解决kafka消息堆积及分区不均匀的问题
目录
- kafka消息堆积及分区不均匀的解决
- 1、先在kafka消息中创建
- 2、添加配置文件application.properties
- 3、创建kafka工厂
- 4、展示kafka消费者
- kafka出现若干分区不消费的现象
- 定位过程
- 验证
- 解决方法
kafka消息堆积及分区不均匀的解决
我在环境中发现代码里面的kafka有所延迟,查看kafka消息发现堆积严重,经过检查发现是kafka消息分区不均匀造成的,消费速度过慢。这里由自己在虚拟机上演示相关问题,给大家提供相应问题的参考思路。
这篇文章有点遗憾并没重现分区不均衡的样例和Warning: Consumer group ‘testGroup1' is rebalancing. 这里仅将正确的方式展示,等后续重现了在进行补充。
主要有两个要点:
- 1、一个消费者组只消费一个topic.
- 2、factory.setConcurrency(concurrency);这里设置监听并发数为 部署单元节点*concurrency=分区数量
1、先在kafka消息中创建
对应分区数目的topic(testTopic2,testTopic3)testTopic1由代码创建
./kafka-topics.sh --create --zookeeper 192.168.25.128:2181 --replication-factor 1 --partitions 2 --topic testTopic2
2、添加配置文件application.properties
kafka.test.topic1=testTopic1 kafka.test.topic2=testTopic2 kafka.test.topic3=testTopic3 kafka.broker=192.168.25.128:9092 auto.commit.interval.time=60000 #kafka.test.group=customer-test kafka.test.group1=testGroup1 kafka.test.group2=testGroup2 kafka.test.group3=testGroup3 kafka.offset=earliest kafka.auto.commit=false session.timeout.time=10000 kafka.concurrency=2
3、创建kafka工厂
package com.yin.customer.config;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.AbstractMessageListenerContainer;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer;
import org.springframework.kafka.listener.ContainerProperties;
import org.springframework.stereotype.Component;
import java.util.HashMap;
import java.util.Map;
/**
* @author yin
* @Date 2019/11/24 15:54
* @Method
*/
@Configuration
@Component
public class KafkaConfig {
@Value("${kafka.broker}")
private String broker;
@Value("${kafka.auto.commit}")
private String autoCommit;
// @Value("${kafka.test.group}")
//private String testGroup;
@Value("${session.timeout.time}")
private String sessionOutTime;
@Value("${auto.commit.interval.time}")
private String autoCommitTime;
@Value("${kafka.offset}")
private String offset;
@Value("${kafka.concurrency}")
private Integer concurrency;
@Bean
KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory(){
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
//监听设置两个个分区
factory.setConcurrency(concurrency);
//打开批量拉取数据
factory.setBatchListener(true);
//这里设置的是心跳时间也是拉的时间,也就说每间隔max.poll.interval.ms我们就调用一次poll,kafka默认是300s,心跳只能在poll的时候发出,如果连续两次poll的时候超过
//max.poll.interval.ms 值就会导致rebalance
