python算法学习双曲嵌入论文代码实现数据集介绍
目录
- 1. 目标
- Python 代码依赖库
- 2. 数据集
- 数据展示
学习的文章:
Poincaré Embeddings for Learning Hierarchical Representations
主要参考的代码:
poincare_embeddings
gensim – Topic Modelling in Python - poincare.py
由于有些代码难以运行,有些比较难读(封装程度非常高)甚至有些代码写得存在一些问题。因此我们重新按照论文的设置,利用Python重现了对应的方法,并成功运行,同时进行绘图展示。
1. 目标
我们有一些层级结构的网络类型数据,如何能够根据每个词的上下结构路径,将每个词语能够用一个向量来替换,换句话说,就是将词映射为实数域中的向量(词嵌入,word embedding)。最简单的想法是使用one-hot词向量,其构造起来很容易,但通常并不是一个好选择。主要的原因是,one-hot词向量无法准确表达不同词之间的相似度,同时也不能刻画词语之间的层次结构。而在另外的方法中,采用最多的是在欧式空间里进行嵌入(word2vec),这种方式的embedding可以有效表示出词语间的相似性,但却依旧难以刻画出词语之间的层次结构。
这时候为了既能够衡量词与词之间的相似性,又能衡量这种词与词之间的层次结构,引入了双曲几何的思想,在双曲空间中进行嵌入。双曲嵌入表征层级结构的能力就要比欧氏空间嵌入的能力高得多,同时需要的维数却更少。
Python 代码依赖库
为了能够顺利跑通后面的代码,这里先展示出代码需要依赖的库:
import nltk
# nltk.download('wordnet') # 第一次运行需运行此命令,安装wordnet数据集
from nltk.corpus import wordnet as wn
from math import *
import random
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.lines as mlines
import networkx as nx
2. 数据集
训练数据集采用wordnet中的数据进行实现,相关的数据说明在上周的文档中已经进行了介绍,这里不再进行赘述。
由于整个的wordnet数据集比较大,为了测试代码,我们只使用哺乳动物(mammal)及其相关的分支进行学习。首先我们看看数据集长什么样。由于我们只需要用到层次结构信息,因此我们只需将数据集里面每个哺乳动物相关名词的子节点与父节点的关系进行读取与构建。
network = {} # 构建层级网络
last_level = 8 # 最深的层设置为8层
levelOfNode = {} # 数据的层级信息,0为哺乳动物(根节点),1为哺乳动物下一结构
# 递归构建network
def get_hyponyms(synset, level):
if (level == last_level):
levelOfNode[str(synset)] = level
return
if not str(synset) in network:
network[str(synset)] = [str(s) for s in synset.hyponyms()]
levelOfNode[str(synset)] = level
for hyponym in synset.hyponyms():
get_hyponyms(hyponym, level + 1)
# 构建以哺乳动物为根节点的层次结构数据集
mammal = wn.synset('mammal.n.01')
