python 使用OpenCV进行曝光融合
目录
- 1 什么是曝光融合
- 2 曝光融合的原理
- 3 代码与结果
1 什么是曝光融合
曝光融合是一种将使用不同曝光设置拍摄的图像合成为一张看起来像色调映射的高动态范围(HDR)图像的图像的方法。当我们使用相机拍摄照片时,每个颜色通道只有8位来表示场景的亮度。然而,我们周围世界的亮度理论上可以从0(黑色)到几乎无限(直视太阳)。因此,傻瓜相机或移动相机根据场景决定曝光设置,以便使用相机的动态范围(0-255值)来表示图像中最有趣的部分。例如,在许多相机中,使用面部检测来查找面部并设置曝光,使得面部看起来很好。这引出了一个问题-我们可以在不同的曝光设置下拍摄多张照片并拍摄更大范围的场景亮度吗?答案是肯定的。传统上使用HDR成像然后进行色调映射的方式。具体见上篇文章:
HDR成像要求我们知道精确的曝光时间。HDR图像本身看起来很暗,看起来不太漂亮。DR图像中的最小强度为0,但理论上没有最大值。所以我们需要将其值映射到0到255之间,以便我们可以显示它。将HDR图像映射到常规的每通道8位彩色图像的过程称为色调映射。如您所见,组装HDR图像和色调映射有点麻烦。我们不能不使用HDR就使用多个图像创建色调映射图像。结果证明我们可以用曝光融合来实现。
2 曝光融合的原理
应用曝光融合的步骤如下所述:
- 使用不同曝光拍摄多张图像

首先,我们需要在不移动相机的情况下捕获同一场景的一系列图像。如上所示,序列中的图像具有不同的曝光。这是通过改变相机的快门速度来实现的。通常,我们选择一些曝光不足的图像,一些曝光过度的图像和一个正确曝光的图像。
在“正确”曝光的图像中,选择快门速度(由相机或摄影师自动选择),以便每通道8位动态范围用于表示图像中最有趣的部分。太暗的区域被剪切为0,而太亮的区域被饱和到255。
在曝光不足的图像中,快门速度很快,图像很暗。因此,图像的8位用于捕获亮区域,而暗区域被剪切为0。在曝光过度的图像中,快门速度较慢,因此传感器捕获的光线更多,因此图像更亮。传感器的8位用于捕获暗区域的强度,而亮区域饱和到255的值。大多数单反相机都有一个称为自动曝光包围(AEB)的功能,只需按一下按钮,我们就可以在不同曝光下拍摄多张照片。当我们在iPhone中使用HDR模式时,它需要三张照片(安卓可以下载超级相机这个软件)。
图像对齐:
即使使用三脚架获取序列中的图像也需要对齐,因为即使较小的相机抖动也会降低最终图像的质量。OpenCV提供了一种使用对齐这些图像的简便方法AlignMTB。该算法将所有图像转换为中值阈值位图(MTB)。通过将值1分配给比中值亮度更亮的像素来计算图像的MTB,否则为0。MTB 对曝光时间不变。因此,可以对准MTB而无需我们指定曝光时间。
图像融合:
具有不同曝光的图像捕获不同范围的场景亮度。根据Tom Mertens,Jan Kautz和Frank Van Reeth 题为Exposure Fusion的论文。论文见:曝光融合通过仅保留多重曝光图像序列中的“最佳”部分来计算所需图像。
作者提出了三个质量指标:
1曝光良好:如果序列中的图像中的像素接近零或接近255,则不应使用该图像来查找最终像素值。其值接近中间强度(128)的像素是比较合适的。
2对比度:高对比度通常意味着高品质。因此,对于该像素,给予特定像素的对比度值高的图像具有更高的权重。
3饱和度:类似地,更饱和的颜色更少被淘汰并且代表更高质量的像素。因此,特定像素的饱和度高的图像被赋予该像素的更高权重。
三种质量度量用于创建权重图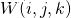 该权重图表示
该权重图表示 , 图像在位置处的像素的最终强度中的贡献
, 图像在位置处的像素的最终强度中的贡献 , 对权重图
, 对权重图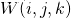 ,进行归一化,使得对于任何像素
,进行归一化,使得对于任何像素 所以所有图像的贡献总计为1。
所以所有图像的贡献总计为1。
结合权重图使用以下等式组合图像是很有效的:

其中,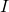 ,是原始图像,
,是原始图像,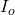 , 是输出图像。问题在于,由于像素是从不同曝光的图像中拍摄的,因此
, 是输出图像。问题在于,由于像素是从不同曝光的图像中拍摄的,因此
使用上述等式获得的输出图像将显示许多裂缝。该论文的作者使用拉普拉斯金字塔来混合图像。我们将在以后的文章中介绍这项技术的细节。
幸运的是使用OpenCV,这种图像曝光融合合并只是使用MergeMertens该类的两行代码。请注意,这个名字取决于Exposure Fusion论文的第一作者Tom Mertens 。
3 代码与结果
代码地址:
C++:
#include "pch.h"
#include <iostream>
#include <opencv2/opencv.hpp>
#include <vector>
#include <fstream>
