C语言下快速排序(挖坑法)详解
目录
- 全部代码如下
- 挖坑法-->
- 代码讲解-->
- 总结
全部代码如下
#include <stdio.h>
void evaluation(int *x,int b)//赋值函数
{
*x = b;
}
void Compare(int arr[],int first,int last)
{
int one = first;//数列第一个元素下标
int end = last;//数列最后一个元素下标
int key = arr[one];//创建一个坑
//判断是否为一个元素
if (one >= end)//函数结束条件
{
return;
}
while (one < end)
{
while (one < end && arr[end] >= key)
{
end--;
}
evaluation(&arr[one],arr[end]);
while (one < end && arr[one] <= key)
{
one++;
}
evaluation(&arr[end],arr[one]);
}
int meeti = one;
evaluation(&arr[meeti],key);//将key填入坑位
Compare(arr,first,one-1);//左边继续挖坑排序
Compare(arr,one+1,last);//右边挖坑排序
}
int main()
{
int arr[] = { 4,3,6,6,3,4,8,2,6,9,4 };
int i = 0;
int len = sizeof(arr) / 4;
Compare(arr,i,len-1);
for (i = 0; i < len; i++)
{
printf("%d ",arr[i]);
}
return 0;
}
挖坑法-->
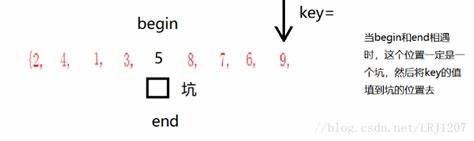
快速排序一般有两种写法,挖坑法和交换法,两者有一点区别,但总体都是基于分治思想的,上图是交换法的动图演示。 挖坑法的思想: 用两个指针 i 和 j 分别指向数组的第一个数和最后一个数,即令 i = 0 , j = arr.length - 1 。

首先选取一个坑位,这里左边第一个元素。 将第一个元素的数值记为key。
选取左边为key,从右边第一个元素依次与key进行比较,如果比key小则填入左边的坑位,而自己形成一个新的坑位。然后左边依次与key进行比较,如果比key大则填入右边的坑位;反复进行下去。直到L,R相遇,此时,必定是坑位,再将key值填入。
代码讲解-->
int main()
{
int arr[] = { 4,3,6,6,3,4,8,2,6,9,4 };
int i = 0;
int len = sizeof(arr) / 4;
Compare(arr,i,len-1);//传入数列最后一个元素下标
for (i = 0; i < len; i++)
{
printf("%d ",arr[i]);
}
return 0;
}
获取所待排序的数列,将数列和数列最后一个元素下标传入排序函数;
void Compare(int arr[],int first,int last)
{
int one = first;//数列第一个元素下标
int end = last;//数列最后一个元素下标
int key = arr[one];//创建一个坑
//判断是否为一个元素
if (one >= end)//函数结束条件
{
return;
}
while (one < end)
{
while (one < end && arr[end] >= key)//判断最后一个元素与key的大小
{
end--;
}
evaluation(&arr[one],arr[end]);//将arr[end]的值赋给arr[one]
while (one < end && arr[one] <= key)//判断第一个元素与key的大小
{
one++;
}
evaluation(&arr[end],arr[one]);//将arr[one]的值赋给arr[end]
}
int meeti = one;
evaluation(&arr[meeti],key);//将key填入坑位
Compare(arr,first,one-1);//左边继续挖坑排序
Compare(arr,one+1,last);//右边挖坑排序
}
赋值函数
void evaluation(int *x,int b)
{
*x = b;
}
也可以直接
arr[one] = arr[end];
总结
到此这篇关于C语言下快速排序(挖坑法)详解的文章就介绍到这了,更多相关C语言快速排序内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C语言之快速排序案例详解
快速排序:是对冒泡排序算法的一种改进. 它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列. 例如有一个数字序列: 5 0 1 6 8 2 3 4 9 7 对其进行快速排序变为:0 1 2 3 4 5 6 7 8 9 思路如下:首先将要排序的序列的首个数字5定位比较数,这是一个参考对象! 然后的方法很简单:分别从序列的两端进行比较.先
-
C语言 实现归并排序算法
C语言 实现归并排序算法 归并排序(Merge sort)是创建在归并操作上的一种有效的排序算法.该算法是采用分治法(Divide and Conquer)的一个非常典型的应用. 一个归并排序的例子:对一个随机点的链表进行排序 算法描述 归并操作的过程如下: 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列 设定两个指针,最初位置分别为两个已经排序序列的起始位置 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置 重复步骤3直到某一指针到达序列尾
