Mysql分组查询每组最新一条数据的三种实现方法
目录
- 前言
- 注意事项
- 准备SQL
- 错误原因
- 方法一
- 方法二(适用于自增ID和创建时间排序一致)
- 方法三(适用于自增ID和创建时间排序一致)
- 总结
- MAX()函数和MIN()这一类函数和GROUP BY配合使用存在问题
前言
在写报表功能时遇到一个需要根据用户id分组查询最新一条钱包明细数据的需求,在写sql测试时遇到一个有趣的问题,开始使用子查询根据时间倒序+group by customer_id发现查询出来的数据一直都是最旧的一条,而不是我需要的最新一条数据我明明已经倒序排了,后来总结出了三种解决方案如下。
注意事项
- 数据库版本 Mysql5.7+
- 执行 GROUP BY 语句的时候出现 sql_mode=only_full_group_by 解决方法(这里是Mysql8的解决方案,Mysql5.7也差不多自行百度即可)
1、执行 select @@sql_mode; 查看sql模式
select @@sql_mode;

2、将sql_mode中的only_full_group_by模式剔除 重新设置sql_mode值,如果是使用JDBC连接需要重启项目才能生效。
set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION'; set session sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION';
准备SQL
这里模拟一个sql
DROP TABLE IF EXISTS `customer_wallet_detail`; CREATE TABLE `customer_wallet_detail` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `customer_id` bigint(20) NULL DEFAULT NULL COMMENT '用户ID', `happen_amount` varchar(15) NULL DEFAULT '0' COMMENT '发生金额 带'-'号的代表扣款', `balance_amount` varchar(15) NULL DEFAULT '0' COMMENT '可用余额', `create_time` bigint(20) NULL DEFAULT NULL COMMENT '发生时间', PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB COMMENT = '用户钱包明细' ; INSERT INTO `test`.`customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `happen_time`) VALUES (1, 1, '100', '100', 1670300656630); INSERT INTO `test`.`customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `happen_time`) VALUES (2, 1, '-10', '90', 1670300656640); INSERT INTO `test`.`customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `happen_time`) VALUES (3, 1, '5', '95', 1670300656650); INSERT INTO `test`.`customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `happen_time`) VALUES (4, 3, '998', '998', 1670300656660); INSERT INTO `test`.`customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `happen_time`) VALUES (5, 3, '-100', '898', 1670300656670); INSERT INTO `test`.`customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `happen_time`) VALUES (6, 3, '-98', '800', 1670300656680); INSERT INTO `test`.`customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `happen_time`) VALUES (7, 2, '666', '666', 1670300656690); INSERT INTO `test`.`customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `happen_time`) VALUES (8, 2, '-66', '600', 1670300656695); INSERT INTO `test`.`customer_wallet_detail`(`id`, `customer_id`, `happen_amount`, `balance_amount`, `happen_time`) VALUES (9, 2, '-600', '0', 1670300656699);
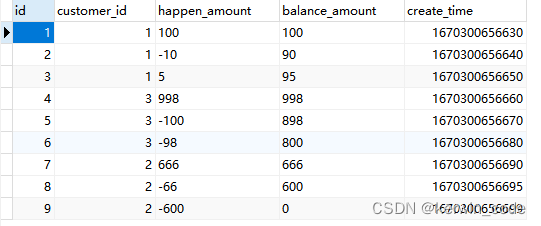
错误查询
SELECT * FROM ( SELECT * FROM customer_wallet_detail ORDER BY create_time DESC ) t1 GROUP BY t1.customer_id;
错误原因
在mysql5.7以及之后的版本,如果GROUP BY的子查询中包含ORDER BY,但是 GROUP BY 不与 LIMIT 配合使用,ORDER BY会被忽略掉,所以子查询在 GROUP BY 时排序不会生效,可能是因为子查询大多数是作为一个结果给主查询使用,所以子查询不需要排序。
方法一
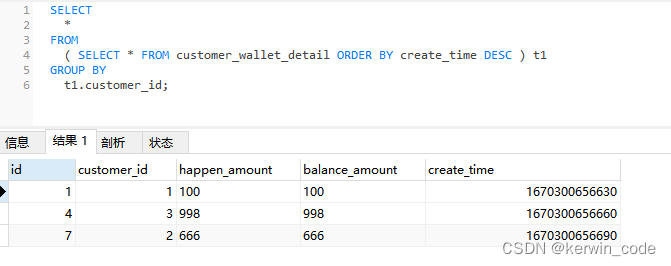
鉴于以上的原因我们可以添加上 LIMIT 条件来实现功能。
PS:这个LIMIT的数量可以先自行 COUNT 出你要遍历的数据条数(这个数据条数是所有满足查询条件的数据合,我这里共9条数据)
SELECT * FROM ( SELECT * FROM customer_wallet_detail ORDER BY create_time DESC ) t1 GROUP BY t1.customer_id;
方法二(适用于自增ID和创建时间排序一致)
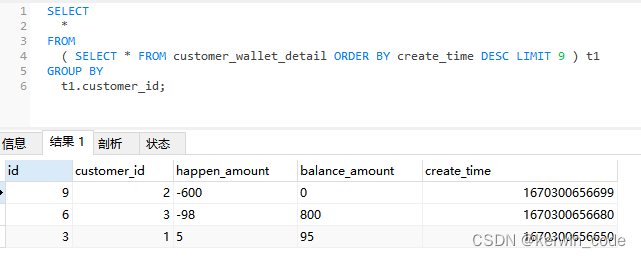
方法一需要先 COUNT 查询然后将查询结果设置到 LIMIT 条件中比较麻烦,这里还可以使用 MAX() 函数来实现该功能。
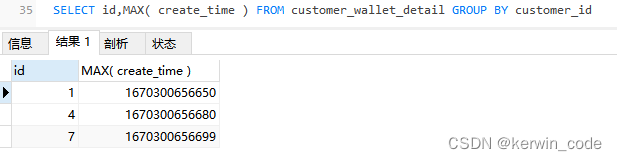
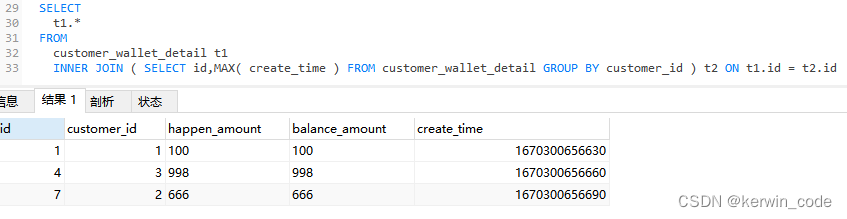
PS:因为我这里的业务数据是有序插入的,使用主键自增id和create_time结果是一样的而且使用id查询效率更高,如果没有唯一且有序的id可以替代create_time那么就用方案一,不能直接使用 SELECT id,MAX(create_time) 这种操作来获取最新一条数据id原因在总结中有详细描述。
SELECT * FROM customer_wallet_detail WHERE id IN ( SELECT MAX( id ) FROM customer_wallet_detail GROUP BY customer_id ) ORDER BY customer_id;
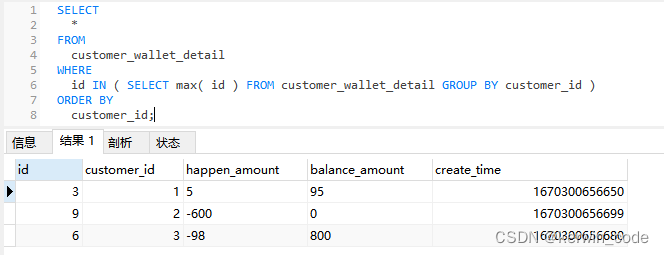
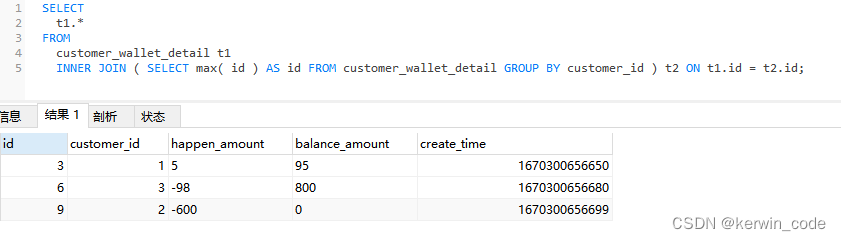
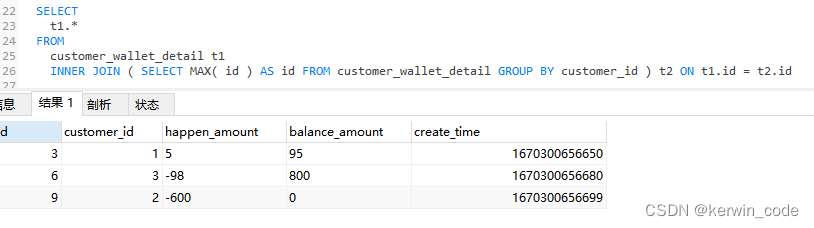
方法三(适用于自增ID和创建时间排序一致)
方法三和方法二实现逻辑基本一致只是将IN查询替换成了连接查询,本地20w条数据测试 方法三比方法二性能提升50%,有兴趣的可以增大数据集测试后续性能变化。
SELECT t1.* FROM customer_wallet_detail t1 INNER JOIN ( SELECT MAX( id ) AS id FROM customer_wallet_detail GROUP BY customer_id ) t2 ON t1.id = t2.id
总结
结合我的业务经过测试,目前看来方案三是最合适的,sql简单性能适中,方案一比方案二性能更差而且实现麻烦,最终选择那个方案主要看业务而定。