using namespace cv;
using namespace std;
// Read Images
void readImages(vector<Mat> &images)
{
int numImages = 16;
static const char* filenames[] =
{
"image/memorial0061.jpg",
"image/memorial0062.jpg",
"image/memorial0063.jpg",
"image/memorial0064.jpg",
"image/memorial0065.jpg",
"image/memorial0066.jpg",
"image/memorial0067.jpg",
"image/memorial0068.jpg",
"image/memorial0069.jpg",
"image/memorial0070.jpg",
"image/memorial0071.jpg",
"image/memorial0072.jpg",
"image/memorial0073.jpg",
"image/memorial0074.jpg",
"image/memorial0075.jpg",
"image/memorial0076.jpg"
};
//读图
for (int i = 0; i < numImages; i++)
{
Mat im = imread(filenames[i]);
images.push_back(im);
}
}
int main()
{
// Read images 读取图像
cout << "Reading images ... " << endl;
vector<Mat> images;
//是否图像映射
bool needsAlignment = true;
// Read example images 读取例子图像
readImages(images);
//needsAlignment = false;
// Align input images
if (needsAlignment)
{
cout << "Aligning images ... " << endl;
Ptr<AlignMTB> alignMTB = createAlignMTB();
alignMTB->process(images, images);
}
else
{
cout << "Skipping alignment ... " << endl;
}
// Merge using Exposure Fusion 图像融合
cout << "Merging using Exposure Fusion ... " << endl;
Mat exposureFusion;
Ptr<MergeMertens> mergeMertens = createMergeMertens();
mergeMertens->process(images, exposureFusion);
// Save output image 图像保存
cout << "Saving output ... exposure-fusion.jpg" << endl;
imwrite("exposure-fusion.jpg", exposureFusion * 255);
return 0;
}
Python:
import cv2
import numpy as np
import sys
def readImagesAndTimes():
filenames = [
"image/memorial0061.jpg",
"image/memorial0062.jpg",
"image/memorial0063.jpg",
"image/memorial0064.jpg",
"image/memorial0065.jpg",
"image/memorial0066.jpg",
"image/memorial0067.jpg",
"image/memorial0068.jpg",
"image/memorial0069.jpg",
"image/memorial0070.jpg",
"image/memorial0071.jpg",
"image/memorial0072.jpg",
"image/memorial0073.jpg",
"image/memorial0074.jpg",
"image/memorial0075.jpg",
"image/memorial0076.jpg"
]
images = []
for filename in filenames:
im = cv2.imread(filename)
images.append(im)
return images
if __name__ == '__main__':
# Read images
print("Reading images ... ")
if len(sys.argv) > 1:
# Read images from the command line
images = []
