Python从csv文件中读取数据及提取数据的方法
目录
- 1.从csv文件中读取数据
- 2.数据切割
数据保存在csv文件中
1.从csv文件中读取数据
参数header=None的有无
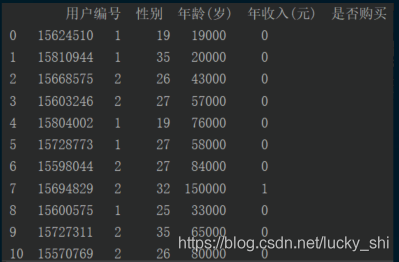
(1)没有header=None——直接将csv表中的第一行当作表头
# 读取数据
import pandas as pd
data = pd.read_csv("data1.csv")
print(data)
打印结果为:
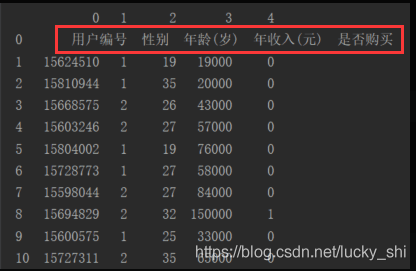
(2)有header=None——自动添加第一行当作表头
# 读取数据
import pandas as pd
data = pd.read_csv("data1.csv",header=None)
print(data)
打印结果为:
2.数据切割
(这里根据csv表的格式,将header=None不写)
(1)获取所有列,并存入一个数组中
# 读取数据
import pandas as pd
data = pd.read_csv("data1.csv")
# print(data)
# ①获取所有列,并存入一个数组中
import numpy as np
data = np.array(data)
print(data) # 用户编号 性别 年龄(岁) 年收入(元) 是否购买
# [[15624510 1 19 19000 0]
# [15810944 1 35 20000 0]
# [15668575 2 26 43000 0]
# [15603246 2 27 57000 0]
# [ ... ... ... ... ...]]
(2)获取指定列的数据,并存入一个数组中
方法一:从csv文件获取data,data[ ] ——需要考虑数据的维度问题
# 读取数据
import pandas as pd
data = pd.read_csv("data1.csv")
print(data) # 用户编号 性别 年龄(岁) 年收入(元) 是否购买
# (1)获取第1列,并存入一个数组中
import numpy as np
col_1 = data["用户编号"] #获取一列,用一维数据
data_1 = np.array(col_1)
print(data_1)
# [15624510 15810944 15668575 15603246 15804002 15728773 15598044 15694829
# 15600575 15727311 15570769 15606274 15746139 15704987 15628972 15697686
# 15733883 15617482 15704583 15621083 15649487 15736760 15714658 15599081
# 15705113 15631159 15792818 15633531 15744529]
# (2)获取第1,2列
col_12 = data[["用户编号","性别"]] #获取两列,要用二维数据
data_12 = np.array(col_12)
print(data_12)
# [[15624510 1]
# [15810944 1]
# [15668575 2]
# [15603246 2]
# [ ... ..]]
方法二:usecols=[ ] —— 直接写入获取的列数
import pandas as pd
import numpy as np
data_1 = pd.read_csv("data1.csv",usecols=["用户编号"])
data_1 = np.array(data_1)
print(data_1)
# [[15624510]
# [15810944]
# [15668575]
# [15603246]
# [ ... ]]
# (2)如获取第1,2列
data_12 = pd.read_csv("data1.csv",usecols=["用户编号","性别"])
data_12 = np.array(data_12)
print(data_12)
# [[15624510 1]
# [15810944 1]
# [15668575 2]
# [15603246 2]
# [ ... ..]]
方法三:iloc[ ] ——实质就是切片操作
import pandas as pd
import numpy as np
data = pd.read_csv("data1.csv")
# (1)获取第1列
data_1 = data.iloc[:,0]
data_1 =np.array(data_1)
print(data_1)
# [15624510 15810944 15668575 15603246 15804002 15728773 15598044 15694829
# 15600575 15727311 15570769 15606274 15746139 15704987 15628972 15697686
# 15733883 15617482 15704583 15621083 15649487 15736760 15714658 15599081
# 15705113 15631159 15792818 15633531 15744529]
# (2)获取第1,2列
data_12 = data.iloc[:,0:2]
data_12 = np.array(data_12)
print(data_12)
# [[15624510 1]
# [15810944 1]
# [15668575 2]
# [15603246 2]
# [ ... ..]]
# 获取最后两列
data_last = data.iloc[:,-2:]
data_last = np.array(data_last)
print(data_last)