//心跳导致GroupCoordinator以为本地consumer节点挂掉了,引发了partition在consumerGroup里的rebalance。
// 当rebalance后,之前该consumer拥有的分区和offset信息就失效了,同时导致不断的报auto offset commit failed。
factory.getContainerProperties().setPollTimeout(3000);
factory.getContainerProperties().setAckMode(ContainerProperties.AckMode.MANUAL_IMMEDIATE);
return factory;
}
private ConsumerFactory<String,String> consumerFactory() {
return new DefaultKafkaConsumerFactory<String, String>(consumerConfigs());
}
@Bean
public Map<String, Object> consumerConfigs() {
Map<String, Object> propsMap = new HashMap<>();
//kafka的地址
propsMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, broker);
//是否自动提交 Offset
propsMap.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, autoCommit);
// enable.auto.commit 设置成 false,那么 auto.commit.interval.ms 也就不被再考虑
//默认5秒钟,一个 Consumer 将会提交它的 Offset 给 Kafka
propsMap.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 5000);
//这个值必须设置在broker configuration中的group.min.session.timeout.ms 与 group.max.session.timeout.ms之间。
//zookeeper.session.timeout.ms 默认值:6000
//ZooKeeper的session的超时时间,如果在这段时间内没有收到ZK的心跳,则会被认为该Kafka server挂掉了。
// 如果把这个值设置得过低可能被误认为挂掉,如果设置得过高,如果真的挂了,则需要很长时间才能被server得知。
propsMap.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, sessionOutTime);
propsMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
propsMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//组与组间的消费者是没有关系的。
//topic中已有分组消费数据,新建其他分组ID的消费者时,之前分组提交的offset对新建的分组消费不起作用。
//propsMap.put(ConsumerConfig.GROUP_ID_CONFIG, testGroup);
//当创建一个新分组的消费者时,auto.offset.reset值为latest时,
// 表示消费新的数据(从consumer创建开始,后生产的数据),之前产生的数据不消费。
// https://blog.csdn.net/u012129558/article/details/80427016
//earliest 当分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费。
// latest 当分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据。
propsMap.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, offset);
//不是指每次都拉50条数据,而是一次最多拉50条数据()
propsMap.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 5);
return propsMap;
}
}
4、展示kafka消费者
@Component
public class KafkaConsumer {
private static final Logger logger = LoggerFactory.getLogger(KafkaConsumer.class);
@KafkaListener(topics = "${kafka.test.topic1}",groupId = "${kafka.test.group1}",containerFactory = "kafkaListenerContainerFactory")
public void listenPartition1(List<ConsumerRecord<?, ?>> records,Acknowledgment ack) {