get_hyponyms(mammal, 0)
levelOfNode[str(mammal)] = 0
# 将终端叶子节点补到network字典中
for a in levelOfNode:
if not a in network:
network[a] = []
数据展示
运行完成上述代码后,可以得到对应的节点层级,以及总体的网络分支。
节点层级(数值表示层级数,最深的层设置为6,0为根节点)
网络分支情况
为了更清晰地将树的结构进行刻画,用一个代码进一步将相关的层次结构直接进行展示。
def norm(x):
return np.dot(x, x)
def traverse(graph, start, node):
node_name = node.name().split(".")[0]
graph.depth[node_name] = node.shortest_path_distance(start)
for child in node.hyponyms():
child_name = child.name().split(".")[0]
graph.add_edge(node_name, child_name) # 添加边
traverse(graph, start, child) # 递归构建
def hyponym_graph(start):
G = nx.Graph() # 定义一个图
G.depth = {}
traverse(G, start, start)
return G
def graph_draw(graph):
plt.figure(figsize=(10, 10)) # 展示整体的网络
# plt.figure(figsize=(3, 3)) # 展示大象网络
nx.draw(graph,
node_size = [10 * graph.degree(n) for n in graph],
node_color = [graph.depth[n] for n in graph],
alpha = 0.8,
font_size = 4,
width = 0.5,
with_labels = True)
def get_keys(d, value):
return [k for k,v in d.items() if v == value]
root_name = get_keys(graph.depth, 0)[0]
plt.savefig("~/hyperE/fig/" + root_name + ".png", dpi = 300)
graph = hyponym_graph(mammal)
graph_draw(graph)
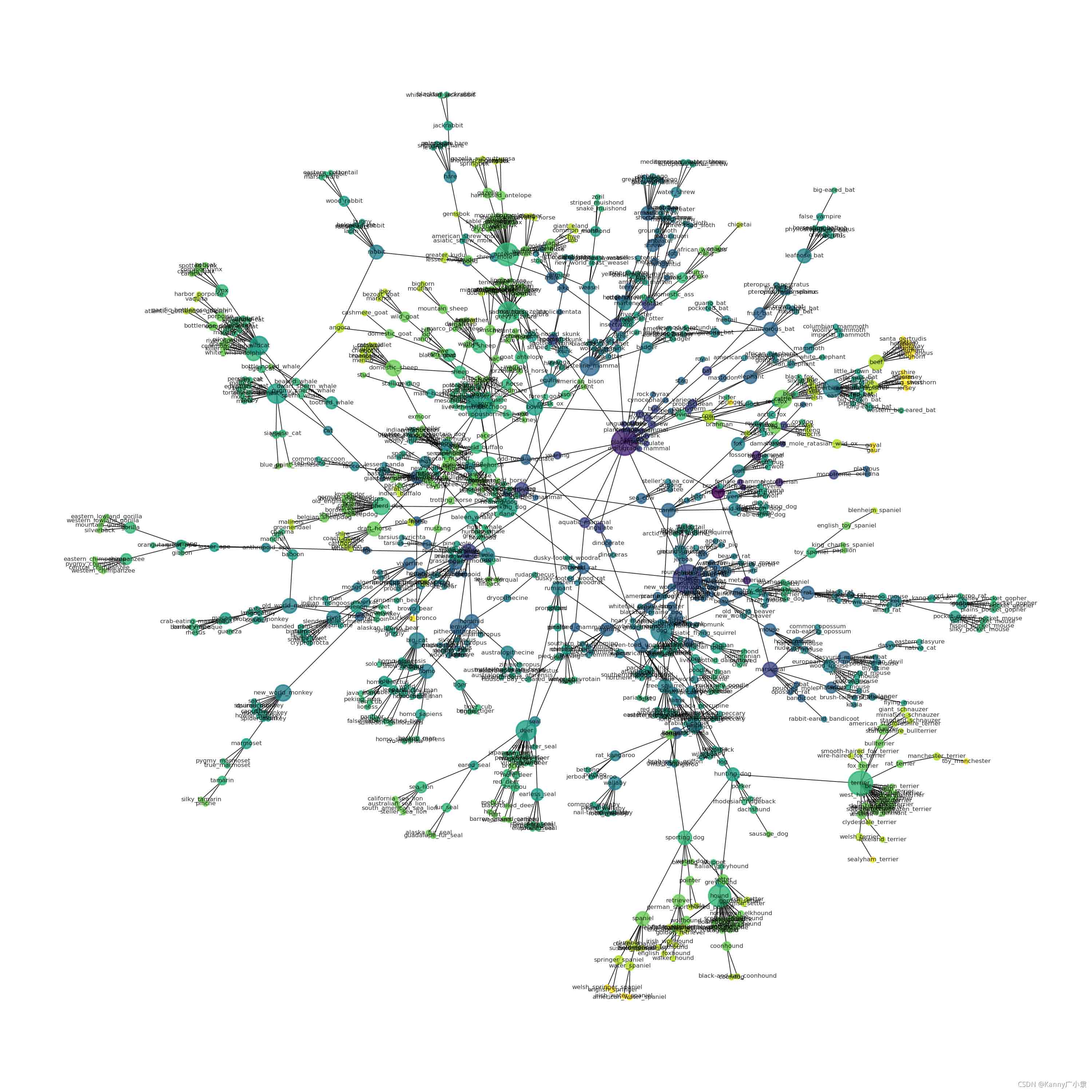
绘制出来的哺乳动物(mammal)全体的结构如下(此时没有空间信息,只有层级信息,为了展示才显示为下图所示的样式):
其中,颜色越深,节点越大,表示节点的层级越接近根节点(哺乳动物)。
由于数据非常多,展示的不是很清楚,这里我们单纯的提出出来大象(elephant)的结构,进一步看看数据集的情况。
elephant = wn.synset('elephant.n.01')
graph = hyponym_graph(elephant)
graph_draw(graph)
后面我们将利用这份数据集,进行方法的介绍,以及双曲嵌入模型的训练。
请见:双曲嵌入论文与代码实现——2. 方法与代码
以上就是python算法学习双曲嵌入论文代码实现数据集介绍的详细内容,更多关于python算法数据集双曲嵌入论文代码的资料请关注我们其它相关文章!
