Python实现多线程下载脚本的示例代码
0x01 分析
一个简单的多线程下载资源的Python脚本,主要实现部分包含两个类:
Download类:包含download()和get_complete_rate()两种方法。
- download()方法种首先用 urlopen() 方法打开远程资源并通过 Content-Length获取资源的大小,然后计算每个线程应该下载网络资源的大小及对应部分吗,最后依次创建并启动多个线程来下载网络资源的指定部分。
- get_complete_rate()则是用来返回已下载的部分占全部资源大小的比例,用来回显进度。
ThreadDownload类:该线程类继承了threading.Thread类,包含了一个run()方法。
run()方法主要负责每个线程读取网络数据并写入本地。
0x02 代码
# 文件名:ThreadDownload.py
import threading
from urllib.request import *
class Download:
def __init__(self, link, file_path, thread_num):
# 下载路径
self.link = link
# 保存位置
self.file_path = file_path
# 使用多少线程
self.thread_num = thread_num
# 初始化threads数组
self.threads = []
def download(self):
req = Request(url=self.link, method='GET')
req.add_header('Accept', '*/*')
req.add_header('Charset', 'UTF-8')
req.add_header('Connection', 'Keep-Alive')
f = urlopen(req)
# 获取要下载的文件的大小
self.file_size = int(dict(f.headers).get('Content-Length', 0))
f.close()
# 计算每个线程要下载的资源的大小
current_part_size = self.file_size // self.thread_num + 1
for i in range(self.thread_num):
# 计算每个线程下载的开始位置
start_pos = i * current_part_size
# 每个线程使用一个wb模式打开的文件进行下载
t = open(self.file_path, 'wb')
t.seek(start_pos, 0)
# 创建下载线程
td = ThreadDownload(self.link, start_pos, current_part_size, t)
self.threads.append(td)
td.start()
# 获下载的完成百分比
def get_complete_rate(self):
sum_size = 0
for i in range(self.thread_num):
sum_size += self.threads[i].length
return sum_size / self.file_size
class ThreadDownload(threading.Thread):
def __init__(self, link, start_pos, current_part_size, current_part):
super().__init__()
# 下载路径
self.link = link
# 当前线程的下载位置
self.start_pos = start_pos
# 定义当前线程负责下载的文件大小
self.current_part_size = current_part_size
# 当前文件需要下载的文件快
self.current_part = current_part
# 定义该线程已经下载的字节数
self.length = 0
def run(self):
req = Request(url = self.link, method='GET')
req.add_header('Accept', '*/*')
req.add_header('Charset', 'UTF-8')
req.add_header('Connection', 'Keep-Alive')
f = urlopen(req)
# 跳过self.start_pos个字节,表明该线程只负责下载自己负责的那部分内容
for i in range(self.start_pos):
f.read(1)
# 读取网络数据,并写入本地
while self.length < self.current_part_size:
data = f.read(1024)
if data is None or len(data) <= 0:
break
self.current_part.write(data)
# 累计该线程下载的总大小
self.length += len(data)
self.current_part.close()
f.close()
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# 文件名:thread_download-master.py
import sys
import time
from ThreadDownload import *
def show_process(dl):
while dl.get_complete_rate() < 1:
complete_rate = int(dl.get_complete_rate()*100)
print('\r' + '下载中···(已下载' + str(complete_rate) + '%)', end='', flush=True)
time.sleep(0.01)
def main():
try:
Link = input('[+]' + 'Link: ')
file_path = input('[+]' + 'File Path: ')
thread_number = input('[+]' + 'Thread Number: ')
thread_number = int(thread_number)
dl = Download(Link, file_path, thread_number)
dl.download()
print('\n开始下载!')
show_process(dl)
print('\r' + '下载中···(已下载' + '100%)', end='', flush=True)
print('\n下载完成!')
