解决python 读取npy文件太大不能完全显示的问题
python读取npy文件时,太大不能完全显示,其解决方法
当用python读取npy文件时,会遇到npy文件太大,用print函数打印时不能完全显示,如以下情况:

解决办法
添加一行代码:np.set_printoptions(threshold = 1e6),其中threshold表示输出数组的元素数目
其结果如下:
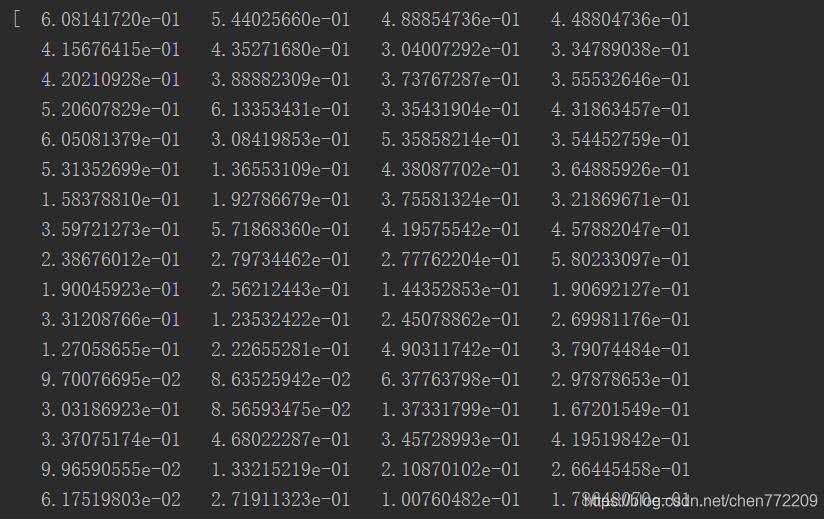
补充:PyCharm打开大文件时提示文件过大,只显示前一小部分
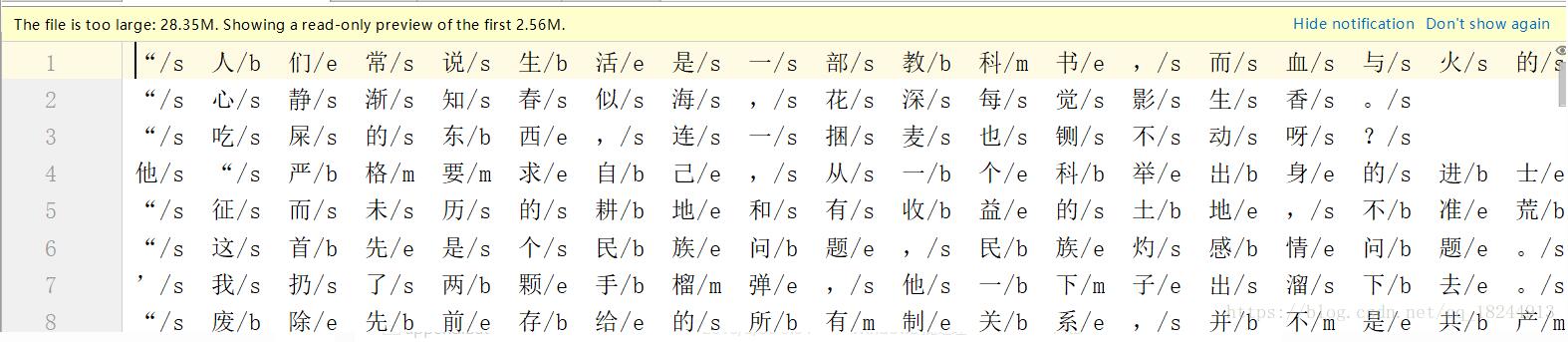
使用pycharm打开一些大文件时,会出现上述提示,表明文件过大,只能以只读的方式显示前一小部分内容,这种情况显然是非常不方便的,想要将文件全部显示,就需要修改pycharm的配置文件。
首先找到pycharm的安装路径,找到对应bin文件夹中的idea.properties文件。
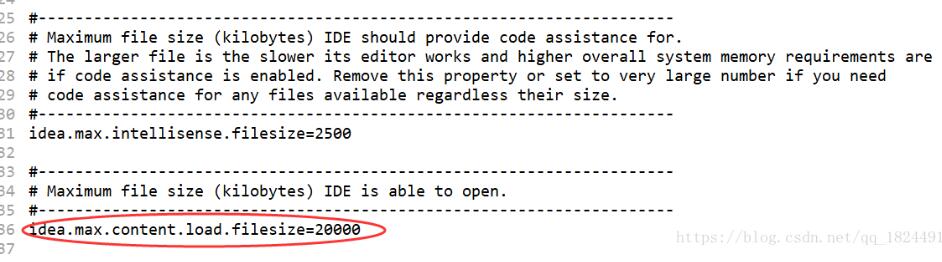
对其进行编辑,找到下图中对应的位置,修改后面的数值,将其变大即可。原数值为2000,可以显示2M左右的内容,改为20000后,就可以对稍大的文件进行显示,至于数值改成多少就看个人的需要了。
之后重启pycharm即可。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
python openpyxl 带格式复制表格的实现
有合并单元格的,先把合并单元格复制过去,合并单元格用wm=list(zip(wbsheet.merged_cells))得出合并单元格列表,把其中的(<CellRange A1:A4>,) 替换成为A1:A4格式 再从新表中合并单元格 再用.has_style: #拷贝格式 测试是否有格式,再复制格式和数据 其中: font(字体类):字号.字体颜色.下划线等 fill(填充类):颜色等 border(边框类):设置单元格边框 alignment(位置类):对齐方式 number_format
-
python openpyxl筛选某些列的操作
由于要复制excel 的某些单元格格式,需要对合并的单元格选出符合条件的 如下例是小于15的保留 然后在新表单中 wbsheet_new.merge_cells(cell2) wbsheet_new为新表单,cell2为筛选后保留的单元格,表达为I24:J24,K24:L24这样的格式 先正则筛选,筛选的结果为[('AO', 'AP')]这种list包含元组的表达方式,再用result[0][0]提取出第一个元素, 如果大于15列 column_index_from_string(result[
-

python中openpyxl和xlsxwriter对Excel的操作方法
前几天,项目中有个小需求:提供Excel的上传下载功能,使用模块:openpyxl 和 xlsxwriter,这里简单记录一下. 1.简介 Python中操作Excel的库非常多,为开发者提供了多种选择,如:xlrd. xlwt.xlutils.xlwings.pandas. win32com.openpyxl.xlsxwriter等等. 其中: 前三个一般混合使用,对Excel读写操作,适合旧版Excel,仅支持 xls 文件: win32com 库功能丰富,性能强大,适用于Windows:
-
解决python 使用openpyxl读写大文件的坑
由于需要处理xlsx类型的文件,我使用了openpyxl来处理,然而文件比较大,大约有60多MB.读文件的时候虽然慢了一点,但还是能够读出来,但是当我想写入时却报错了. 显示设备没有多余的空间,百度了一下,发现有不少关于openpyxl读写大文件的问题.总结来看,解决方案主要有以下两种,当然,我两种都用上了. 手动释放内存 del wb, ws gc.collect() 这一招还算有用,在读完文件后可以看到内存占用明显下降了一点. 安装lxml 使用命令·pip install lxml安装依赖
-
Python openpyxl 无法保存文件的解决方案