MAX()函数和MIN()这一类函数和GROUP BY配合使用存在问题
MAX()函数和MIN()这一类函数和GROUP BY配合使用,GROUP BY拿到的数据永远都是这个分组排序最上面的一条,而MAX()函数和MIN()这一类函数会将这个分组中最大 | 最小的值取出来,这样会导致查询出来的数据对应不上。
正确查询:
错误查询:这里的确拿到每个分组最新创建时间了但是拿的数据id还是排序的第一条
到此这篇关于Mysql分组查询每组最新一条数据的三种实现方法的文章就介绍到这了,更多相关Mysql分组查询每组最新数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
基于mysql实现group by取各分组最新一条数据
前言: group by函数后取到的是分组中的第一条数据,但是我们有时候需要取出各分组的最新一条,该怎么实现呢? 本文提供两种实现方式. 一.准备数据 http://note.youdao.com/noteshare?id=dba748092a619be0a8f160ccf6e25a5f&sub=FD4C1C7823CA440DB360FEA3B4A905CD 二.三种实现方式 1)先order by之后再分组: SELECT * FROM (SELECT * from tb_dept ORDE
-
MySQL 多表关联一对多查询实现取最新一条数据的方法示例
本文实例讲述了MySQL 多表关联一对多查询实现取最新一条数据的方法.分享给大家供大家参考,具体如下: MySQL 多表关联一对多查询取最新的一条数据 遇到的问题 多表关联一对多查询取最新的一条数据,数据出现重复 由于历史原因,表结构设计不合理:产品告诉我说需要导出客户信息数据,需要导出客户的 所属行业,纳税性质 数据:但是这两个字段却在订单表里面,每次客户下单都会要求客户填写:由此可知,客户数据和订单数据是一对多的关系:那这样的话,问题就来了,我到底以订单中的哪一条数据为准呢?经过协商后一致同
-

MySQL分表实现上百万上千万记录分布存储的批量查询设计模式详解
我们知道可以将一个海量记录的 MySQL 大表根据主键.时间字段,条件字段等分成若干个表甚至保存在若干服务器中. 唯一的问题就是跨服务器批量查询麻烦,只能通过应用程序来解决.谈谈在Java中的解决思路.其他语言原理类似.这里说的分表不是 MySQL 5.1 的 partition,而是人为把一个表分开存在若干表或不同的服务器.1. 应用程序级别实现见示意图 electThreadManager 分表数据查询管理器它为分表的每个database or server 建立一个 thread pool
-
php+mysqli批量查询多张表数据的方法
本文实例讲述了php+mysqli批量查询多张表数据的方法.分享给大家供大家参考.具体实现方法如下: 注意这里使用到了两个新的函数multi_query与store_result,具体代码如下: 复制代码 代码如下: <?php //1.创建数据库连接对象 $mysqli = new MySQLi("localhost","root","123456","liuyan"); if($mysqli->connect_
-
mysql分组取每组前几条记录(排名) 附group by与order by的研究
--按某一字段分组取最大(小)值所在行的数据 复制代码 代码如下: /* 数据如下: name val memo a 2 a2(a的第二个值) a 1 a1--a的第一个值 a 3 a3:a的第三个值 b 1 b1--b的第一个值 b 3 b3:b的第三个值 b 2 b2b2b2b2 b 4 b4b4 b 5 b5b5b5b5b5 */ --创建表并插入数据: 复制代码 代码如下: create table tb(name varchar(10),val int,memo varchar(20)
-
MySQL 分组查询和聚合函数
概述 相信我们经常会遇到这样的场景:想要了解双十一天猫购买化妆品的人员中平均消费额度是多少(这可能有利于对商品价格区间的定位):或者不同年龄段的化妆品消费占比是多少(这可能有助于对商品备货量的预估). 这个时候就要用到分组查询,分组查询的目的是为了把数据分成多个逻辑组(购买化妆品的人员是一个组,不同年龄段购买化妆品的人员也是组),并对每个组进行聚合计算的过程:. 分组查询的语法格式如下: select cname, group_fun,... from tname [where conditio