except Exception:
print('Parameter Setting Error')
sys.exit(1)
if __name__=='__main__':
main()
0x03 运行结果
下载歌曲《男孩》为例,下载到./Download/目录下并命名为男孩.mp3,设置5个线程:
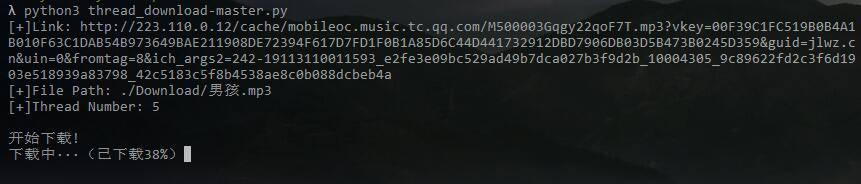
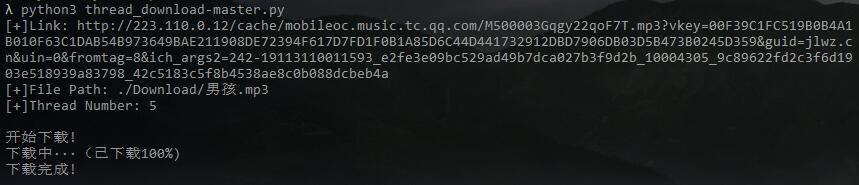
下载成功:

到此这篇关于Python实现多线程下载脚本的示例代码的文章就介绍到这了,更多相关Python 多线程下载脚本内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python多线程下载文件的方法
本文实例讲述了Python多线程下载文件的方法.分享给大家供大家参考.具体实现方法如下: import httplib import urllib2 import time from threading import Thread from Queue import Queue from time import sleep proxy = 'your proxy'; opener = urllib2.build_opener( urllib2.ProxyHandler({'http':proxy
-
python多线程http下载实现示例
测试平台 Ubuntu 13.04 X86_64 Python 2.7.4 花了将近两个小时, 问题主要刚开始没有想到传一个文件对象到线程里面去, 导致下载下来的文件和源文件MD5不一样,浪费不少时间. 有兴趣的同学可以拿去加上参数,改进下, 也可以加上断点续传. 复制代码 代码如下: # -*- coding: utf-8 -*-# Author: ToughGuy# Email: wj0630@gmail.com# 写这玩意儿是为了初步了解下python的多线程机制# 平时没写注释的习惯,
-
Python实现多线程下载文件的代码实例
实现简单的多线程下载,需要关注如下几点:1.文件的大小:可以从reponse header中提取,如"Content-Length:911"表示大小是911字节2.任务拆分:指定各个线程下载的文件的哪一块,可以通过request header中添加"Range: bytes=300-400"(表示下载300~400byte的内容),注意可以请求的文件的range是[0, size-1]字节的.3.下载文件的聚合:各个线程将自己下载的文件块保存为临时文件,所有线程都完
-
python爬虫爬取快手视频多线程下载功能
环境: python 2.7 + win10 工具:fiddler postman 安卓模拟器 首先,打开fiddler,fiddler作为http/https 抓包神器,这里就不多介绍. 配置允许https 配置允许远程连接 也就是打开http代理 电脑ip: 192.168.1.110 然后 确保手机和电脑是在一个局域网下,可以通信.由于我这边没有安卓手机,就用了安卓模拟器代替,效果一样的. 打开手机浏览器,输入192.168.1.110:8888 也就是设置的代理地址,安装证书之后才能
-
python支持断点续传的多线程下载示例
复制代码 代码如下: #! /usr/bin/env python#coding=utf-8 from __future__ import unicode_literals from multiprocessing.dummy import Pool as ThreadPoolimport threading import osimport sysimport cPicklefrom collections import namedtupleimport urllib2from urlparse
-

python 实现多线程下载视频的代码
代码: def thread(url): r = requests.get(url, headers=None, stream=True, timeout=30) # print(r.status_code, r.headers) headers = {} all_thread = 1 # 获取视频大小 file_size = int(r.headers['content-length']) # 如果获取到文件大小,创建一个和需要下载文件一样大小的文件 if file_size: fp = op
-
Python实现多线程下载脚本的示例代码
0x01 分析 一个简单的多线程下载资源的Python脚本,主要实现部分包含两个类: Download类:包含download()和get_complete_rate()两种方法. download()方法种首先用 urlopen() 方法打开远程资源并通过 Content-Length获取资源的大小,然后计算每个线程应该下载网络资源的大小及对应部分吗,最后依次创建并启动多个线程来下载网络资源的指定部分. get_complete_rate()则是用来返回已下载的部分占全部资源大小的比例,用来回
