Python CategoricalDtype自定义排序实现原理解析
CategoricalDtype自定义排序
当我们的透视表生成完毕后,有很多情况下需要我们对某列或某行值进行排序。排序有很多种方法。例如sort_index及sort_values函数也可以对数据进行排序,这里就不多说了。
对于数值和字母的排序很容易,但是对于中文的排序就有点麻烦了。默认情况下是按照utf-8的编码来进行排序的但是即使如此也很难满足我们对汉字排序的要求。所以通过CategoricalDtye可以把数据类型转成Category类型
然后通过指定参数列表的顺序来自定义那个元素先那个元素后,完全取决于你把那个元素放在List的前面,这样就大大方便了我们对中文排序的操作。
代码如下:
1. 自动生成DataFrame数据
#%%
import pandas as pd
from datetime import datetime
city =["上海","北京","深圳","杭州","苏州","青岛","大连","齐齐哈尔","大理","丽江",
"天津","济南","南京","广州","无锡","连云港","张家界"]
#创建自动从list中选取valuse值的get_list函数
#replace=True代表允许选出的元素重复
def get_list(items,size=20):
return pd.Series(items).sample(n=size,replace=True).to_list()
#通过get_list自动生成数据,最终生成一个DataFrame
df = pd.DataFrame({
"城市":get_list(city),
"仓位":get_list(["经济舱","商务舱","头等舱"]),
"航线":get_list(["单程","往返"]),
"日期": get_list([datetime(2020,8,1),datetime(2020,8,2),
datetime(2020,8,3),datetime(2020,8,4)]),
"时间": get_list(["09:00 - 12:00",
"13:00 - 15:30",
"06:30 - 15:00",
"18:00 - 21:00",
"20:00 - 23:20",
"10:00 - 15:00"]),
"航空公司": get_list(["东方航空","南方航空","深圳航空","山东航空","中国航空"]),
"出票数量":get_list([10,15,20,25,30,35,40,45,50,55,60]),
})
#%%
df
结果如下:

2. 查看数据类型
#%%
df.dtypes

3. 自定义数据类型(Category)按照指定顺序排序,并通过透视表展示数据
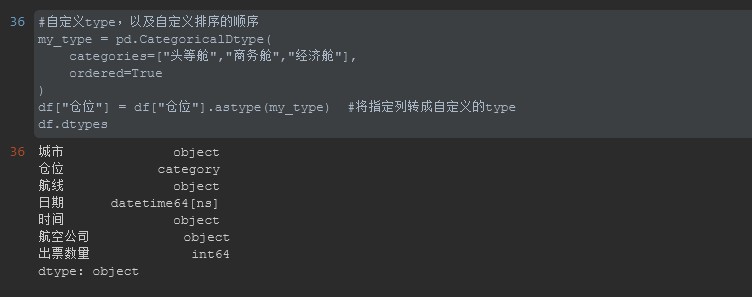
#%% #自定义type,以及自定义排序的顺序 my_type = pd.CategoricalDtype( categories=["头等舱","商务舱","经济舱"], ordered=True ) df["仓位"] = df["仓位"].astype(my_type) #将指定列转成自定义的type df.dtypes #%% #通过透视表统计数据 tb = pd.pivot_table( df, index=["城市","仓位","航线","日期","时间"], values="出票数量", aggfunc=sum ) tb
先查看数据类型:可以看出仓位的数据类型已经从Object变成了category类型了。
结果为:

分析上述数据可以看出,我们把仓位按照["头等舱","商务舱","经济舱"]的顺序进行了排序,排序结果也是按照这个顺序排列的,成功的满足了我们对中文列自定义排序的需求。
通过Pivot_table函数更加清晰的对原有数据进行了展示。也可以按照自己的需求展示其中的一部分数据。这样对数据的清洗及展示变得更加的灵活。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
keras.utils.to_categorical和one hot格式解析
keras.utils.to_categorical这个方法,源码中,它是这样写的: Converts a class vector (integers) to binary class matrix. E.g. for use with categorical_crossentropy. 也就是说它是对于一个类型的容器(整型)的转化为二元类型矩阵.比如用来计算多类别交叉熵来使用的. 其参数也很简单: def to_categorical(y, num_classes=None): Argume
-
Python自定义类的数组排序实现代码