logger.info("testTopic1 recevice a message size :{}" , records.size());
try {
for (ConsumerRecord<?, ?> record : records) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
logger.info("received:{} " , record);
if (kafkaMessage.isPresent()) {
Object message = record.value();
String topic = record.topic();
Thread.sleep(300);
logger.info("p1 topic is:{} received message={}",topic, message);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
ack.acknowledge();
}
}
@KafkaListener(topics = "${kafka.test.topic2}",groupId = "${kafka.test.group2}",containerFactory = "kafkaListenerContainerFactory")
public void listenPartition2(List<ConsumerRecord<?, ?>> records,Acknowledgment ack) {
logger.info("testTopic2 recevice a message size :{}" , records.size());
try {
for (ConsumerRecord<?, ?> record : records) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
logger.info("received:{} " , record);
if (kafkaMessage.isPresent()) {
Object message = record.value();
String topic = record.topic();
Thread.sleep(300);
logger.info("p2 topic :{},received message={}",topic, message);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
ack.acknowledge();
}
}
@KafkaListener(topics = "${kafka.test.topic3}",groupId = "${kafka.test.group3}",containerFactory = "kafkaListenerContainerFactory")
public void listenPartition3(List<ConsumerRecord<?, ?>> records, Acknowledgment ack) {
logger.info("testTopic3 recevice a message size :{}" , records.size());
try {
for (ConsumerRecord<?, ?> record : records) {
Optional<?> kafkaMessage = Optional.ofNullable(record.value());
logger.info("received:{} " , record);
if (kafkaMessage.isPresent()) {
Object message = record.value();
String topic = record.topic();
logger.info("p3 topic :{},received message={}",topic, message);
Thread.sleep(300);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
ack.acknowledge();
}
}
}
查看分区消费情况:
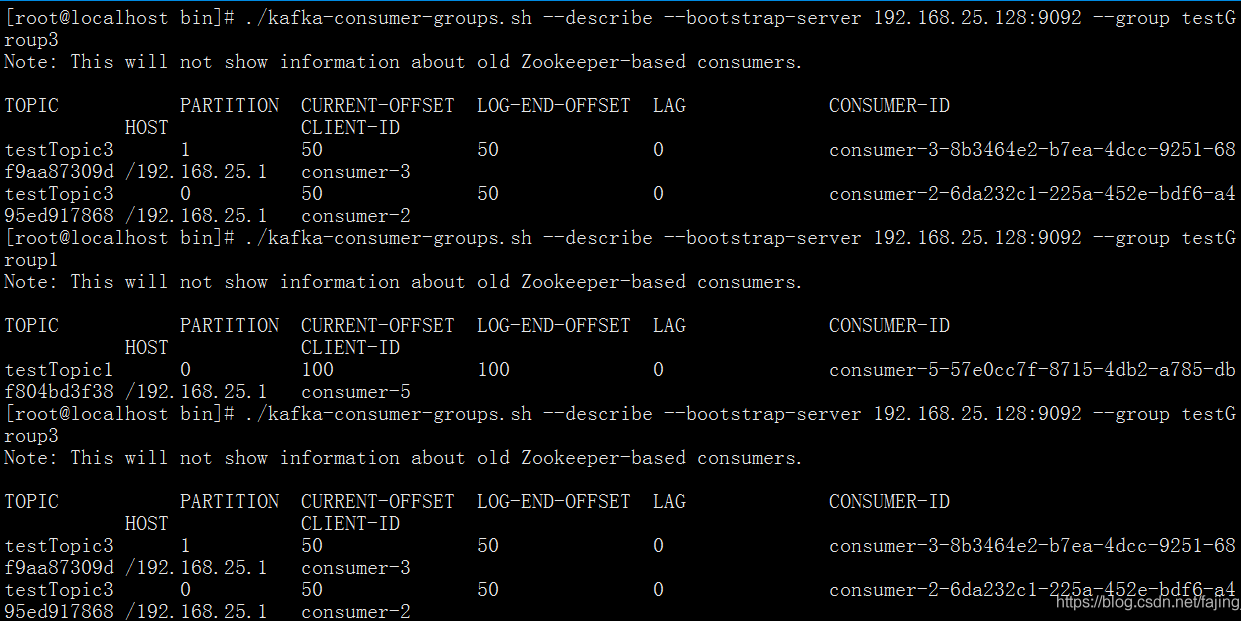
kafka出现若干分区不消费的现象
近日,有用户反馈kafka有topic出现某个消费组消费的时候,有几个分区一直不消费消息,消息一直积压(图1)。除了一直积压外,还有一个现象就是消费组一直在重均衡,大约每5分钟就会重均衡一次。具体表现为消费分区的owner一直在改变(图2)。
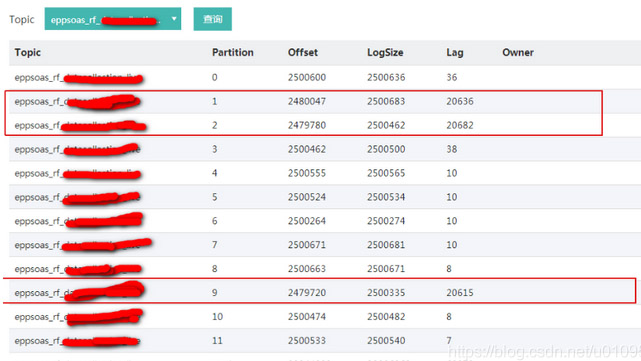
(图1)
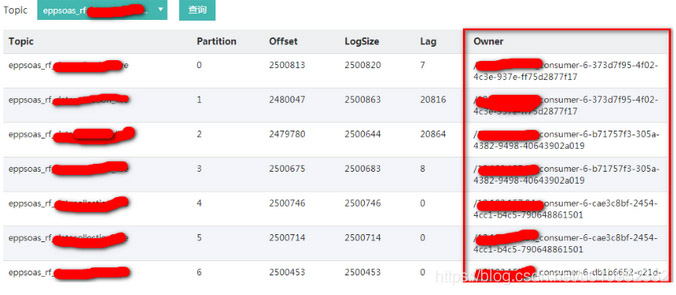
(图2)
定位过程
业务侧没有报错,同时kafka服务端日志也一切正常,同事先将消费组的机器滚动重启,仍然还是那几个分区没有消费,之后将这几个不消费的分区迁移至别的broker上,依然没有消费。