-
Python实现自动签到脚本的示例代码
实训课期间忙里偷闲的学习了python的selenium包,唯一一点不好是要自己去查英文文档,明摆着欺负我这种英语不好的,想着用谷歌翻译一下,代码也给我翻译了,不知道是几个意思. 大二的时候就让我们做自动签到脚本,说用JS可以写一下,但是说着说着就给忘了,现在学了python后又想起来要写一个自动签到的脚本,不得不佩服python的强大,短短二十行左右的代码就实现了,虽然说脚本还需要手动操作去运行,以后还是可以慢慢优化的. 开发环境 : Windows10 + sublime(编辑器装好pyth
-
python实现自动抢课脚本的示例代码
目录 自动抢课脚本使用手册 1.准备工作 2.配合使用py脚本和xlsx文件 3.auto_get_lesson_pic_recognize功能介绍 4.坐标版本(不建议使用) 5.代码 自动抢课脚本使用手册 @danteking dating from 2021.12.7 and last updating at 2021.12.8 gitee仓库 github仓库 借助pyautogui库,我们可以轻松地控制鼠标.键盘以及进行图像识别,实现自动抢课的功能 1.准备工作 我们在仓库里提供了2个
-
RxJava2.x+ReTrofit2.x多线程下载文件的示例代码
写在前面: 接到公司需求:要做一个apk升级的功能,原理其实很简单,百度也一大堆例子,可大部分都是用框架,要么就是HttpURLConnection,实在是不想这么干.正好看了两天的RxJava2.x+ReTrofit2.x,据说这俩框架是目前最火的异步请求框架了.固本文使用RxJava2.x+ReTrofit2.x实现多线程下载文件的功能. 如果对RxJava2.x+ReTrofit2.x不太了解的请先去看相关的文档. 大神至此请无视. 思路分析: 思路及其简洁明了,主要分为以下四步 1.获取
-
Java多线程文件分片下载实现的示例代码
多线程下载介绍 多线程下载技术是很常见的一种下载方案,这种方式充分利用了多线程的优势,在同一时间段内通过多个线程发起下载请求,将需要下载的数据分割成多个部分,每一个线程只负责下载其中一个部分,然后将下载后的数据组装成完整的数据文件,这样便大大加快了下载效率.常见的下载器,迅雷,QQ旋风等都采用了这种技术. 分片下载 所谓分片下载就是要利用多线程的优势,将要下载的文件一块一块的分配到各个线程中去下载,这样就极大的提高了下载速度. 技术难点 并不能说是什么难点,只能说没接触过不知道罢了. 1.如何请
-
python编写一个会算账的脚本的示例代码
python算账脚本 1.假如小明卡里有10000元去商场买东西发现钱不够又向父母借了5000账单如下 2.以下脚本就能实现上面的运算 from time import strftime import pickle import os try: def save(): data = strftime('\033[35m%Y-%m-%d\033[0m') money = int(input('How much do you have to save?:')) comment = input('Wh
-
Python使用urlretrieve实现直接远程下载图片的示例代码
在实现爬虫任务时,经常需要将一些图片下载到本地当中.那么在python中除了通过open()函数,以二进制写入方式来下载图片以外,还有什么其他方式吗?本文将使用urlretrieve实现直接远程下载图片. 下面我们再来看看 urllib 模块提供的 urlretrieve() 函数.urlretrieve() 方法直接将远程数据下载到本地. >>> help(urllib.urlretrieve) Help on function urlretrieve in module urllib
-
python自动从arxiv下载paper的示例代码
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Time : 2020/02/11 21:44 # @Author : dangxusheng # @Email : dangxusheng163@163.com # @File : download_by_href.py ''' 自动从arxiv.org 下载文献 ''' import os import os.path as osp import requests from lxml impor
-
Python获取网络图片和视频的示例代码
目录 1.网络获取Google图像 1.1google_images_download 1.2BeautifulSoup 1.3pyimagesearch 2.网络获取Youtube视频 1.网络获取Google图像 1.1 google_images_download Python 是一种多用途语言,广泛用于脚本编写.我们可以编写 Python 脚本来自动化日常事务.假设我们要下载具有多个搜索查询的谷歌图片.我们可以自动化该过程,而不是手动进行. 如何安装所需的模块: pip install