Python实现在Excel中绘制可视化大屏的方法详解
目录
- 数据清洗
- 绘制图表
- 生成可视化大屏
大家新年好哇,今天小编来给大家分享如何在Excel文档当中来绘制可视化图表,并且制作一个可视化大屏,非常的容易,这里我们会用到openpyxl模块,那么首先第一步便是调用该模块来读取Excel文件,代码如下
# 读取Excel文档并且指定工作表的名称 file_name = 'Bike_Sales_Playground.xlsx' df = pd.read_excel(file_name,sheet_name='bike_buyers')
当然为了保险起见,我们这里还是拷贝一份源数据,并且新建一个新的工作表,代码如下
# 新建一张工作表
with pd.ExcelWriter(file_name,#文档的名称
engine='openpyxl',#调用模块的名称
mode='a',#添加的模式
if_sheet_exists="replace" #如果已经存在,就替换掉
) as writer:
df.to_excel(writer, sheet_name='Working_Sheet',index = False)# 设置Index为False
# 从新的工作表当中来读取数据
df = pd.read_excel(file_name,sheet_name='Working_Sheet')
数据清洗
下一步我们进行数据的清洗,例如去掉重复值、针对一些数值做一些替换,代码如下
# 去掉重复值
df.drop_duplicates(keep='first', inplace=True, ignore_index=False)
# 针对婚姻状况这一列,“已婚”替换成“M”,“单身”替换成“S”
df['Marital Status'] = df['Marital Status'].replace('M','Married').replace('S','Single')
# 针对性别这一列,“男性”替换成“F”,而“女性”替换成“M”
df['Gender'] = df['Gender'].replace('F','Female').replace('M','Male')
# 查看表格的前5行
df.head()
# 年龄数值的处理
df['Age brackets'] = df['Age'].apply(lambda x: 'Less than 30' if x<=30 else('Greater than 55' if x>55 else '31 to 55'))
# 通勤距离的数值的替换
df['Commute Distance'] = df['Commute Distance'].replace('10+ Miles','More than 10 Miles')
output
ID Marital Status Gender ... Age Purchased Bike Age brackets
0 12496 Married Female ... 42 No 31 to 55
1 24107 Married Male ... 43 No 31 to 55
2 14177 Married Male ... 60 No Greater than 55
3 24381 Single Male ... 41 Yes 31 to 55
4 25597 Single Male ... 36 Yes 31 to 55
绘制图表
接下来我们尝试来绘制几张可视化图表,下面所示的代码绘制的是柱状图,而绘制其余两张折线图的代码与下面是雷同的
# 透视表1
# 制作数据透视表
avg_gender_income_df = np.round(pd.pivot_table(bike_df,
values = 'Income',
index = ['Gender'],
columns = ['Purchased Bike'],
aggfunc = np.mean
),2)
# 将数据透视表放入Excel表格中,并且指定工作表
with pd.ExcelWriter(file_name,#工作表的名称
engine='openpyxl',#引擎的名称
mode='a',#Append模式
if_sheet_exists="replace" #如果已经存在,就替换掉
) as writer:
avg_gender_income_df.to_excel(writer, sheet_name='Average_Gender_Income')
# 加载文档,并且指定工作表
wb = load_workbook(file_name)
sheet = wb['Average_Gender_Income']
# 创建柱状图
chart1 = BarChart()
chart1.type = "col"
chart1.style = 10
chart1.title = "基于性别与消费数据之下的平均收入"
chart1.y_axis.title = '性别'
chart1.x_axis.title = '收入'
# 将绘制出来的柱状图放在单元格中去
data1 = Reference(sheet, min_col=2, min_row=1, max_row=3, max_col=3)#Including Headers
cats1 = Reference(sheet, min_col=1, min_row=2, max_row=3)#Not including headers
chart1.add_data(data1, titles_from_data=True)