还有一个奇怪的地方,就是每次重均衡后,不消费的那几个分区的消费owner所在机器的网络都有流量变化。按理说不消费应该就是拉取不到分区不会有流量的。于是让运维去拉了下不消费的consumer的jstack日志。一看果然发现了问题所在。
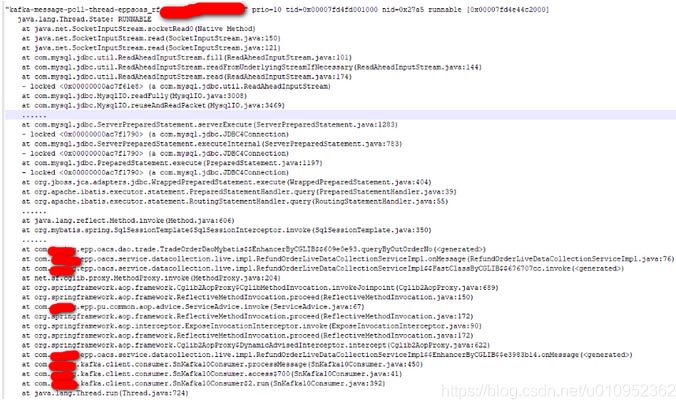
从堆栈看,consumer已经拉取到消息,然后就一直卡在处理消息的业务逻辑上。这说明kafka是没有问题的,用户的业务逻辑有问题。
consumer在拉取完一批消息后,就一直在处理这批消息,但是这批消息中有若干条消息无法处理,而业务又没有超时操作或者异常处理导致进程一直处于消费中,无法去poll下一批数据。
又由于业务采用的是autocommit的offset提交方式,而根据源码可知,consumer只有在下一次poll中才会自动提交上次poll的offset,所以业务一直在拉取同一批消息而无法更新offset。反映的现象就是该consumer对应的分区的offset一直没有变,所以有积压的现象。
至于为什么会一直在重均衡消费组的原因也很明了了,就是因为有消费者一直卡在处理消息的业务逻辑上,超过了max.poll.interval.ms(默认5min),消费组就会将该消费者踢出消费组,从而发生重均衡。
验证
让业务方去查证业务日志,验证了积压的这几个分区,总是在循环的拉取同一批消息。
解决方法
临时解决方法就是跳过有问题的消息,将offset重置到有问题的消息之后。本质上还是要业务侧修改业务逻辑,增加超时或者异常处理机制,最好不要采用自动提交offset的方式,可以手动管理。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Kafka多节点分布式集群搭建实现过程详解
上一篇分享了单节点伪分布式集群搭建方法,本篇来分享一下多节点分布式集群搭建方法.多节点分布式集群结构如下图所示: 为了方便查阅,本篇将和上一篇一样从零开始一步一步进行集群搭建. 一.安装Jdk 具体安装步骤可参考linux安装jdk. 二.安装与配置zookeeper 下载地址:https://www-us.apache.org/dist/zookeeper/stable/ 下载二进制压缩包zookeeper-3.4.14.tar.gz,然后上传到linux服务器指定目录下,本次上传目录为/so
-

消息队列-kafka消费异常问题
目录 概述 重试一定次数(消息丢失) 加入到死讯队列(消息不丢失) 总结 概述 在kafka中,或者是说在任何消息队列中都有个消费顺序的问题.为了保证一个队列顺序消费,当当中一个消息消费异常时,必将影响后续队列消息的消费,这样业务岂不是卡住了.比如笔者举个最简单的例子:我发送1-100的消息,在我的处理逻辑当中 msg%5==0我就进行 int i=1/0操作,这必将抛异常,一直阻塞在msg=5上,后面6-100无法消费.下面笔者给出解决方案. 重试一定次数(消息丢失) @KafkaHandle
-
使用kafka如何选择分区数及kafka性能测试
kafka选择分区数及kafka性能测试 1.简言 如何选择合适的分区,这是我们经常面临的问题,不过针对这个问题,在网上并没有搜到固定的答案.因此,今天在这里主要通过性能测试的工具来告诉如何选择相对应的kafka分区. 2.性能测试工具 kafka本身提供了比较的性能测试工具,我们可以使用它来测试适用于我们机器的kafka分区. ① 生产者性能测试 分别创建三个topic,副本数设置为1. bin/kafka-topics.sh --zookeeper zk --create --rep
-
spring boot整合kafka过程解析
这篇文章主要介绍了spring boot整合kafka过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.启动kafka 启动kafka之前一定要启动zookeeper,因为要使用kafka必须要使用zookeeper. windows环境下启动,直接使用kafka自带的zookeeper: E:\kafka_2.12-2.4.0\bin\windows zookeeper-server-start.bat ..\..\config\z
-
解决kafka消息堆积及分区不均匀的问题
目录 kafka消息堆积及分区不均匀的解决 1.先在kafka消息中创建 2.添加配置文件application.properties 3.创建kafka工厂 4.展示kafka消费者 kafka出现若干分区不消费的现象 定位过程 验证 解决方法 kafka消息堆积及分区不均匀的解决 我在环境中发现代码里面的kafka有所延迟,查看kafka消息发现堆积严重,经过检查发现是kafka消息分区不均匀造成的,消费速度过慢.这里由自己在虚拟机上演示相关问题,给大家提供相应问题的参考思路. 这篇文章有点
-
大数据Kafka:消息队列和Kafka基本介绍
目录 一.什么是消息队列 二.消息队列的应用场景 异步处理 应用耦合 限流削峰 消息驱动系统 三.消息队列的两种方式 点对点模式 发布/订阅模式 四.常见的消息队列的产品 1) RabbitMQ 2) activeMQ: 3) RocketMQ 4) kafka 五.Kafka的基本介绍 一.什么是消息队列 消息队列,英文名:Message Queue,经常缩写为MQ.从字面上来理解,消息队列是一种用来存储消息的队列 .来看一下下面的代码 上述代码,创建了一个队列,先往队列中添加了一个消息,然后