使用openpyxl保存文件的时候,出现最下面异常,查看openpyxl 的版本是2.5.14, 把openpyxl降级就可以解决此问题. [root@billig mytest]# pip install openpyxl==2.5.11 DEPRECATION: Python 2.7 will reach the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 won't be ma
-
详解Python openpyxl库的基本应用
1.导入文件 wb(可自定义) = openpyxl.load_workbook(#输入文件位置#) 2.转换为可处理的对象 sheet(可自定义)= wb['表格中对应的那一张的名称'] 3.sheet.cell(row=i, column=j) .value 可以显示对应单元格的值 4. wb.save['位置'] 保存表格 ''' # Created by Hailong Liu # for work # 2020.11.21 ''' import openpyxl #导入表格 w
-
Python使用openpyxl复制整张sheet
通过无能的baidu逛了一圈,发现有两三段能用的代码,不过参考之下,发现还有不足的: 不能拷贝有合并格式的sheet.没有拷贝cell的相关格式(填充.边框.对齐)等参数 所以通过bing继续发掘,最终合成以下代码: from copy import copy from openpyxl import load_workbook, Workbook def replace_xls(src_file,tag_file,sheet_name): # src_file是源xlsx文件,tag_file
-
解决python 读取npy文件太大不能完全显示的问题
python读取npy文件时,太大不能完全显示,其解决方法 当用python读取npy文件时,会遇到npy文件太大,用print函数打印时不能完全显示,如以下情况: 解决办法 添加一行代码:np.set_printoptions(threshold = 1e6),其中threshold表示输出数组的元素数目 其结果如下: 补充:PyCharm打开大文件时提示文件过大,只显示前一小部分 使用pycharm打开一些大文件时,会出现上述提示,表明文件过大,只能以只读的方式显示前一小部分内容,这种情况显
-
解决pyinstaller 打包exe文件太大,用pipenv 缩小exe的问题
解决pyinstaller 打包exe文件太大,用pipenv 缩小exe的问题 最近写一个小脚本,源代码200多行,引入了 openpyxl.requests库,写完打包exe之后居然有64MB的大小,真是奇了葩了.网上查找各位大神的做法,自己又动手填了N个坑之后,总算找到缩小exe文件的方法了,这种方法必须使用到pipenv,详细记录如下: 1.安装pipenv 就像安装其他python库一样,在cmd环境下安装: pip install pipenv 2.安装完成后,随便找一个盘符,在这个
-
python读取npy文件数据实例
目录 1. 读取与保存 2. 实战案例 附:python中 .npy文件的读写操作实例 总结 Numpy binary files (NPY, NPZ) 注:.npy文件是numpy专用的二进制文件. 1. 读取与保存 import numpy as np arr = np.array([[1, 2, 3], [4, 5, 6]]) np.save('weight.npy', arr) loadData = np.load('weight.npy') print("----type----&qu
-
解决python 打包成exe太大的问题
这是一个很长的故事,嫌长的直接看最后的结论 事情经过 上周接了个需求,写了个小工具给客户,他要求打包成exe文件,这当然不是什么难事.因为除了写Python的,绝大多数人电脑里都没有Python编译器,所以打包成exe,让用户(windows)双击就可以打开,也算是必备技能了. 直接用Pyinstaller,打开cmder: pyinstaller -Fw E:\test\url_crawler.py (-F 是打包成一个文件,-w是不出现调试窗口,因为我的小工具里有GUI,所以不用默认的调试窗