首先把实现方法写出来,其实很简单,只需要一句代码即可: 复制代码 代码如下: productlist.sort(lambda p1, p2:cmp(p1.getPrice(), p2.getPrice())) 数组productlist中存储的是自定义类Product,Product有一个方法是返回商品的价格,于是对productlist按照Product的价格从低到高进行排序,仅需要如此简单的一行代码即可实现. Python真的是一门简洁而强大的语言,实际上,我也是从写出一行代码之后,才真正感
-
浅谈keras中的keras.utils.to_categorical用法
如下所示: to_categorical(y, num_classes=None, dtype='float32') 将整型标签转为onehot.y为int数组,num_classes为标签类别总数,大于max(y)(标签从0开始的). 返回:如果num_classes=None,返回len(y) * [max(y)+1](维度,m*n表示m行n列矩阵,下同),否则为len(y) * num_classes.说出来显得复杂,请看下面实例. import keras ohl=keras.utils
-
解决keras,val_categorical_accuracy:,0.0000e+00问题
问题描述: 在利用神经网络进行分类和识别的时候,使用了keras这个封装层次比较高的框架,backend使用的是tensorflow-cpu. 在交叉验证的时候,出现 val_categorical_accuracy: 0.0000e+00的问题. 问题分析: 首先,弄清楚,训练集.验证集.测试集的区别,验证集是从训练集中提前拿出一部分的数据集.在keras中,一般都是使用这种方式来指定验证集占训练集和的总大小. validation_split=0.2 比如,经典的数据集MNIST,共有600
-
Python实现快速排序和插入排序算法及自定义排序的示例
一.快速排序 快速排序(Quicksort)是对冒泡排序的一种改进.由C. A. R. Hoare在1962年提出.它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 快速排序,递归实现 def quick_sort(num_list): """ 快速排序 """ if num_li
-
python3 sorted 如何实现自定义排序标准
在 python2 中,如果想要自定义评价标准的话,可以这么做 def cmp(a, b): # 如果逻辑上认为 a < b ,返回 -1 # 如果逻辑上认为 a > b , 返回 1 # 如果逻辑上认为 a == b, 返回 0 pass a = [2,3,1,2] a = sorted(a, cmp) 但是在 python3 中,cmp 这个参数已经被移除了,那么在 python3 中应该怎么实现 python2 的 cmp 功能呢? import functools def cmp(a,
-
Keras中的多分类损失函数用法categorical_crossentropy
from keras.utils.np_utils import to_categorical 注意:当使用categorical_crossentropy损失函数时,你的标签应为多类模式,例如如果你有10个类别,每一个样本的标签应该是一个10维的向量,该向量在对应有值的索引位置为1其余为0. 可以使用这个方法进行转换: from keras.utils.np_utils import to_categorical categorical_labels = to_categorical(int_
-
Python CategoricalDtype自定义排序实现原理解析
CategoricalDtype自定义排序 当我们的透视表生成完毕后,有很多情况下需要我们对某列或某行值进行排序.排序有很多种方法.例如sort_index及sort_values函数也可以对数据进行排序,这里就不多说了. 对于数值和字母的排序很容易,但是对于中文的排序就有点麻烦了.默认情况下是按照utf-8的编码来进行排序的但是即使如此也很难满足我们对汉字排序的要求.所以通过CategoricalDtye可以把数据类型转成Category类型 然后通过指定参数列表的顺序来自定义那个元素先那个元
-
python线程定时器Timer实现原理解析
这篇文章主要介绍了python线程定时器Timer实现原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.线程定时器Timer原理 原理比较简单,指定时间间隔后启动线程!适用场景:完成定时任务,例如:定时提醒-闹钟等等. # 导入线程模块 import threading timer = threading.Timer(interval, function, args=None, kwargs=None) 参数介绍: interval
-
python实现布隆过滤器及原理解析