-
关于Kafka消息队列原理的总结
目录 Kafka消息队列原理 Kafka的逻辑数据模型 Kafka的分发策略 Kafka的物理存储模型和查找数据的设计 Kafka的持久化策略设计 Kafka的节点间的数据一致性策略设计 Kafka的备份和负载均衡 Kafka消息队列内部实现原理 Kafka消息队列原理 最近在测试kafka的读写性能,所以借这个机会了解了kafka的一些设计原理,既然作为分布式系统,我们还是按照分布式的套路进行分析. Kafka的逻辑数据模型 生产者发送数据给服务端时,构造的是ProducerRecord<In
-
Java分布式学习之Kafka消息队列
目录 介绍 Kafka核心相关名称 kafka集群安装 kafka使用 kafka文件存储 Springboot整合kafka 介绍 Apache Kafka 是分布式发布-订阅消息系统,在 kafka官网上对 kafka 的定义:一个分布式发布-订阅消息传递系统. 它最初由LinkedIn公司开发,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目.Kafka是一种快速.可扩展的.设计内在就是分布式的,分区的和可复制的提交日志服务. 注意:Kafka并没有遵循JMS规范(
-
通过pykafka接收Kafka消息队列的方法
没有Kafka环境,所以也没有进行验证.感觉今后应该能用到,所以借抄在此,备查. pykafka使用示例,自动消费最新消息,不重复消费: # -* coding:utf8 *- from pykafka import KafkaClient host = '192.168.200.38' client = KafkaClient(hosts="%s:9092" % host) print client.topics # 生产者 # topicdocu = client.topics['
-
Spring boot 整合KAFKA消息队列的示例
这里使用 spring-kafka 依赖和 KafkaTemplate 对象来操作 Kafka 服务. 一.添加依赖和添加配置项 1.1.在 Pom 文件中添加依赖 <dependency> <groupId>org.springframework.kafka</groupId> <artifactId>spring-kafka</artifactId> </dependency> 1.2.添加配置项 spring: kafka: b
-
解决RabbitMq消息队列Qos Prefetch消息堵塞问题
mq是实现代码扩展的有利手段,个人喜欢用概念来学习新知识,介绍堵塞问题的之前,先来段概念的学习. ConnectionFactory:创建connection的工厂类 Connection: 简单理解为socket Channel:和mq交互的接口,定义queue.exchange和绑定queue.exhange等接口都是它. 接下来就是和mq的交互类 exchange:简单地看成路由,类型不是重点,看看官网即可 queue:客户端监听的是queue,而不是exchange,但是使用queue的
-
Java kafka如何实现自定义分区类和拦截器
生产者发送到对应的分区有以下几种方式: (1)指定了patition,则直接使用:(可以查阅对应的java api, 有多种参数) (2)未指定patition但指定key,通过对key的value进行hash出一个patition: (3)patition和key都未指定,使用轮询选出一个patition. 但是kafka提供了,自定义分区算法的功能,由业务手动实现分布: 1.实现一个自定义分区类,CustomPartitioner实现Partitioner import org.apache
-
kafka 消息队列中点对点与发布订阅的区别说明
目录 背景知识 1.JMS中定义 2.二者分析与区别 2.1 点对点模式 2.2 发布订阅模式 3.流行的消息队列模型比较 3.1 RabbitMQ 3.2 Kafka 背景知识 JMS一个在 Java标准化组织(JCP)内开发的标准(代号JSR 914).2001年6月25日,Java消息服务发布JMS 1.0.2b,2002年3月18日Java消息服务发布 1.1. Java消息服务(Java Message Service,JMS)应用程序接口是一个Java平台中关于面向消息中间件(MOM
-
KOA+egg.js集成kafka消息队列的示例
Egg.js : 基于KOA2的企业级框架 Kafka:高吞吐量的分布式发布订阅消息系统 本文章将集成egg + kafka + mysql 的日志系统例子 系统要求:日志记录,通过kafka进行消息队列控制 思路图: 这里消费者和生产者都由日志系统提供 λ.1 环境准备 ①Kafka 官网下载kafka后,解压 启动zookeeper: bin/zookeeper-server-start.sh config/zookeeper.properties 启动Kafka server 这里conf