-
python读取查看npz/npy文件数据以及数据完全显示方法实例
目录 python读取npz/npy文件 python查看npz/npy文件 附:python-读取和保存npy文件示例代码 总结 python读取npz/npy文件 npz和npy文件都可以直接使用numpy读写. import numpy as np ac = np.load('mydata.npz') ac.files python查看npz/npy文件 要查看其中某一项的数据: M = ac['M'] M 显示的值带省略号,要完全显示,执行: np.set_printoptions(th
-
解决python读取几千万行的大表内存问题
Python导数据的时候,需要在一个大表上读取很大的结果集. 如果用传统的方法,Python的内存会爆掉,传统的读取方式默认在内存里缓存下所有行然后再处理,内存容易溢出 解决的方法: 1)使用SSCursor(流式游标),避免客户端占用大量内存.(这个cursor实际上没有缓存下来任何数据,它不会读取所有所有到内存中,它的做法是从储存块中读取记录,并且一条一条返回给你.) 2)使用迭代器而不用fetchall,即省内存又能很快拿到数据. import MySQLdb.cursors conn =
-
python读取mat文件中的struct问题
目录 python读取mat文件中的struct mat文件结构如下 经过查找资料,总结如下 解决办法 python读取mat文件报错 python读取mat文件中的struct All devils are in the details,做个笔记. mat文件结构如下 ground_truth_data 是1x1的struct(结构体),包含2个字段,一个是list,一个是imgszie.如图1所示 图1 list是一个352x1的cell,点开后如图2,可以看到list中的每一个cell又由
-
python 读取excel文件生成sql文件实例详解
python 读取excel文件生成sql文件实例详解 学了python这么久,总算是在工作中用到一次.这次是为了从excel文件中读取数据然后写入到数据库中.这个逻辑用java来写的话就太重了,所以这次考虑通过python脚本来实现. 在此之前需要给python添加一个xlrd模块,这个模块是专门用来操作excel文件的. 在mac中可以通过easy_install xlrd命令实现自动安装模块 import xdrlib ,sys import xlrd def open_excel(fil
-
Python读取ini文件、操作mysql、发送邮件实例
我是闲的没事干,2014过的太浮夸了,博客也没写几篇,哎~~~ 用这篇来记录即将逝去的2014 python对各种数据库的各种操作满大街都是,不过,我还是喜欢我这种风格的,涉及到其它操作,不过重点还是对数据库的操作.呵~~ Python操作Mysql 首先,我习惯将配置信息写到配置文件,这样修改时可以不用源代码,然后再写通用的函数供调用 新建一个配置文件,就命名为conf.ini,可以写各种配置信息,不过都指明节点(文件格式要求还是较严格的): 复制代码 代码如下: [app_info] DAT
-
解决Python字典写入文件出行首行有空格的问题
模拟购物车程序,判断用户薪资是否是0 如果是0就需要输入薪资,并记录到文件内. 可以预先存个字典格式的字符串,然后去读取文件的时候读到的是字字符串然后再去用eval去转换成字典. 当我们覆盖写到文件的时候就会发现首行会有空格,当我们再去读取eval的时候就会报错,那怎么样可以解决这个问题呢! import json info = { 'lisi':0, 'zhangshan':100, } f = open('json.txt','w') f.write(json.dumps(info)) {"