Python中LSTM回归神经网络时间序列预测详情
前言:
这个问题是国际航空乘客预测问题, 数据是1949年1月到1960年12月国际航空公司每个月的乘客数量(单位:千人),共有12年144个月的数据。
数据趋势:
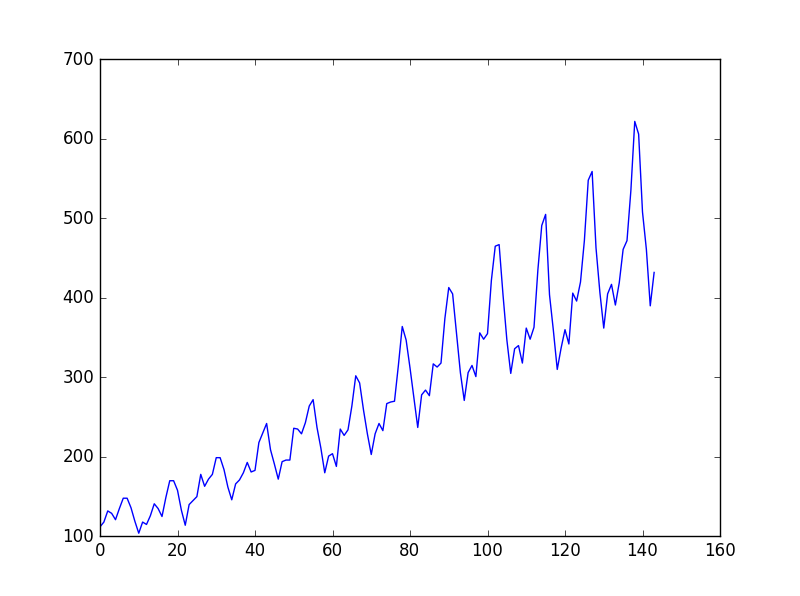
训练程序:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch.autograd import Variable
#LSTM(Long Short-Term Memory)是长短期记忆网络
data_csv = pd.read_csv('C:/Users/DZF/Desktop/LSTM/data.csv',usecols=[1])
#pandas.read_csv可以读取CSV(逗号分割)文件、文本类型的文件text、log类型到DataFrame
#原有两列,时间和乘客数量,usecols=1:只取了乘客数量一列
plt.plot(data_csv)
plt.show()
#数据预处理
data_csv = data_csv.dropna() #去掉na数据
dataset = data_csv.values #字典(Dictionary) values():返回字典中的所有值。
dataset = dataset.astype('float32') #astype(type):实现变量类型转换
max_value = np.max(dataset)
min_value = np.min(dataset)
scalar = max_value-min_value
dataset = list(map(lambda x: x/scalar, dataset)) #将数据标准化到0~1之间
#lambda:定义一个匿名函数,区别于def
#map(f(x),Itera):map()接收函数f和一个list,把函数f依次作用在list的每个元素上,得到一个新的object并返回
'''
接着我们进行数据集的创建,我们想通过前面几个月的流量来预测当月的流量,
比如我们希望通过前两个月的流量来预测当月的流量,我们可以将前两个月的流量
当做输入,当月的流量当做输出。同时我们需要将我们的数据集分为训练集和测试
集,通过测试集的效果来测试模型的性能,这里我们简单的将前面几年的数据作为
训练集,后面两年的数据作为测试集。
'''
def create_dataset(dataset,look_back=2):#look_back 以前的时间步数用作输入变量来预测下一个时间段
dataX, dataY=[], []
for i in range(len(dataset) - look_back):
a = dataset[i:(i+look_back)] #i和i+1赋值
dataX.append(a)
dataY.append(dataset[i+look_back]) #i+2赋值
return np.array(dataX), np.array(dataY) #np.array构建数组
data_X, data_Y = create_dataset(dataset)
#data_X: 2*142 data_Y: 1*142
#划分训练集和测试集,70%作为训练集
train_size = int(len(data_X) * 0.7)
test_size = len(data_X)-train_size
train_X = data_X[:train_size]
train_Y = data_Y[:train_size]
test_X = data_X[train_size:]
test_Y = data_Y[train_size:]
train_X = train_X.reshape(-1,1,2) #reshape中,-1使元素变为一行,然后输出为1列,每列2个子元素
train_Y = train_Y.reshape(-1,1,1) #输出为1列,每列1个子元素
test_X = test_X.reshape(-1,1,2)
train_x = torch.from_numpy(train_X) #torch.from_numpy(): numpy中的ndarray转化成pytorch中的tensor(张量)
train_y = torch.from_numpy(train_Y)
test_x = torch.from_numpy(test_X)
#定义模型 输入维度input_size是2,因为使用2个月的流量作为输入,隐藏层维度hidden_size可任意指定,这里为4
class lstm_reg(nn.Module):
def __init__(self,input_size,hidden_size, output_size=1,num_layers=2):
super(lstm_reg,self).__init__()
#super() 函数是用于调用父类(超类)的一个方法,直接用类名调用父类