for filename in sys.argv[1:]:
im = cv2.imread(filename)
images.append(im)
needsAlignment = False
else :
# Read example images
images = readImagesAndTimes()
needsAlignment = False
# Align input images
if needsAlignment:
print("Aligning images ... ")
alignMTB = cv2.createAlignMTB()
alignMTB.process(images, images)
else :
print("Skipping alignment ... ")
# Merge using Exposure Fusion
print("Merging using Exposure Fusion ... ");
mergeMertens = cv2.createMergeMertens()
exposureFusion = mergeMertens.process(images)
# Save output image
print("Saving output ... exposure-fusion.jpg")
cv2.imwrite("exposure-fusion.jpg", exposureFusion * 255)
本文第一张图获得的不同曝光的图像,通过这种方法所得结果如下:

在输入图像中,我们可以获得过度曝光图像中光线昏暗区域和曝光不足图像中明亮区域的细节。但是,在合并的输出图像中,像素在图像的每个部分都具有明亮的细节。我们还可以在之前的帖子中看到我们用于HDR成像的图像的这种效果。用于产生最终输出的四个图像显示在左侧,输出图像显示在右侧。结果如下图所示:

正如您在本文中所看到的,Exposure Fusion允许我们在不明确计算HDR图像的情况下实现类似于HDR + Tonemapping的效果。因此,我们不需要知道每张图像的曝光时间,但我们能够获得非常合理的结果。那么,为什么要费心去做HDR呢?好吧,在很多情况下,Exposure Fusion产生的输出可能不符合您的喜好。没有旋钮可以调整以使其变得不同或更好。另一方面,HDR图像捕获场景的原始亮度。如果您不喜欢色调映射的HDR图像,请尝试使用不同的色调映射算法。总之,Exposure Fusion代表了一种权衡。在速度和不太严格的要求下使得算法更加灵活(例如,不需要暴露时间)
到此这篇关于python 使用OpenCV进行曝光融合的文章就介绍到这了,更多相关OpenCV曝光融合内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python中使用Opencv开发停车位计数器功能
目录 1. 环境安装 1.1 安装并激活虚拟环境 1.2 python包安装 2. 绘制停车位矩形框 2.1 导入停车场图片 2.2 绘制矩形框 定位停车位 2.3 鼠标添加.删除停车位 3. 停车位视频分析 3. 1 停车监控视频 3. 2 截取停车位 3. 3 图像处理 3. 4 判断停车位是否被占用 在这个项目中,我们将创建一个停车位计数器.我们会发现总共有多少辆车,以及有多少停车位是空的.关于本教程最好的一点是,我们将使用基本的图像处理技术来解决这个问题,没有使用机器学习.深度学习进行训
-
Python OpenCV实现3种滤镜效果实例
目录 前言 浮雕滤镜效果 雕刻滤镜效果 凸透镜滤镜效果 总结 前言 本篇文章要使用OpenCV.Numpy 和Math这3个工具包实现一个简单的滤镜编辑器.在这个滤镜编辑器中,包含了3种滤镜效果,它们分别是浮雕滤镜.雕刻滤镜和凸透镜滤镜.本篇文章将对目标图像(如图1所示)进行处理,使得目标图像分别呈现浮雕滤镜(如图2所示).雕刻滤镜(如图3所示)和凸透镜滤镜(如图4所示)的视觉效果. 浮雕滤镜效果 为了实现浮雕滤镜效果,首先要把实现浮雕滤镜效果的原理搞清楚.弄明白.实现浮雕滤镜效果的原理如下所示
-
Python OpenCV实现图形检测示例详解
目录 1. 轮廓识别与描绘 1.1 cv2.findComtours()方法 1.2 cv2.drawContours() 方法 1.3 代码示例 2. 轮廓拟合 2.1 矩形包围框拟合 - cv2.boundingRect() 2.2圆形包围框拟合 - cv2.minEnclosingCircle() 3. 凸包 绘制 4. Canny边缘检测 - cv2.Canny() 4.1 cv2.Canny() 用法简介 4.2 代码示例 5. 霍夫变换 5.1 概述 5.2 cv2.HoughLin
-
Python OpenCV超详细讲解读取图像视频和网络摄像头