-
MySQL 分组查询的优化方法
MySQL 在处理 GROUP BY 和 DISTINCT 查询的方式在大多数情况下类似,事实上,在优化过程中有时候会把在这两种方式中转换.两类查询都能够从索引中受益,通常,这也是优化这两种查询最为重要的方式. 在无法使用索引时,MySQL 对于 GROUP BY 查询有两种策略:使用临时表或者 filesort 执行分组.对于给定的查询,两种方式都没法更高效.我们可以通过配置 SQL_BIG_RESULT 和 SQL_SMALL_RESULT 来指定优化器选择其中一个方式. 通常,对查询表的i
-
mysql通过group by分组取最大时间对应数据的两种有效方法
1.项目记录表project_record的结构和数据如下: 以下为项目记录表project_record的所有数据.project_id为项目Id,on_project_time为上项目时间.(每一条数据代表着上某个项目(project_id)的时间(on_project_time)记录) 2.我们的需求是:取出每个项目中最大上项目时间对应的那条数据.(即根据project_id分组,取出每组中最大的on_project_time对应的数据.)上方红框是我们要查出的数据. 3.错误代码: SE
-
Spring Date jpa 获取最新一条数据的实例代码
#Repository import test.demo.domain.entity.TestEntity; import org.springframework.data.jpa.repository.support.JpaRepositoryImplementation; import org.springframework.stereotype.Repository; @Repository public interface TestEntityRepository extends Jpa
-
mysql实现合并同一ID对应多条数据的方法
本文实例讲述了mysql实现合并同一ID对应多条数据的方法.分享给大家供大家参考,具体如下: 如 : CREATE TABLE `c_classuser_tab` ( `Id` int(11) NOT NULL AUTO_INCREMENT, `Classid` int(11) DEFAULT NULL, `Username` varchar(100) DEFAULT NULL, `studentid` varchar(100) DEFAULT NULL, `College` varchar(1
-
PHP使用PDO创建MySQL数据库、表及插入多条数据操作示例
本文实例讲述了PHP使用PDO创建MySQL数据库.表及插入多条数据操作.分享给大家供大家参考,具体如下: 创建 MySQL 数据库: <?php $servername = "localhost"; $username = "username"; $password = "password"; try { $conn = new PDO("mysql:host=$servername", $username, $pas
-
mybatis mysql delete in操作只能删除第一条数据的方法
出现的Bug 如图,我开始复制delete语句和参数到数据库执行,删除两条数据,但是后台执行确只删除一条数据,当时表示一脸懵逼 分析原因 分析原因 如图,正确的参数传值应该是这样的,聪明的同学,应该就知道哪里错了 解决问题 解决问题 我就不贴开始的代码了,直接贴解决bug的代码 mybatis中的代码 <!-- 批量删除--> <delete id="deleteByIds" parameterType="int[]"> <![CD
-
MySQL数据库10秒内插入百万条数据的实现
首先我们思考一个问题: 要插入如此庞大的数据到数据库,正常情况一定会频繁地进行访问,什么样的机器设备都吃不消.那么如何避免频繁访问数据库,能否做到一次访问,再执行呢? Java其实已经给了我们答案. 这里就要用到两个关键对象:Statement.PrepareStatement 我们来看一下二者的特性: 要用到的BaseDao工具类 (jar包 / Maven依赖) (Maven依赖代码附在文末)(封装以便于使用) 注:(重点)rewriteBatchedStatements=true,一次插入