python的链表基础知识点
python中的链表(linked list)是一组数据项的集合,其中每个数据项都是一个节点的一部分,每个节点还包含指向下一个节点的链接。链表有两种类型:单链表和双链表。
链表的数据结构如下图所示:
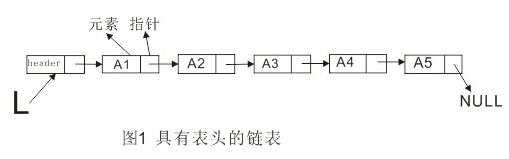
在链表中删除操作可以通过修改指针来实现,如下图所示:

插入则是调整,插入点的前后两个指针的指向关系,如下图所示:

在python中每个变量都是指针,例如:
用内置数据结构(list,dict,tuple等)的嵌套/组合,它们隐式地包含了指向/嵌套关系,如graph[u][v]={w0,w1..}类的成员变量、嵌套类可能包含了指向/嵌套关系;
引用表示指向关系,只不过引用不能像指针一样运算,比如p+1指向下一个元素,所以可能限制颇多。因此,要实现链表的操作,不能和c一样直接对指针进行操作。
内容扩展:
链表是计算机科学里面应用应用最广泛的数据结构之一。它是最简单的数据结构之一,同时也是比较高阶的数据结构(例如棧、环形缓冲和队列)
简单的说,一个列表就是单数据通过索引集合在一起。在C里面这叫做指针。比方说,一个数据元素可以由地址元素,地理元素、路由信息活着交易细节等等组成。但是链表里面的元素类型都是一样的,是一种特殊的列表。
一个单独的列表元素叫做一个节点。这些节点不像数组一样都按顺序存储在内存当中,相反,你可以通过一个节点指向另外一个节点的指针在内存不同的地方找到这些元素。列表最后一项习惯用NIL表示,相当于python里面的None
以上就是python的链表基础知识点的详细内容,更多关于python有链表吗的资料请关注我们其它相关文章!
相关推荐
-
Python双链表原理与实现方法详解
本文实例讲述了Python双链表原理与实现方法.分享给大家供大家参考,具体如下: Python实现双链表 文章目录 Python实现双链表 单链表与双链表比较 双链表的实现 定义链表节点 初始化双链表 判断链表是否为空 双链表尾部添加元素 双链表头部添加节点: 双链表表头删除 双链表按位置插入 双链表删除指定节点 完整代码 单链表与双链表比较 双链表比单链表多一个前驱指针位置,空间效率不占优势 由于双链表中的节点既可以向前也可以向后,相比单链表在查找方面效率更高(可使用二分法) 双链表的实现 定
-
Python单链表原理与实现方法详解
本文实例讲述了Python单链表原理与实现方法.分享给大家供大家参考,具体如下: Python实现单链表 关于链表 链表(Linked List)是由许多相同数据类型的数据项按照特定顺序排列而成的线性表. 链表中个数据项在计算机内存中的位置是不连续且随机的,数组在内存中是连续的. 链表数据的插入和删除很方便,但查找数据效率低下,不能像数组一样随机读取数据. 单链表的实现 一个单向链表的节点由数据字段和指针组成,指针指向下一个元素所在内存地址 定义一个链表节点类,self.value实例属性表示节
-
python判断链表是否有环的实例代码
先看下实例代码: class Node: def __init__(self,value=None): self.value = value self.next = None class LinkList: def __init__(self,head = None): self.head = head def get_head_node(self): """ 获取头部节点 """ return self.head def append(self
-
使用python实现数组、链表、队列、栈的方法
引言 什么是数据结构? 数据结构是指相互之间存在着一种或多种关系的数据元素的集合和该集合中数据元素之间的关系组成. 简单来说,数据结构就是设计数据以何种方式组织并存储在计算机中. 比如:列表,集合和字典等都是数据结构 N.Wirth:"程序=数据结构+算法" 数据结构按照其逻辑结构可分为线性结构.树结构.图结构 线性结构:数据结构中的元素存在一对一的互相关系. 树结构:数据结构中的元素存在一对多的互相关系. 图结构:数据结构中的元素存在多对多的互相关系. 数组 在python中是没有数
-