相关推荐
-
python opencv把一张图片嵌入(叠加)到另一张图片上的实现代码
python opencv把一张图片嵌入(叠加)到另一张图片上 1.背景: 最近做了个烟火生成系统的界面设计,需要将烟雾图片嵌入到任意一张图片中,因此需要python opencv把一张图片嵌入(叠加)到另一张图片上的知识.(图中红框最终生成图片没有的,只是界面有这个功能) 2.代码 resized1[global_y0:height+global_y0, global_x0:weight+global_x0] = resized0 resized0是小图 resized1是大图,其他参数是左上
-
Python如何实现在字符串里嵌入双引号或者单引号
两种方法实现: 1.在双引号前面加个转义符 \ ,即反斜杠.如"Hello \"W \"orld",会输出 Hello "W"orld 2.用单引号引起整个字符串,如'Hello "W"orld',同样输出 Hello "W"orld 同理也可以在字符串里嵌入单引号,如"Hello 'W'orld",输出 Hello 'W'orld 补充拓展:python中单引号(').双引号(&quo
-
将Python代码嵌入C++程序进行编写的实例
把python嵌入的C++里面需要做一些步骤 安装python程序,这样才能使用python的头文件和库 在我们写的源文件中增加"Python.h"头文件,并且链入"python**.lib"库(还没搞清楚这个库时静态库还是导出库,需要搞清楚) 掌握和了解一些python的C语言api,以便在我们的c++程序中使用 常用的一些C API函数 在了解下面的函数之前有必要了解一下**PyObject***指针,python里面几乎所有的对象都是使用这个指
-

python算法学习双曲嵌入论文代码实现数据集介绍
目录 1. 目标 Python 代码依赖库 2. 数据集 数据展示 学习的文章: Poincaré Embeddings for Learning Hierarchical Representations 主要参考的代码: poincare_embeddings gensim – Topic Modelling in Python - poincare.py 由于有些代码难以运行,有些比较难读(封装程度非常高)甚至有些代码写得存在一些问题.因此我们重新按照论文的设置,利用Python重现了对应的
-
python算法学习双曲嵌入论文方法与代码解析说明
目录 1. 方法说明 损失函数 梯度下降 梯度求解 2. 代码训练过程 3. 结果表现 其他参考资料 本篇接上一篇:python算法学习双曲嵌入论文代码实现数据集介绍 1. 方法说明 首先学习相关的论文中的一些知识,并结合进行代码的编写.文中主要使用Poincaré embedding. 对应的python代码为: def dist1(vec1, vec2): # eqn1 diff_vec = vec1 - vec2 return 1 + 2 * norm(diff_vec) / ((1 -
-
python算法学习之计数排序实例
python算法学习之计数排序实例 复制代码 代码如下: # -*- coding: utf-8 -*- def _counting_sort(A, B, k): """计数排序,伪码如下: COUNTING-SORT(A, B, k) 1 for i ← 0 to k // 初始化存储区的值 2 do C[i] ← 0 3 for j ← 1 to length[A] // 为各值计数 4 do C[A[j]] ← C[A
-
Luhn算法学习及其Ruby版实现代码示例