0.准备工作 右击新建的项目,选择Python File,新建一个Python文件,然后在开头import cv2导入cv2库. 1.读取图像调用imread()方法获取我们资源文件夹中的图片使用imshow()方法显示图片,窗口名称为OutputwaitKey(0)这句可以让窗口一直保持,如果去掉这句,窗口会一闪而过 我们来看下效果: 2.读取视频VideoCapture()方法的参数就是视频文件循环中通过read不断地去读视频的每一帧,再通过imshow显示出来最后if语句代表按q可以退出程
-
python OpenCV 图像通道数判断
目录 前言 教程 1.读取/保存图片 1)imread和imwrite方法 2)imdecode和imencode方法 2.编码转换 1)BGR转RGB 2)BGR转GRAY 3.快速判断图像是否单通道灰度图 4.获取图像通道数 前言 OpenCV是图像处理常用的库,作为初学者,往往从图片的读取.保存.查询图片的信息开始,下面将分享Python下OpenCV的一些基本使用方法,掌握这些基本方法后,能够更好地与matplotlib.numpy等结合使用,完成相应的图像操作. 教程 1.读取/保存图
-
关于python3 opencv 图像二值化的问题(cv2.adaptiveThreshold函数)
前一篇研究了opencv二值化方法threshold的使用,但是这个方法也存在一定的局限性,假如有一张图存在明显的明暗不同的区域,如下图 可以看到左边部分因为整体偏暗,导致二值化后变成全黑,丢失了所有细节,这显然不是我们想要的结果. 原因threshold函数使用一个阈值对图像进行二值化,导致小于这个阈值的像素点全都变成0.因此使用一个阈值的二值化方法并不适用于上面的这张图.那怎么搞? 很明显,上面这张图只有左右两个区域明显亮度不同,最简单的方法就是把图分成两个区域,每个区域分别进行二值化,也就
-
Python OpenCV超详细讲解调整大小与图像操作的实现
目录 准备工作 重新调整图像大小 图像裁剪 准备工作 右击新建的项目,选择Python File,新建一个Python文件,然后在开头import cv2导入cv2库. 我们还要知道在OpenCV中,坐标轴的方向是x轴向右,y轴向下,坐标原点在左上角,比如下面这张长为640像素,宽为480像素的图片.OK,下面开始本节的学习吧. 查看图像大小 调用imread()方法获取我们资源文件夹中的图片lambo.png 输出图像的shape属性 img=cv2.imread("Resources/lam
-
巧妙使用python opencv库玩转视频帧率
目录 需求背景 关于opencv 安装opencv opencv-python获取视频相关信息 需求背景 在很多时候我们需要抽取视频的某一帧做一些分析或修改等:比如笔者需求就是判断一个人在该视频中出现的频率,以判断他是否是这段视频的主角: 关于opencv OpenCV 是 Intel 开源计算机视觉库 (Computer Version) .它由一系列 C 函数和少量 C++ 类构成,实现了图像处理和计算机视觉方面的很多通用算法. OpenCV 拥有包括 300 多个 C 函数的跨平台的中.高
-
python+opencv实现堆叠图片
本文实例为大家分享了python+opencv实现堆叠图片的具体代码,供大家参考,具体内容如下 # import cv2 # import numpy as np # # img = cv2.imread('../images/full.jpg') # # img_hor = np.hstack((img,img)) # img_ver = np.vstack((img,img)) # # cv2.imshow('Horizontal',img_hor) # cv2.imshow('Vertic
-
python 使用OpenCV进行曝光融合
目录 1 什么是曝光融合 2 曝光融合的原理 3 代码与结果 1 什么是曝光融合 曝光融合是一种将使用不同曝光设置拍摄的图像合成为一张看起来像色调映射的高动态范围(HDR)图像的图像的方法.当我们使用相机拍摄照片时,每个颜色通道只有8位来表示场景的亮度.然而,我们周围世界的亮度理论上可以从0(黑色)到几乎无限(直视太阳).因此,傻瓜相机或移动相机根据场景决定曝光设置,以便使用相机的动态范围(0-255值)来表示图像中最有趣的部分.例如,在许多相机中,使用面部检测来查找面部并设置曝光,使得面部看起
-
Python+OpenCV实现图像融合的原理及代码
根据导师作业安排,在学习数字图像处理(刚萨雷斯版)第六章 彩色图像处理 中的彩色模型后,导师安排了一个比较有趣的作业: 融合原理为: 1 注意:遥感原RGB图image和灰度图Grayimage为测试用的输入图像: 2 步骤:(1)将RGB转换为HSV空间(H:色调,S:饱和度,V:明度): (2)用Gray图像诶换掉HSV中的V: (3)替换后的HSV转换回RGB空间即可得到结果. 书上只介绍了HSI彩色模型,并没有说到HSV,所以需要网上查找资料. Python代码如下: import cv
-
python使用OpenCV模块实现图像的融合示例代码