-
C语言简单实现快速排序
快速排序是一种不稳定排序,它的时间复杂度为O(n·lgn),最坏情况为O(n2):空间复杂度为O(n·lgn). 这种排序方式是对于冒泡排序的一种改进,它采用分治模式,将一趟排序的数据分割成独立的两部分,其中一组数据的每个值都小于另一组.每一趟在进行分类的同时实现排序. 其中每一趟的模式通过设置key当基准元素,key的选择可以是数据的第一个,也可以是数据的最后一个.这里以每次选取数据的第一个为例: 具体代码实现: #include<stdio.h> #define N 6 int fun(i
-
C语言非递归算法解决快速排序与归并排序产生的栈溢出
目录 1.栈溢出原因和递归的基本认识 2.快速排序(非递归实现) 3.归并排序(非递归实现) 建议还不理解快速排序和归并排序的小伙伴们可以先去看我上一篇博客哦!C语言超详细讲解排序算法下篇 1.栈溢出原因和递归的基本认识 我们先简单来了解下内存分布结构: 栈区:用于存放地址.临时变量等: 堆区:程序运行期间动态分配所使用的场景: 静态区
-
C语言递归实现归并排序详解
归并排序递归实现还是比较难理解的,感觉涉及递归一般理解起来都会比较有难度吧,但是看了b站视频,然后照着打下来,然后自己写了点注释,就发现不知不觉都大概懂了. 这里的归并讲的是升序排序 归并排序思路大概就是:先划分数组,将数组划分为左右半区,分成的左右半区,各自再划分左右半区,一直划分,直到最后左右半区的元素都为一个时,开始合并,因为都划分为一个元素了,那么此时两个元素的排序就非常简单了,只需要比较大小就可以排序了,那么回溯上去会发现每组都是两两有序了,那么直接再依次比较两组之间的排头元素即可,取
-
举例讲解C语言对归并排序算法的基础使用
基础概念 百度百科是这么描述归并排序的: 归并操作(merge),也叫归并算法,指的是将两个已经排序的序列合并成一个序列的操作. 设有数列 {6,202,100,301,38,8,1} 初始状态: [6] [202] [100] [301] [38] [8] [1] 比较次数 i=1 [6 202 ] [ 100 301] [ 8 38] [ 1 ] 3 i=2 [ 6 100 202 301 ] [ 1 8 38 ] 4 i=3 [ 1 6 8 38 100 202 301 ] 4 总计: 1
-
C语言实现快速排序
快速排序算法是一种分治排序算法.它将数组划分为两个部分,然后分别对两个部分进行排序.我们将看到,划分的准确位置取决于输入数组中元素的初始位置.关键在于划分过程,它重排数组,使得以下三个条件成立:(i)对于某个i,a[i]在最终位置上 (ii)a[left],...,a[i-1]中的元素都比a[i]小 (iii)a[i+1],...a[right]中的元素都比a[i]大.我们通过划分来完成排序,然后递归地应用该方法处理子数组. 我们使用一般策略来实现划分.首先,我们任选一个a[right]作为划分
-
C语言开发之归并排序详解及实例
C语言归并排序 即将两个都升序(或降序)排列的数据序列合并成一个仍按原序排列的序列. 上代码: #include <stdio.h> #include <stdlib.h> #define m 6 #define n 4 int main() { int a[m]={-3,6,19,26,68,100} ,b[n]={8,10,12,22}; int i,j,k,c[m+n]; int l ; i=j=k=0; printf("a数组的元素:\n"); for
-
C语言下快速排序(挖坑法)详解
目录 全部代码如下 挖坑法--> 代码讲解--> 总结 全部代码如下 #include <stdio.h> void evaluation(int *x,int b)//赋值函数 { *x = b; } void Compare(int arr[],int first,int last) { int one = first;//数列第一个元素下标 int end = last;//数列最后一个元素下标 int key = arr[one];//创建一个坑 //判断是否为一个元素 i
-
C语言之system函数案例详解
来看看在windows操作系统下system () 函数详解(主要是在C语言中的应用) 注意:在windows下的system函数中命令可以不区别大小写! 函数名: system 功 能: 发出一个DOS命令 用 法: int system(char *command); system函数已经被收录在标准c库中,可以直接调用. 例如: #include<stdio.h> #include<stdlib.h> int main() { printf("About to sp
-
C语言MultiByteToWideChar和WideCharToMultiByte案例详解
目录 注意: 一.函数简单介绍 ( 1 ) MultiByteToWideChar() ( 2 ) WideCharToMultiByte() 二.使用方法 ( 1 ) 将多字节字符串转为宽字符串: ( 2 ) 从宽字节转为窄字节字符串 三.MultiByteToWideChar()函数乱码的问题 注意: 这两个函数是由Windows提供的转换函数,不具有通用性 C语言提供的转换函数为mbstowcs()/wcstombs() 一.函数简单介绍 涉及到的头文件: 函数所在头文件:windows.