# [[ 19000 0]
# [ 20000 0]
# [ 26 43000 0]
# [ 27 57000 0]
# [ ... ... ...]]
到此这篇关于Python从csv文件中读取数据并提取数据的方法的文章就介绍到这了,更多相关Python csv文件中读取数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python读取当前目录下的CSV文件数据
在处理数据的时候,经常会碰到CSV类型的文件,下面将介绍如何读取当前目录下的CSV文件,步骤如下 1.获取当前目录所有的CSV文件名称: #创建一个空列表,存储当前目录下的CSV文件全称 file_name = [] #获取当前目录下的CSV文件名 def name(): #将当前目录下的所有文件名称读取进来 a = os.listdir() for j in a: #判断是否为CSV文件,如果是则存储到列表中 if os.path.splitext(j)[1] == '.csv': file_
-
Python之csv文件从MySQL数据库导入导出的方法
Python从MySQL数据库中导出csv文件处理 csv文件导入MySQL数据库 import pymysql import csv import codecs def get_conn(): conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='root', db='test_csv', charset='utf8') return conn def insert(cur, sql, args): c
-
Python使用Pandas对csv文件进行数据处理的方法
今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不给力,又尝试用R搞一下吧结果发现光加载csv文件就要3分钟左右的时间,相当不给力啊,翻了翻万能的知乎发现了Python下的一个神器包:Pandas(熊猫们?),加载这个140多M的csv文件两秒钟就搞定,后面的分类汇总等操作也都是秒开,太牛逼了!记录一下这次数据处理的过程: 使用
-
利用Python如何将数据写到CSV文件中
前言 我们从网上爬取数据,最后一步会考虑如何存储数据.如果数据量不大,往往不会选择存储到数据库,而是选择存储到文件中,例如文本文件.CSV 文件.xls 文件等.因为文件具备携带方便.查阅直观. Python 作为胶水语言,搞定这些当然不在话下.但在写数据过程中,经常因数据源中带有中文汉字而报错.最让人头皮发麻的编码问题. 我先说下编码相关的知识.编码方式有很多种:UTF-8, GBK, ASCII 等. ASCII 码是美国在上个世纪 60 年代制定的一套字符编码.主要是规范英语字符和二进制位
-
Python将一个CSV文件里的数据追加到另一个CSV文件的方法
在做数据处理工作时,有时需要将数据合并在一起,本文主要使用Python将两个CSV文件内数据合并在一起,合并方式有很多,本文只追加方式. 首先给定两个CSV文件的内容 1.CSV 2.CSV 将2.CSV文件里的数据追加到1.CSV后面 直接敲写Python代码 with open('1.csv','ab') as f: f.write(open('2.csv','rb').read())#将2.csv内容追加到1.csv的后面 查看1.CSV内的数据变化情况 非常简单快捷的一次Python操作
-

python读写数据读写csv文件(pandas用法)
python中数据处理是比较方便的,经常用的就是读写文件,提取数据等,本博客主要介绍其中的一些用法.Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能. 一.pandas读取csv文件 数据处理过程中csv文件用的比较多. import pandas as pd data = pd.read_csv('F:/Zhu/test/test.csv') 下面看一下pd.read_csv常用的参数: panda
-
python数据处理之如何选取csv文件中某几行的数据
前言 有些人看到这个问题觉得不是问题,是嘛,不就是df.col[]函数嘛,其实忽略了一个重点,那就是我们要省去把csv文件全部读取这个过程,因为如果在面临亿万级别的大规模数据,得到的结果就是boom,boom,boom. 我们要使用一下现成的函数里面的参数nrows,和skiprows,一个代表你要读几行,一个代表你从哪开始读,这就可以了,比如从第3行读取4个 示例代码 import pandas as pd df = pd.DataFrame({'a':[1,2,3,4,5,6,7,8,9],
-
使用python读取csv文件快速插入数据库的实例
如下所示: # -*- coding:utf-8 -*- # auth:ckf # date:20170703 import pandas as pd import cStringIO import warnings from sqlalchemy import create_engine import sys reload(sys) sys.setdefaultencoding('utf8') warnings.filterwarnings('ignore') engine = create_
-
使用python的pandas库读取csv文件保存至mysql数据库
第一:pandas.read_csv读取本地csv文件为数据框形式 data=pd.read_csv('G:\data_operation\python_book\chapter5\\sales.csv') 第二:如果存在日期格式数据,利用pandas.to_datatime()改变类型 data.iloc[:,1]=pd.to_datetime(data.iloc[:,1]) 注意:=号,这样在原始的数据框中,改变了列的类型 第三:查看列类型 print(data.dtypes) 第四:方法一