self.rnn = nn.LSTM(input_size,hidden_size,num_layers) #LSTM 网络
self.reg = nn.Linear(hidden_size,output_size) #Linear 函数继承于nn.Module
def forward(self,x): #定义model类的forward函数
x, _ = self.rnn(x)
s,b,h = x.shape #矩阵从外到里的维数
#view()函数的功能和reshape类似,用来转换size大小
x = x.view(s*b, h) #输出变为(s*b)*h的二维
x = self.reg(x)
x = x.view(s,b,-1) #卷积的输出从外到里的维数为s,b,一列
return x
net = lstm_reg(2,4) #input_size=2,hidden_size=4
criterion = nn.MSELoss() #损失函数均方差
optimizer = torch.optim.Adam(net.parameters(),lr=1e-2)
#构造一个优化器对象 Optimizer,用来保存当前的状态,并能够根据计算得到的梯度来更新参数
#Adam 算法:params (iterable):可用于迭代优化的参数或者定义参数组的 dicts lr:学习率
for e in range(10000):
var_x = Variable(train_x) #转为Variable(变量)
var_y = Variable(train_y)
out = net(var_x)
loss = criterion(out, var_y)
optimizer.zero_grad() #把梯度置零,也就是把loss关于weight的导数变成0.
loss.backward() #计算得到loss后就要回传损失,这是在训练的时候才会有的操作,测试时候只有forward过程
optimizer.step() #回传损失过程中会计算梯度,然后optimizer.step()根据这些梯度更新参数
if (e+1)%100 == 0:
print('Epoch: {}, Loss:{:.5f}'.format(e+1, loss.data[0]))
torch.save(net.state_dict(), 'net_params.pkl') #保存训练文件net_params.pkl
#state_dict 是一个简单的python的字典对象,将每一层与它的对应参数建立映射关系
测试程序:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch.autograd import Variable
data_csv = pd.read_csv('C:/Users/DZF/Desktop/LSTM/data.csv',usecols=[1])
# plt.plot(data_csv)
# plt.show()
#数据预处理
data_csv = data_csv.dropna() #去掉na数据
dataset = data_csv.values #字典(Dictionary) values():返回字典中的所有值。
dataset = dataset.astype('float32') # astype(type):实现变量类型转换
max_value = np.max(dataset)
min_value = np.min(dataset)
scalar = max_value-min_value
dataset = list(map(lambda x: x/scalar, dataset)) #将数据标准化到0~1之间
def create_dataset(dataset,look_back=2):
dataX, dataY=[], []
for i in range(len(dataset)-look_back):
a=dataset[i:(i+look_back)]
dataX.append(a)
dataY.append(dataset[i+look_back])
return np.array(dataX), np.array(dataY)
data_X, data_Y = create_dataset(dataset)
class lstm_reg(nn.Module):
def __init__(self,input_size,hidden_size, output_size=1,num_layers=2):
super(lstm_reg,self).__init__()
self.rnn = nn.LSTM(input_size,hidden_size,num_layers)
self.reg = nn.Linear(hidden_size,output_size)
def forward(self,x):
x, _ = self.rnn(x)
s,b,h = x.shape