-
史上最强C语言分支和循环教程详解
目录 3.3 do...while()循环 3.3.1 do语句的语法: 3.3.2 执行流程 3.3.3 do语句的特点 3.3.4 do while循环中的break和continue 3.4 练习 3.4.1. 计算 n的阶乘. 3.4.2. 计算 1!+2!+3!+--+10! 3.4.3. 在一个有序数组中查找具体的某个数字n. 3.4.4. 编写代码,演示多个字符从两端移动,向中间汇聚. 3.4.5. 编写代码实现,模拟用户登录情景,并且只能登录三次. 3.4.6.猜数字游戏实现 4
-
C语言实现无头单链表详解
目录 链表的结构体描述(节点) 再定义一个结构体(链表) 断言处理 & 判空处理 创建链表 创建节点 头插法 打印链表 尾插法 指定位置插入 头删法 尾删法 指定位置删除 查找链表 删除所有指定相同的元素 总结 再封装的方式,用 c++ 的思想做无头链表 链表的结构体描述(节点) #include <stdio.h> #include <stdlib.h> #include <assert.h> typedef int DataType; //节点 typede
-
Redis 对比 Memcached 并在 CentOS 下进行安装配置详解
Redis 是一个开源.支持网络.基于内存.键值对的 Key-Value 数据库,本篇文章主要介绍了Redis 对比 Memcached 并在 CentOS 下进行安装配置详解,有兴趣的可以了解一下. 了解一下 Redis Redis 是一个开源.支持网络.基于内存.键值对的 Key-Value 数据库,使用 ANSI C 编写,并提供多种语言的 API ,它几乎没有上手难度,只需要几分钟我们就能完成安装工作,并让它开始与应用程序顺畅协作.换句话来说,只需投入一小部分时间与精力,大家就能获得立竿
-
linux 下的yum命令详解
yum(全称为 Yellow dog Updater, Modified)是一个在Fedora和RedHat以及SUSE中的Shell前端软件包管理器.基於RPM包管理,能够从指定的服务器自动下载RPM包并且安装,可以自动处理依赖性关系,并且一次安装所有依赖的软体包,无须繁琐地一次次下载.安装.yum提供了查找.安装.删除某一个.一组甚至全部软件包的命令,而且命令简洁而又好记. yum的命令形式一般是如下:yum [options] [command] [package ...] 其中的[opt
-
Javascript 高性能之递归,迭代,查表法详解及实例
Javascript 高性能之递归,迭代,查表法详解 递归 概念:函数通过直接调用自身,或者两个函数之间的互相调用,来达到一定的目的,比如排序,阶乘等 简单的递归 阶乘 function factorial(n) { if (n == 0) { return 1; } else { return n * factorial(n - 1); } } 递归实现排序 /* 排序且合并数组 */ function myMerge(left, right) { // 保存最后结果的数组 var res =
-
MVC+DAO设计模式下的设计流程详解
DAO设计 : DAO层主要是做数据持久层的工作,负责与数据库进行联络的一些任务都封装在此,DAO层的设计首先是设计DAO的接口,然后在Spring的配置文件中定义此接口的实现类,然后就可在模块中调用此接口来进行数据业务的处理,而不用关心此接口的具体实现类是哪个类,显得结构非常清晰,DAO层的数据源配置,以及有关数据库连接的参数都在Spring的配置文件中进行配置. 在该层主要完成对象-关系映射的建立,通过这个映射,再通过访问业务对象即可实现对数据库的访问,使得开发中不必再用SQL语句编写复杂的
-
Java语言实现数据结构栈代码详解
近来复习数据结构,自己动手实现了栈.栈是一种限制插入和删除只能在一个位置上的表.最基本的操作是进栈和出栈,因此,又被叫作"先进后出"表. 首先了解下栈的概念: 栈是限定仅在表头进行插入和删除操作的线性表.有时又叫LIFO(后进先出表).要搞清楚这个概念,首先要明白"栈"原来的意思,如此才能把握本质. "栈"者,存储货物或供旅客住宿的地方,可引申为仓库.中转站,所以引入到计算机领域里,就是指数据暂时存储的地方,所以才有进栈.出栈的说法. 实现方式是