可以通过OpenCV函数cv.add()或简单地通过numpy操作添加两个图像,res = img1 + img2.两个图像应该具有相同的深度和类型,或者第二个图像可以是标量值. 三种融合 注意融合时,一般来说两个图像的尺寸是一样大小的,如果大小不一样,需要把大的图像的某一部分先截出来,与小的图先融合,再作为整体替换掉原来大图中抠出的小图部分. """ # @Time : 2020/4/3 # @Author : JMChen """ impor
-
python中opencv图像叠加、图像融合、按位操作的具体实现
目录 1图像叠加 2图像融合 3按位操作 1图像叠加 可以通过OpenCV函数cv.add()或简单地通过numpy操作添加两个图像,res = img1 + img2.两个图像应该具有相同的深度和类型,或者第二个图像可以是标量值. NOTE: OpenCV添加是饱和操作,也就是有上限值,而Numpy添加是模运算. 添加两个图像时, OpenCV功能将提供更好的结果.所以总是更好地坚持OpenCV功能. 代码: import cv2 import numpy as np x = np.uint8
-
Python中OpenCV Tutorials 20 高动态范围成像的实现步骤
目录 高动态范围成像 一.引言 二.曝光序列 三.代码演示 四.解释 1. 加载图像和曝光时间 2. 估计相机响应 3. 形成HDR图像 4. 对 HDR 图像进行色调映射 5. 实现曝光融合 五.补充资源 高动态范围成像 一.引言 如今,大多数数字图像和成像设备每通道使用 8 位整数表示灰度,因此将设备的动态范围限制在两个数量级(实际上是 256 级),而人眼可以适应变化十个数量级的照明条件.当我们拍摄真实世界场景的照片时,明亮区域可能曝光过度,而黑暗区域可能曝光不足,因此我们无法使用单次曝光
-
python使用OpenCV获取高动态范围成像HDR
目录 1 背景 1.1 什么是高动态范围(HDR)成像? 1.2 高动态范围(HDR)成像如何工作? 2 代码 2.1 运行环境配置 2.2 读取图像和曝光时间 2.3 图像对齐 2.4 恢复相机响应功能 2.5 合并图像 2.6 色调映射 2.7 工程代码 1 背景 1.1 什么是高动态范围(HDR)成像? 大多数数码相机和显示器将彩色图像捕获或显示为24位矩阵.每个颜色通道有8位,一共三个通道,因此每个通道的像素值在0到255之间.换句话说,普通相机或显示器具有有限的动态范围. 然而,我们周
-
在树莓派2或树莓派B+上安装Python和OpenCV的教程
我的Raspberry Pi 2昨天刚邮到,这家伙看上去很小巧可爱. 这小家伙有4核900MHZ的处理器,1G内存.要知道,Raspberry Pi 2 可比我中学电脑实验室里大多数电脑快多了. 话说,自从Raspberry Pi 2发布以来,我收到了很多请求,要求我能写一个在它上面安装OpenCV和Python的详细说明. 因此如果你想在Raspberry Pi启动运行OpenCV和Python,就往下面看! 在博文的剩余部分,我将提供在Raspberry Pi 2 和Raspberry Pi
-
python使用opencv读取图片的实例
安装好环境后,开始了第一个Hello word 例子,如何读取图片,保存图品 import cv2 import numpy as np import matplotlib.pyplot as plt #读取图片代码 img = cv2.imread('test.jpg',cv2.IMREAD_GRAYSCALE) #IMREAD_COLOR = 1 #IMREAD_UNCHANGED = -1 #展示图片 cv2.imshow('image',img) cv2.waitKey(0) cv2.d
-
利用Python和OpenCV库将URL转换为OpenCV格式的方法
今天的博客是直接来源于我自己的个人工具函数库. 过去几个月,有些PyImageSearch读者电邮问我:"如何获取URL指向的图片并将其转换成OpenCV格式(不用将其写入磁盘再读回)".这篇文章我将展示一下怎么实现这个功能. 额外的,我们也会看到如何利用scikit-image从URL下载一幅图像.当然前行之路也会有一个常见的错误,它可能让你跌个跟头. 继续往下阅读,学习如何利用利用Python和OpenCV将URL转换为图像 方法1:OpenCV.NumPy.urllib 第一个方
-
python通过opencv实现批量剪切图片
上一篇文章中,我们介绍了python实现图片处理和特征提取详解,这里我们再来看看Python通过OpenCV实现批量剪切图片,具体如下. 做图像处理需要大批量的修改图片尺寸来做训练样本,为此本程序借助opencv来实现大批量的剪切图片. import cv2 import os def cutimage(dir,suffix): for root,dirs,files in os.walk(dir): for file in files: filepath = os.path.join(root