chart1.dataLabels = DataLabelList()
chart1.dataLabels.showVal = True
chart1.set_categories(cats1)
chart1.shape = 4
sheet.add_chart(chart1, "A10")
wb.save(file_name)
output

生成可视化大屏
我们尝试将绘制完成的图表生成可视化大屏,代码如下
# 创建一个空的DataFrame表格
title_df = pd.DataFrame()
# 将结果放入至Excel文件当中去
with pd.ExcelWriter(file_name,#工作表的名称
engine='openpyxl',#引擎的名称
mode='a',#Append模式
if_sheet_exists="replace" #如果已经存在,就替换掉
) as writer:
title_df.to_excel(writer, sheet_name='Dashboard')
# 加载文档,指定工作表是哪个
wb = load_workbook(file_name)
sheet = wb['Dashboard']
for x in range(1,22):
sheet.merge_cells('A1:R4')
cell = sheet.cell(row=1, column=1)
cell.value = 'Bike Sales Dashboard'
cell.alignment = Alignment(horizontal='center', vertical='center')
cell.font = Font(b=True, color="F8F8F8",size = 46)
cell.fill = PatternFill("solid", fgColor="2591DB")
# 将绘制出来的图表放置到Excel文档中
sheet.add_chart(chart1,'A5')
sheet.add_chart(chart2,'J5')
chart3.width = 31
sheet.add_chart(chart3,'A20')
wb.save(file_name)
最后我们来看一下绘制出来的结果,如下所示
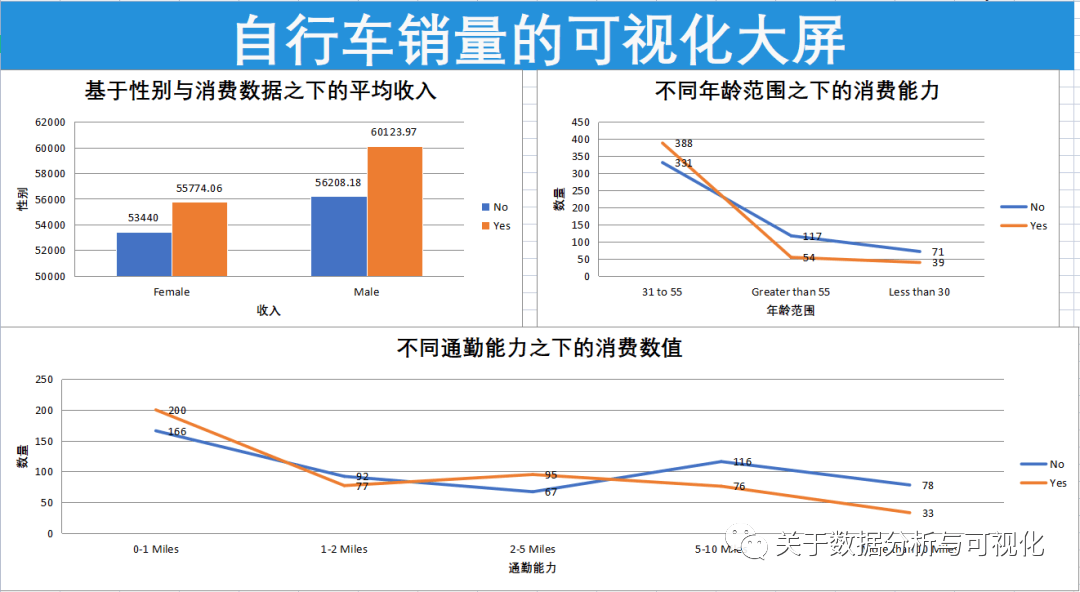
最后的最后,我们将上面所有的代码封装成一个函数,方便我们来调用,代码如下
import Bikes_Sales_Report_Automation as auto
# 填入文件的名称
auto.automate_excel_dashboard('Bike_Sales_Playground.xlsx')
到此这篇关于Python实现在Excel中绘制可视化大屏的方法详解的文章就介绍到这了,更多相关Python Excel绘制可视化大屏内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python操作Excel神器openpyxl使用教程(超详细!)
目录 前言 新建并写入文件 打开并读取文件 工作簿对象 工作表对象 单元格读取 单元格对象 单元格样式 列宽与行高 插入和删除行和列 综合写入实践 合并表格 拆分表格 作业提交情况检测 总结 前言 openpyxl是Python下的Excel库,它能够很容易的对Excel数据进行读取.写入以及样式的设置,能够帮助我们实现大量的.重复的Excel操作,提高我们的办公效率,实现Excel办公自动化. 安装方法:pip install openpyxl 中文文档:https://www.osgeo.c
-
Python读取大量Excel文件并跨文件批量计算平均值的方法
本文介绍基于Python语言,实现对多个不同Excel文件进行数据读取与平均值计算的方法~ 我们推荐学习python书籍 首先,让我们来看一下具体需求:目前有一个文件夹,其中存放了大量Excel文件:文件名称是每一位同学的名字,即文件名称没有任何规律. 而每一个文件都是一位同学对全班除了自己之外的其他同学的各项打分,我们以其中一个Excel文件为例来看: 可以看到,全班同学人数(即表格行数)很多.需要打分的项目(即表格列数)有11个(不算总分):同时,由于不能给自己打分,导致每一份表
-
Python中各类Excel表格批量合并问题的实现思路与案例
目录 基本思路: 遍历文件示例 无样式单文件合并示例 无样式同名多sheet表格合并 保留表头样式同名多sheet表格合并 图形化界面选择指定的目录 在日常工作中,可能会遇到各类表格合并的需求.这类需求只要搞懂核心原理都很简单,本质都是万变不离其宗,相信大部分读者都能解决大部分需求. 基本思路: 遍历需要被合并的文件 读取数据,并合并数据(使用pandas最简单便捷) 保存数据 对样式无要求,使用Pandas对象直接写出 对样式有要求,使用openpyxl加载模板 要求样式与原始表格完全一致,使
-
Python实现在Excel中绘制可视化大屏的方法详解
目录 数据清洗 绘制图表 生成可视化大屏 大家新年好哇,今天小编来给大家分享如何在Excel文档当中来绘制可视化图表,并且制作一个可视化大屏,非常的容易,这里我们会用到openpyxl模块,那么首先第一步便是调用该模块来读取Excel文件,代码如下 # 读取Excel文档并且指定工作表的名称 file_name = 'Bike_Sales_Playground.xlsx' df = pd.read_excel(file_name,sheet_name='bike_buyers') 当然为了保险起