x = x.view(s*b, h)
x = self.reg(x)
x = x.view(s,b,-1)
return x
net = lstm_reg(2,4)
net.load_state_dict(torch.load('net_params.pkl'))
data_X = data_X.reshape(-1, 1, 2) #reshape中,-1使元素变为一行,然后输出为1列,每列2个子元素
data_X = torch.from_numpy(data_X) #torch.from_numpy(): numpy中的ndarray转化成pytorch中的tensor(张量)
var_data = Variable(data_X) #转为Variable(变量)
pred_test = net(var_data) #产生预测结果
pred_test = pred_test.view(-1).data.numpy() #view(-1)输出为一行
plt.plot(pred_test, 'r', label='prediction')
plt.plot(dataset, 'b', label='real')
plt.legend(loc='best') #loc显示图像 'best'表示自适应方式
plt.show()
预测结果:

到此这篇关于Python中LSTM回归神经网络时间序列预测详情的文章就介绍到这了,更多相关Python LSTM时间序列预测内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python通过朴素贝叶斯和LSTM分别实现新闻文本分类
目录 一.项目背景 二.数据处理与分析 三.基于机器学习的文本分类–朴素贝叶斯 1. 模型介绍 2. 代码结构 3. 结果分析 四.基于深度学习的文本分类–LSTM 1. 模型介绍 2. 代码结构 3. 结果分析 五.小结 一.项目背景 本项目来源于天池⼤赛,利⽤机器学习和深度学习等知识,对新闻⽂本进⾏分类.⼀共有14个分类类别:财经.彩票.房产.股票.家居.教育.科技.社会.时尚.时政.体育.星座.游戏.娱乐. 最终将测试集的预测结果上传⾄⼤赛官⽹,可查看排名.评价标准为类别f1_score的
-
Python中利用LSTM模型进行时间序列预测分析的实现
时间序列模型 时间序列预测分析就是利用过去一段时间内某事件时间的特征来预测未来一段时间内该事件的特征.这是一类相对比较复杂的预测建模问题,和回归分析模型的预测不同,时间序列模型是依赖于事件发生的先后顺序的,同样大小的值改变顺序后输入模型产生的结果是不同的. 举个栗子:根据过去两年某股票的每天的股价数据推测之后一周的股价变化:根据过去2年某店铺每周想消费人数预测下周来店消费的人数等等 RNN 和 LSTM 模型 时间序列模型最常用最强大的的工具就是递归神经网络(recurrent neural n
-
python神经网络Keras实现LSTM及其参数量详解
目录 什么是LSTM 1.LSTM的结构 2.LSTM独特的门结构 3.LSTM参数量计算 在Keras中实现LSTM 实现代码 什么是LSTM 1.LSTM的结构 我们可以看出,在n时刻,LSTM的输入有三个: 当前时刻网络的输入值Xt: 上一时刻LSTM的输出值ht-1: 上一时刻的单元状态Ct-1. LSTM的输出有两个: 当前时刻LSTM输出值ht: 当前时刻的单元状态Ct. 2.LSTM独特的门结构 LSTM用两个门来控制单元状态cn的内容: 遗忘门(forget gate),它决定了
-
python神经网络使用tensorflow构建长短时记忆LSTM
目录 LSTM简介 1.RNN的梯度消失问题 2.LSTM的结构 tensorflow中LSTM的相关函数 tf.contrib.rnn.BasicLSTMCell tf.nn.dynamic_rnn 全部代码 LSTM简介 1.RNN的梯度消失问题 在过去的时间里我们学习了RNN循环神经网络,其结构示意图是这样的: 其存在的最大问题是,当w1.w2.w3这些值小于0时,如果一句话够长,那么其在神经网络进行反向传播与前向传播时,存在梯度消失的问题. 0.925=0.07,如果一句话有20到30个
-
Python使用LSTM实现销售额预测详解
大家经常会遇到一些需要预测的场景,比如预测品牌销售额,预测产品销量. 今天给大家分享一波使用 LSTM 进行端到端时间序列预测的完整代码和详细解释. 我们先来了解两个主题: 什么是时间序列分析? 什么是 LSTM? 时间序列分析:时间序列表示基于时间顺序的一系列数据.它可以是秒.分钟.小时.天.周.月.年.未来的数据将取决于它以前的值. 在现实世界的案例中,我们主要有两种类型的时间序列分析: 单变量时间序列 多元时间序列 对于单变量时间序列数据,我们将使用单列进行预测. 正如我们所见,只有一列,
-
Python中LSTM回归神经网络时间序列预测详情