关于LUHN算法 LUHN算法,主要用来计算信用卡等证件号码的合法性. 1.从卡号最后一位数字开始,偶数位乘以2,如果乘以2的结果是两位数,将两个位上数字相加保存. 2.把所有数字相加,得到总和. 3.如果信用卡号码是合法的,总和可以被10整除. Luhn 算法或是Luhn 公式,也被称作"模10算法".它是一种简单的校验公式,一般会被用于身份证号码,IMEI号码,美国供应商识别号码,或是加拿大的社会保险号码的验证.该算法是由IBM的科学家Hans Peter Luhn所创造,于195
-
Python应用实现双指数函数及拟合代码实例
双指数函数 待拟合曲线为 y(x) = bepx + ceqx import matplotlib.pyplot as plt x = ([0.05, 0.1, 0.15, 0.2, 0.25, 0.3, 0.35, 0.4, 0.45, 0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95, 1.0]) y = ([0.33, 0.26, 0.18, 0.16, 0.12, 0.09, 0.08, 0.07, 0.06, 0.06, 0.0
-
python算法学习之桶排序算法实例(分块排序)
复制代码 代码如下: # -*- coding: utf-8 -*- def insertion_sort(A): """插入排序,作为桶排序的子排序""" n = len(A) if n <= 1: return A B = [] # 结果列表 for a in A: i = len(B) while i > 0 and B[i-1] > a:
-
python算法学习之基数排序实例
基数排序法又称桶子法(bucket sort)或bin sort,顾名思义,它是透过键值的部份资讯,将要排序的元素分配至某些"桶"中,藉以达到排序的作用,基数排序法是属于稳定性的排序,其时间复杂度为O (nlog(r)m),其中r为所采取的基数,而m为堆数,在某些时候,基数排序法的效率高于其它的比较性排序法. 复制代码 代码如下: # -*- coding: utf-8 -*- def _counting_sort(A, i): """计数排序,以i
-
Python matplotlib 绘制双Y轴曲线图的示例代码
Matplotlib简介 Matplotlib是非常强大的python画图工具 Matplotlib可以画图线图.散点图.等高线图.条形图.柱形图.3D图形.图形动画等. Matplotlib安装 pip3 install matplotlib#python3 双X轴的 可以理解为共享y轴 ax1=ax.twiny() ax1=plt.twiny() 双Y轴的 可以理解为共享x轴 ax1=ax.twinx() ax1=plt.twinx() 自动生成一个例子 x = np.arange(0.,
-
Python新手学习标准库模块命名
与Python标准库模块命名冲突 Python的一个优秀的地方在于它提供了丰富的库模块.但是这样的结果是,如果你不下意识的避免,很容易你会遇到你自己的模块的名字与某个随Python附带的标准库的名字冲突的情况(比如,你的代码中可能有一个叫做email.py的模块,它就会与标准库中同名的模块冲突). 这会导致一些很粗糙的问题,例如当你想加载某个库,这个库需要加载Python标准库里的某个模块,结果呢,因为你有一个与标准库里的模块同名的模块,这个包错误的将你的模块加载了进去,而不是加载Python标
-
Python新手学习函数默认参数设置
在某些情况下,程序需要在定义函数时为一个或多个形参指定默认值,这样在调用函数时就可以省略为该形参传入参数值,而是直接使用该形参的默认值. 为形参指定默认值的语法格式如下: 形参名 = 默认值 从上面的语法格式可以看出,形参的默认值紧跟在形参之后,中间以英文"="隔开. 例如,如下程序为 name.message 形参指定了默认值: # 为两个参数指定默认值 def say_hi(name = "孙悟空", message = "欢迎来到C语言中文网&quo