在学习redis过程中提到一个缓存击穿的问题, 书中参考的解决方案之一是使用布隆过滤器, 那么就有必要来了解一下什么是布隆过滤器.在参考了许多博客之后, 写个总结记录一下. 一.布隆过滤器简介 什么是布隆过滤器? 本质上布隆过滤器( BloomFilter )是一种数据结构,比较巧妙的概率型数据结构(probabilistic data structure),特点是高效地插入和查询,可以用来告诉你 "某样东西一定不存在或者可能存在". 相比于传统的 Set.Map 等数据结构,它更高效
-
Python迭代器模块itertools使用原理解析
这篇文章主要介绍了Python迭代器模块itertools使用原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 介绍 今天介绍一个很强大的模块,而且是python自带的,那就是itertools迭代器模块. 使用 使用起来很简单,先导入模块 import itertools 下面,我们通过一些例子边学边练 三个无限迭代器 先告诉大家 control + C 可以强制停止程序哦 1.count() num = itertools.count
-

python垃圾回收机制(GC)原理解析
这篇文章主要介绍了python垃圾回收机制(GC)原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 今天想跟大家分享的是关于python的垃圾回收机制,虽然本人这会对该机制没有很深入的了解, 但是本着热爱分享的原则,还是囫囵吞枣地坐下记录分享吧, 万一分享的过程中开窍了呢.哈哈哈. 首先还是做一下概述吧: 我们都知道, 在做python的语言编程中, 相较于java, c++, 我们似乎很少去考虑到去做垃圾回收,内存释放的工作, 其实是p
-
Python线程条件变量Condition原理解析
这篇文章主要介绍了Python线程条件变量Condition原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Condition 对象就是条件变量,它总是与某种锁相关联,可以是外部传入的锁或是系统默认创建的锁.当几个条件变量共享一个锁时,你就应该自己传入一个锁.这个锁不需要你操心,Condition 类会管理它. acquire() 和 release() 可以操控这个相关联的锁.其他的方法都必须在这个锁被锁上的情况下使用.wait()
-
Python类继承和多态原理解析
这篇文章主要介绍了python类继承和多态原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 现在属于是老年人的脑子,东西写着写着就忘了,东西记着记着就不知道了.之前学C++的时候就把类.对象这块弄得乱七八糟,现在是因为很想玩python,所以就看看python的类和对象. 就像说的,类有三个特征:封装.继承.多态. 1.封装:类封装了一些方法,可通过一定的规则约定方法进行访问权限. C++中的成员变量有public.private.pto
-
python next()和iter()函数原理解析
这篇文章主要介绍了python next()和iter()函数原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 我们首先要知道什么是可迭代的对象(可以用for循环的对象)Iterable: 一类:list,tuple,dict,set,str 二类:generator,包含生成器和带yield的generatoe function 而生成器不但可以作用于for,还可以被next()函数不断调用并返回下一个值,可以被next()函数不断返回
-
Python chardet库识别编码原理解析
这篇文章主要介绍了python chardet库识别编码原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 chardet库是python的字符编码检测器,能够检测出各种编码的类型,例如: import chardet import urllib.request testdata = urllib.request.urlopen('http://m2.cn.bing.com/').read() print(chardet.detect(te
-
Python接口自动化判断元素原理解析
这篇文章主要介绍了Python接口自动化判断元素原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 背景: 在做接口自动化时,通常会判断接口返回中的数据信息,与数据库中返回的数据信息是否一致,比如:将接口返回信息的用户姓名存放到一个列表中,将数据库返回的用户姓名存放到另一个列表中,这时需要判断两个列表是否一致,如果不一致,将不同的元素信息分别回写到excel文件中,可以一目了然的看出哪些信息返回的不正确. 下列代码中直接存放列表信息,比较如