前言: 这个问题是国际航空乘客预测问题, 数据是1949年1月到1960年12月国际航空公司每个月的乘客数量(单位:千人),共有12年144个月的数据.数据趋势: 训练程序: import numpy as np import pandas as pd import matplotlib.pyplot as plt import torch from torch import nn from torch.autograd import Variable #LSTM(Long Short-Term
-
Python中defaultdict与dict的差异详情
目录 一.问题描述 二.解决方案 三.结语 本文转自微信公众号:"算法与编程之美", 一.问题描述 在collections模块中的defauldict使用时与dict有何不同,为何我们用dict中的key值不存在时会报错,而defaudict不会报错,下面做出解答. 二.解决方案 以解决遇到的问题用来解答. 代码示例: import collections //引用collections模块 dic=collections.defaultdict(int) //利用模块中的defau
-
Python中用户输入与while循环详情
目录 一.用户输入 1.输入字符串 2.使用函数int()获取数值输入 3.求模运算符的应用 二.while循环 1.简单的while循环 2.通过用户输入退出while循环 3.使用标志 4.使用break退出循环 5.在循环中使用continue 三.使用while循环处理列表和字典 1.在列表之间移动元素 2.删除列表中所有的特定元素 3.使用用户输入来填充字典 前言: 本文的主要内容是介绍Python中用户输入与while循环,包括如何接收用户输入并进行处理,在程序满足一定的条件时让程序
-
在python中读取和写入CSV文件详情
目录 前言 1.导入CSV库 2.对CSV文件进行读写 2.1 用列表形式写入CSV文件 2.2 用列表形式读取CSV文件 2.3 用字典形式写入csv文件 2.4 用字典形式读取csv文件 结语 前言 CSV(Comma-Separated Values)即逗号分隔值,一种以逗号分隔按行存储的文本文件,所有的值都表现为字符串类型(注意:数字为字符串类型).如果CSV中有中文,应以utf-8编码读写. 1.导入CSV库 python中对csv文件有自带的库可以使用,当我们要对csv文件进行读写的
-
Pytorch 如何实现LSTM时间序列预测
开发环境说明: Python 35 Pytorch 0.2 CPU/GPU均可 1.LSTM简介 人类在进行学习时,往往不总是零开始,学习物理你会有数学基础.学习英语你会有中文基础等等. 于是对于机器而言,神经网络的学习亦可不再从零开始,于是出现了Transfer Learning,就是把一个领域已训练好的网络用于初始化另一个领域的任务,例如会下棋的神经网络可以用于打德州扑克. 我们这讲的是另一种不从零开始学习的神经网络--循环神经网络(Recurrent Neural Network, RNN
-
时间序列预测中的数据滑窗操作实例(python实现)
目录 撰写背景 什么是数据滑窗 代码实现 单特征时间序列 多特征时间序列 注意事项 总结 撰写背景 面向数据分析的小白,水平有限,错误难免,欢迎指正. 什么是数据滑窗 进行机器学习时,一般都要涉及到划分训练集和测试集的步骤.特别地,在做数据预测时,一般把预测的依据(也就是历史数据)称作X,把需要预测的数据称为y.即首先把原始数据划分为train_X, train_y这两个训练数据集和test_X, test_y这两个测试数据集. 对于时间序列数据的预测,往往是建立由好几个历史数据预测下一时刻的未
-
详解用Python进行时间序列预测的7种方法
数据准备 数据集(JetRail高铁的乘客数量)下载. 假设要解决一个时序问题:根据过往两年的数据(2012 年 8 月至 2014 年 8月),需要用这些数据预测接下来 7 个月的乘客数量. import pandas as pd import numpy as np import matplotlib.pyplot as plt df = pd.read_csv('train.csv') df.head() df.shape 依照上面的代码,我们获得了 2012-2014 年两年每个小时的乘
-
Python机器学习应用之基于BP神经网络的预测篇详解
目录 一.Introduction 1 BP神经网络的优点 2 BP神经网络的缺点 二.实现过程 1 Demo 2 基于BP神经网络的乳腺癌分类预测 三.Keys 一.Introduction 1 BP神经网络的优点 非线性映射能力:BP神经网络实质上实现了一个从输入到输出的映射功能,数学理论证明三层的神经网络就能够以任意精度逼近任何非线性连续函数.这使得其特别适合于求解内部机制复杂的问题,即BP神经网络具有较强的非线性映射能力. 自学习和自适应能力:BP神经网络在训练时,能够通过学习自动提取输