-

Python实现向PPT中插入表格与图片的方法详解
目录 插入表格 插入图片 上一章节学习了如何在 PPT 中添加段落以及自定义段落(书写段落的内容以及样式的调整),今天的章节将学习在 PPT 中插入表格与图片以及在表格中插入内容. 废话不多说了,直接进入主题. 插入表格 首先还是要生成 PPT 对象: ppt = Presentation() 通过 Presentation() 实例化一个 ppt 对象(Presentation 可以通过 python-pptx 直接拿过来使用) 选择布局: layout = ppt.slide_layout[
-
Python实现在图像中隐藏二维码的方法详解
目录 一.前言 二.隐写 三.位平面分解 3.1 图像 3.2 位平面 3.3 位平面分解 3.4 位平面合成 四.图像隐写 一.前言 在某个App中有一个加密水印的功能,当帖子的主人开启了之后.如果有人截图,那么这张截图中就是添加截图用户.帖子ID.截图时间等信息,而且我们无法用肉眼看出这些水印. 这可以通过今天要介绍的隐写技术来实现,我们会通过这种技术,借助Python语言和OpenCV模块来实现在图像中隐藏二维码的操作.而且这个二维码无法通过肉眼看出. 二.隐写 隐写是一种类似于加密却又不
-
Python编程对列表中字典元素进行排序的方法详解
本文实例讲述了Python编程对列表中字典元素进行排序的方法.分享给大家供大家参考,具体如下: 内容目录: 1. 问题起源 2. 对列表中的字典元素排序 3. 对json进行比较(忽略列表中字典的顺序) 一.问题起源 json对象a,b a = '{"ROAD": [{"id": 123}, {"name": "no1"}]}' b = '{"ROAD": [{"name": "
-
基于python实现在excel中读取与生成随机数写入excel中
具体要求是:在一份已知的excel表格中读取学生的学号与姓名,再将这些数据放到新的excel表中的第一列与第二列,最后再生成随机数作为学生的考试成绩. 首先要用到的数据库有:xlwt,xlrd,random这三个数据库. 命令如下: import xlwt import xlrd import random 现有一份表格内容如下图: 现在我们需要提取这其中的B1-C14. (提示:在对这份电子表格进行操作的时候,要使用到这个电子表格的地址,即表格的储存位置.) excel=xlrd.open_w
-
python实现对excel中需要的数据的单元格填充颜色
前言: 一般处理数据使用的是pandas和numpy库,但是填充单元格颜色需要在excel中,使用的是openpyxl库,所以不能直接达到我们的需求,需要进行两个库的链接使用,先说下openpyxl填充色,pandas是直接读取数据,但是openpyxl则不是,必须要sheet处于active状态,而且必须进行sheet选择才可以读取数据 import openpyxl from openpyxl import load_workbook # 比如打开test.xlsx wb = load_wo
-
Python实现对excel文件列表值进行统计的方法
本文实例讲述了Python实现对excel文件列表值进行统计的方法.分享给大家供大家参考.具体如下: #!/usr/bin/env python #coding=gbk #此PY用来统计一个execl文件中的特定一列的值的分类 import win32com.client filename=raw_input("请输入要统计文件的详细地址:") flag=0 #用于判断文件 名如果不带'日'就为 0 if '\xc8\xd5' in filename:flag=1 print 50*'
-
Python高效处理大文件的方法详解
目录 开始 处理文本 串行处理 多进程处理 并行处理 并行批量处理 将文件分割成批 运行并行批处理 tqdm 并发 结论 为了进行并行处理,我们将任务划分为子单元.它增加了程序处理的作业数量,减少了整体处理时间. 例如,如果你正在处理一个大的CSV文件,你想修改一个单列.我们将把数据以数组的形式输入函数,它将根据可用的进程数量,一次并行处理多个值.这些进程是基于你的处理器内核的数量. 在这篇文章中,我们将学习如何使用multiprocessing.joblib和tqdm Python包减少大文件
-
对python 中class与变量的使用方法详解
python中的变量定义是很灵活的,很容易搞混淆,特别是对于class的变量的定义,如何定义使用类里的变量是我们维护代码和保证代码稳定性的关键. #!/usr/bin/python #encoding:utf-8 global_variable_1 = 'global_variable' class MyClass(): class_var_1 = 'class_val_1' # define class variable here def __init__(self, param): self
-
对python遍历文件夹中的所有jpg文件的实例详解
python发现文件夹下所有的jpg文件,并且安装文件排放的顺序输出 glob模块是最简单的模块之一,内容非常少.用它可以查找符合特定规则的文件路径名.跟使用windows下的文件搜索差不多.查找文件只用到三个匹配符:"*", "?", "[]"."*"匹配0个或多个字符:"?"匹配单个字符:"[]"匹配指定范围内的字符,如:[0-9]匹配数字. glob.glob 返回所有匹配的文件路