-
Python从csv文件中读取数据及提取数据的方法
目录 1.从csv文件中读取数据 2.数据切割 数据保存在csv文件中 1.从csv文件中读取数据 参数header=None的有无 (1)没有header=None--直接将csv表中的第一行当作表头 # 读取数据 import pandas as pd data = pd.read_csv("data1.csv") print(data) 打印结果为: (2)有header=None--自动添加第一行当作表头 # 读取数据 import pandas as pd data = pd
-
python实现从文件中读取数据并绘制成 x y 轴图形的方法
如下所示: import matplotlib.pyplot as plt import numpy as np def readfile(filename): dataList = [] dataNum = 0 with open(filename,'r') as f: for line in f.readlines(): linestr = line.strip('\n') if len(linestr) < 8 and len(linestr) >1: dataList.append(f
-
聊聊Python对CSV文件的读取与写入问题
今天天气"刚刚好"(薛之谦么么哒),无聊的我翻到了一篇关于csv文件读取与写入的帖子,作为测试小白的我一直对python情有独钟,顿时心血来潮,决定小搞他一下,分享给那些需要的小白,对于python大神们来说,简直就是小儿科,对于我这种测试小白,看到代码就如同打了鸡血一样,恩恩,好东西,好东西! csv文件的读取: 前期工作:在定义的py文件里边创建一个excel文件,并另存为csv文件,放入三行数据,我这里是姓名+年龄(可以自己随意写) 首先我们要在python环境里导入csv板块(
-
python 使用matplotlib 实现从文件中读取x,y坐标的可视化方法
1. test.txt文件,数据以逗号分割,第一个数据为x坐标,第二个为y坐标,数据如下:1.1,2 2.1,2 3.1,3 4.1,5 40,38 42,41 43,42 2. python部分代码 #!/usr/bin/python # coding: utf-8 import matplotlib.pyplot as plt import numpy as np import matplotlib as mpl mpl.rcParams['font.family'] = 'sans-ser
-
Perl从文件中读取字符串的两种实现方法
1. 一次性将文件中的所有内容读入一个数组中(该方法适合小文件): 复制代码 代码如下: open(FILE,"filename")||die"can not open the file: $!";@filelist=<FILE>; foreach $eachline (@filelist) { chomp $eachline;}close FILE;@filelist=<FILE>; 当文件很大时,可能会出现"out
-
python 删除大文件中的某一行(最有效率的方法)
用 python 处理一个文本时,想要删除其中中某一行,常规的思路是先把文件读入内存,在内存中修改后再写入源文件. 但如果要处理一个很大的文本,比如GB级别的文本时,这种方法不仅需要占用很大内存,而且一次性读入内存时耗费时间,还有可能导致内存溢出. 所以,需要用另外一个思路去处理. 我们可以使用 open() 方法把需要修改的文件打开为两个文件,然后逐行读入内存,找到需要删除的行时,用后面的行逐一覆盖.实现方式见以下代码. with open('file.txt', 'r') as old_fi
-
Python数据读写之Python读写CSV文件
目录 1. 读取CSV文件 csv.reader() 2. 写入CSV文件 1. 读取CSV文件 csv.reader() 该方法的作用相当于就是通过 ',' 分割csv格式的数据,并将分割好的每行数据存入列表中,并且还去除了每行最后分割产生的数据尾部的空格.换行符.制表符等等. import csv with open('data.csv',mode='r',encoding='utf-8-sig',newline='') as File: # 使用csv.reader()将文件中的每行数据读
-
PHP如何从txt文件中读取数据详解
目录 一.打开/关闭文件 二.读写文件 1.读取整个文件 2.读取一行数据 3.读取一个字符 4.读取任意长度的字符串 总结 一.打开/关闭文件 1.对文件操作时首先要打开文件,打开文件用 fopen()函数,语法是: fopen(filename,mode,include_path,context); 2.对文件操作结束后应该关闭这个文件,使用函数 fclose(); 例如: 二.读写文件 1.读取整个文件 有三个函数可以使用,分别是:readfile()函数.file()函数.file_ge
-
python读csv文件时指定行为表头或无表头的方法
pd.read_csv()方法中header参数,默认为0,标签为0(即第1行)的行为表头.若设置为-1,则无表头.示例如下: (1)不设置header参数(默认)时: df1 = pd.read_csv('target.csv',encoding='utf-8') df1 (2)header=1时: import pandas as pd df2 = pd.read_csv('target.csv',encoding='utf-8',header=1) df2 (3)header=-1时(可用