python无序链表删除重复项的方法
题目描述: 给定一个没有排序的链表,去掉重复项,并保留原顺序 如: 1->3->1->5->5->7,去掉重复项后变为:1->3->5->7 方法: 顺序删除 递归删除 1.顺序删除 由于这种方法采用双重循环对链表进行遍历,因此,时间复杂度为O(n**2) 在遍历链表的过程中,使用了常数个额外的指针变量来保存当前遍历的结点,前驱结点和被删除的结点,所以空间复杂度为O(1) #!/usr/bin/env python3 # -*- coding: utf-8
-
python如何实现单链表的反转
这篇文章主要介绍了python如何实现单链表的反转,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 代码如下 # coding=utf-8 class Node: def __init__(self, data=None, next=None): self.data = data self.next = next def Reserver(link): pre = link cur = link.next pre.next = None whil
-
python的链表基础知识点
python中的链表(linked list)是一组数据项的集合,其中每个数据项都是一个节点的一部分,每个节点还包含指向下一个节点的链接.链表有两种类型:单链表和双链表. 链表的数据结构如下图所示: 在链表中删除操作可以通过修改指针来实现,如下图所示: 插入则是调整,插入点的前后两个指针的指向关系,如下图所示: 在python中每个变量都是指针,例如: 用内置数据结构(list,dict,tuple等)的嵌套/组合,它们隐式地包含了指向/嵌套关系,如graph[u][v]={w0,w1..}类的
-
python交互模式基础知识点学习
命令行模式 在Windows开始菜单选择"命令提示符",就进入到命令行模式,它的提示符类似C:\> Python交互模式 在命令行模式下敲命令python,就看到类似如下的一堆文本输出,然后就进入到Python交互模式,它的提示符是>>>, 在Python交互模式下输入exit()并回车,就退出了Python交互模式,并回到命令行模式: 区分命令行模式和Python交互模式: 在命令行模式下,可以执行python进入Python交互式环境,也可以执行python
-
python常量折叠基础知识点讲解
1.概念 所谓常量折叠,指的是在编译时就查找并计算常量表达式,而不是在运行时再对其进行计算,从而会使运行时更加精简和快速. 2.实例 在 Python 中,我们可以使用反汇编模块(Disassembler)获取 CPython 字节码,从而更好地了解代码执行的过程. 当使用dis模块反汇编上述常量表达式时,我们会得到以下字节码: >>> import dis >>> dis.dis("day_sec = 24 * 60 * 60") 0 LOAD_C
-
Python读写文件基础知识点
在 Python 中,读写文件有 3 个步骤: 1.调用 open()函数,返回一个 File 对象. 2.调用 File 对象的 read()或 write()方法. 3.调用 File 对象的 close()方法,关闭该文件. 新建一个sj.txt文档,内容为hello. 输入代码: helloFile=open('F:\\sj.txt') 调用open将返回一个File对象.File对象代表计算机中的一个文件,它只是Python中另一种类型的值. 有了File对象,就可以开始从它读
-
python关于变量名的基础知识点
变量名 1.组成:数字.字母.下划线 2.变量名要有意义 3.多个单词则用下划线,如user_id 4.python的变量名不要驼峰显示 字符串: 1.引号内的都称为 字符串 2.常用引号:' '," ",'' '',"" "",''' ''', """ """ 3.支持运算:+,* 数值: 1.支持运算:+,-,*,/,**(指数),%(取余数),//(取商) 如:3**4=81 5%
-
Python爬虫入门有哪些基础知识点
