然后我们再执行下面的语句:
REPLACE INTO test VALUES(1, 'aa', 'aaaa');
结果显示,影响行数2条,ID为1的记录被更新成功了

为什么会出现这种情况,原因就是replace into会首先尝试先往表里面插入记录,因为我们的ID是主键,不可重复,显然这条记录是无法插入成功的,然后replace into会把这条已存在的记录删掉,然后再插入,所以会显示影响行数是2。
我们再运行下面这条语句:
REPLACE INTO test(id,name) VALUES(1, 'aaa');
这里我们只指定id,name字段,我们来看看replace into后addr字段内容是否还存在
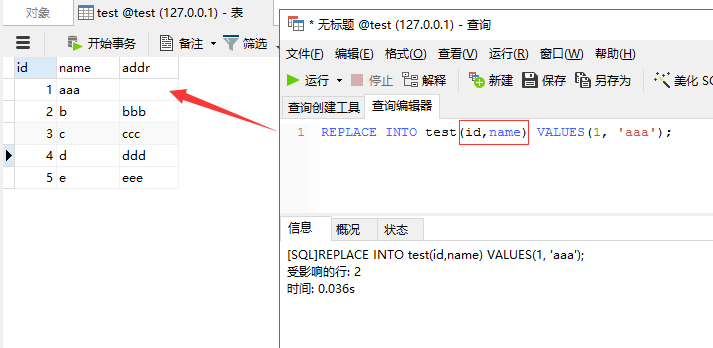
显然addr字段内容没有了,跟我们上面的分析是一致的,reaplce into先删除了id为1的记录,然后再插入记录,但我们并没有指定addr的值,所以会如上图所示那样。
但是有些时候我们的需求是,如果记录存在则更新指定字段的数据,原有字段数据仍保留,而不是上面所示的,addr字段数据没有了。
这里就需要用到insert into on duplicate key update
执行如下语句:
INSERT INTO test (id, name) VALUES(2, 'bb') ON DUPLICATE KEY UPDATE name = VALUES(name);
VALUES(字段名)表示获取当前语句insert的列值,VALUES(name)表示的就是'bb'
结果显示,影响行数2条
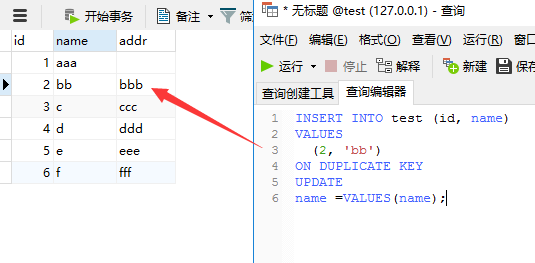
如上图所示,addr字段的值被保留了。
insert into on duplicate key update语句的做法是先插入记录,如果不成功,则更新记录,但是为什么影响的行数是2?
我们重新建一张表test2
CREATE TABLE `test2` ( `id` int(11) unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID', `sn` varchar(32) DEFAULT '' COMMENT '唯一键', `name` varchar(32) DEFAULT '' COMMENT '姓名', `addr` varchar(256) DEFAULT '' COMMENT '地址', PRIMARY KEY (`id`), UNIQUE KEY `sn` (`sn`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
往里面插入点数据
INSERT INTO test2 VALUES (NULL, '01', 'a', 'aaa'), (NULL, '02', 'b', 'bbb'), (NULL, '03', 'c', 'ccc'), (NULL, '04', 'd', 'ddd');
我们运行如下语句:
INSERT INTO test2 (sn, name, addr)
VALUES
('02', 'bb', 'bbbb')
ON DUPLICATE KEY
UPDATE
name = VALUES(name),
addr = VALUES(addr);
结果如下:

每运行一次上面的语句,虽然影响行数为0,但表test2的自增字段就加1。

显然如果insert into on duplicate key update语句仅仅只是在原记录基础上进行更新操作的话,自增字段是不会自动加1的,说明它也进行了记录删除操作。
先插入记录,如果不成功,则删除原记录,但保留了除update语句后字段的值,然后把保留的值与需要更新的值合并,然后插入一条新记录。
总结:
replace into 与 insert into on duplicate key update都是先尝试插入记录,如果不成功,则删除记录,replace into不保留原记录的值,而insert into on duplicate key update保留。然后插入一条新记录。
更多关于MySQL相关内容感兴趣的读者可查看本站专题:《MySQL查询技巧大全》、《MySQL常用函数大汇总》、《MySQL日志操作技巧大全》、《MySQL事务操作技巧汇总》、《MySQL存储过程技巧大全》及《MySQL数据库锁相关技巧汇总》
希望本文所述对大家MySQL数据库计有所帮助。
相关推荐
-
MySQL中REPLACE INTO和INSERT INTO的区别分析
注意,除非表有一个PRIMARY KEY或UNIQUE索引,否则,使用一个REPLACE语句没有意义.该语句会与INSERT相同,因为没有索引被用于确定是否新行复制了其它的行. [separator] 所有列的值均取自在REPLACE语句中被指定的值.所有缺失的列被设置为各自的默认值,这和INSERT一样.您不能从当前行中引用值,也不能在新行中使用值.如果您使用一个例如"SET col_name = col_name + 1"的赋值,则对位于右侧的列名称的引用会被作为DEFAULT(c
-
MySQL Replace INTO的使用
REPLACE的运行与INSERT很相像.只有一点除外,如果表中的一个旧记录与一个用于PRIMARY KEY或一个UNIQUE索引的新记录具有相同的值,则在新记录被插入之前,旧记录被删除.请参见13.2.4节,"INSERT语法". 注意,除非表有一个PRIMARY KEY或UNIQUE索引,否则,使用一个REPLACE语句没有意义.该语句会与INSERT相同,因为没有索引被用于确定是否新行复制了其它的行. 所有列的值均取自在REPLACE语句中被指定的值.所有缺失的列被设置为各自的默
-
正确使用MySQL INSERT INTO语句
以下的文章主要介绍的是MySQL INSERT INTO语句的实际用法以及MySQL INSERT INTO语句中的相关语句的介绍,MySQL INSERT INTO语句在实际应用中是经常使用到的语句,所以对其相关的内容还是多多掌握为好. INSERT [LOW_PRIORITY | DELAYED] [IGNORE] [INTO] tbl_name [(col_name,...)] VALUES (expression,...),(...),... MySQLINSERT INTO SELEC
-
MySQL中replace into语句的用法详解
在向表中插入数据的时候,经常遇到这样的情况: 1.首先判断数据是否存在: 2.如果不存在,则插入: 3.如果存在,则更新. 在 SQL Server 中可以这样写: 复制代码 代码如下: if not exists (select 1 from table where id = 1) insert into table(id, update_time) values(1, getdate()) else update table set update_time = getdate() whe
-
mysql 操作总结 INSERT和REPLACE
言外之意,就是对数据进行修改.在标准的SQL中有3个语句,它们是INSERT.UPDATE以及DELETE.在MySQL中又多了一个REPLACE语句,因此,本文以MySQL为背景来讨论如何使有SQL中的更新语句. 一.INSERT和REPLACE INSERT和REPLACE语句的功能都是向表中插入新的数据.这两条语句的语法类似.它们的主要区别是如何处理重复的数据. 1. INSERT的一般用法 MySQL中的INSERT语句和标准的INSERT不太一样,在标准的SQL语句中,一次插入一条记录
-
MySql中使用INSERT INTO语句更新多条数据的例子
我们知道当插入多条数据的时候insert支持多条语句: 复制代码 代码如下: INSERT INTO t_member (id, name, email) VALUES (1, 'nick', 'nick@126.com'), (4, 'angel','angel@163.com'), (7, 'brank','ba198@126.com'); 但是对于更新记录,由于update语法不支持一次更新多条记录,只能一条一条执行: 复制代码 代码如下: UPDATE t_mem
-
MySQL数据库INSERT、UPDATE、DELETE以及REPLACE语句的用法详解
MySQL数据库insert和update语句引:用于操作数据库的SQL一般分为两种,一种是查询语句,也就是我们所说的SELECT语句,另外一种就是更新语句,也叫做数据操作语句.言外之意,就是对数据进行修改.在标准的SQL中有3个语句,它们是INSERT.UPDATE以及DELETE. 用于操作数据库的SQL一般分为两种,一种是查询语句,也就是我们所说的SELECT语句,另外一种就是更新语句,也叫做数据操作语句.言外之意,就 是对数据进行修改.在标准的SQL中有3个语句,它们是INSERT.UP
-
解析MySQL中INSERT INTO SELECT的使用
1. 语法介绍有三张表a.b.c,现在需要从表b和表c中分别查几个字段的值插入到表a中对应的字段.对于这种情况,可以使用如下的语句来实现:INSERT INTO db1_name (field1,field2) SELECT field1,field2 FROM db2_name 上面的语句比较适合两个表的数据互插,如果多个表就不适应了.对于多个表,可以先将需要查询的字段JOIN起来,然后组成一个视图后再SELECT FROM就可以了: INSERT INTO a (field1,field2)
-
Mysql中replace与replace into的用法讲解
Mysql replace与replace into都是经常会用到的功能:replace其实是做了一次update操作,而不是先delete再insert:而replace into其实与insert into很相像,但对于replace into,假如表中的一个旧记录与一个用于PRIMARY KEY或一个UNIQUE索引的新记录具有相同的值,则在新记录被插入之前,旧记录被删除. replace是mysql 里面处理字符串比较常用的函数,可以替换字符串中的内容.类似的处理字符串的还有trim截取
-

MySQL的Replace into 与Insert into on duplicate key update真正的不同之处
看下面的例子吧: 1 Replace into ...1.1 录入原始数据mysql> use test;Database changedmysql> mysql> CREATE TABLE t1 SELECT 1 AS a, 'c3' AS b, 'c2' AS c;ALTER TABLE t1 CHANGE a a INT PRIMARY KEY AUTO_INCREMENT ;Query OK, 1 row affected (0.03 sec)Records: 1 Duplic