1.什么是爬虫 爬虫,即网络爬虫,大家可以理解为在网络上爬行的一直蜘蛛,互联网就比作一张大网,而爬虫便是在这张网上爬来爬去的蜘蛛咯,如果它遇到资源,那么它就会抓取下来.想抓取什么?这个由你来控制它咯. 比如它在抓取一个网页,在这个网中他发现了一条道路,其实就是指向网页的超链接,那么它就可以爬到另一张网上来获取数据.这样,整个连在一起的大网对这之蜘蛛来说触手可及,分分钟爬下来不是事儿. 2.浏览网页的过程 在用户浏览网页的过程中,我们可能会看到许多好看的图片,比如 http://image.bai
-
python爬虫基础知识点整理
首先爬虫是什么? 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动的抓取万维网信息的程序或者脚本. 根据我的经验,要学习Python爬虫,我们要学习的共有以下几点: Python基础知识 Python中urllib和urllib2库的用法 Python正则表达式 Python爬虫框架Scrapy Python爬虫更高级的功能 1.Python基础学习 首先,我们要用Python写爬虫,肯定要了解Python的基础吧,万丈高楼平地起,
-
python中pivot()函数基础知识点
不同于以往为大家介绍的函数使用,我们利用pivot函数可以实现的方式,就是用来重塑数据使用的,在python的使用上并不常见,但是如果需要利用这种功能,基本上能够被我们选择调用的函数,pivot函数一定是榜上有名,下面我们就围绕着该函数,给大家做详细的内容讲解,一起来看下吧. 函数语法: pivot() 参数: Index.columns需要注意的是前者是可选参数,后者是必选参数. 使用实例: import pandas as pd df=pd.read_csv("user_label_part
-
python中K-means算法基础知识点
能够学习和掌握编程,最好的学习方式,就是去掌握基本的使用技巧,再多的概念意义,总归都是为了使用服务的,K-means算法又叫K-均值算法,是非监督学习中的聚类算法.主要有三个元素,其中N是元素个数,x表示元素,c(j)表示第j簇的质心,下面就使用方式给大家简单介绍实例使用. K-Means算法进行聚类分析 km = KMeans(n_clusters = 3) km.fit(X) centers = km.cluster_centers_ print(centers) 三个簇的中心点坐标为: [
-
python中子类与父类的关系基础知识点
在对于python中类的使用上,我们分出了子类和父类两种.对于这二者之间的关系,我们可以简单理解为继承.不过python中加入了实例的讨论,那么对于继承后的子类来说,父类的实例是否被继承又是我们所需要思考的问题.下面我们就子类和父类进行简单介绍,然后就二者之间的继承关系重点分析. 1.概念 子类和父类主要描述的是类之间的继承关系,即所属关系.继承的类可在被继承的类的基础上添加格外的参数和行为,新类称为子类,扩展类:被继承的类称为基类.父类或者超类. 2.继承关系 子类与父类的关系是 "is&qu
随机推荐
- 详解云与备份之VMware虚机备份和恢复
- Lua编程示例(四):Lua标准库之表库、字符串库、系统库
- 关于redis状态监控和性能调优详解
- js实现页面跳转的五种方法推荐
- spring boot自定义404错误信息的方法示例
- 浅谈Main方法的参数
- VC中使用ADO开发数据库应用程序简明教程
- gridview 行选添加颜色和事件
- Android仿微信实现首字母导航条
- 标题过长使用javascript按字节截取字符串
- nginx rewrite重写规则与防盗链配置方法教程详解
- Java 高并发七:并发设计模型详解
- Android ListView实现上拉加载更多和下拉刷新功能
- android中GridView实现点击查看更多功能示例
- java中List对象排序通用方法
- 利用C语言替换文件中某一行的方法
- C#在RichTextBox中显示不同颜色文字的方法
- php header Content-Type类型小结
- 利用python爬取斗鱼app中照片方法实例
- JDBC建立数据库连接的代码