Pandas读存JSON数据操作示例详解
目录
- 引言
- 读取json数据
- 模拟数据
- 参数orident
- orident="split"
- orient="records"
- orient="index"
- orient="columns"
- orient="values"
- to_json
引言
本文介绍的如何使用Pandas来读取各种json格式的数据,以及对json数据的保存

读取json数据
使用的是pd.read_json函数,见官网:pandas.pydata.org/docs/refere…
pandas.read_json( path_or_buf=None, # 文件路径 orient=None, # 取值:split、records、index、columns、values typ='frame', # 要恢复的对象类型(系列或框架),默认'框架'. dtype=None, # boolean或dict,默认为True convert_axes=None, convert_dates=True, keep_default_dates=True, numpy=False, precise_float=False, date_unit=None, encoding=None, # 编码 lines=False, # 布尔值,默认为False,每行读取该文件作为json对象 chunksize=None, # 分块读取大小 compression='infer', nrows=None, storage_options=None)
模拟数据
模拟了一份数据,vscode打开内容:

可以看到默认情况下的读取效果:

主要有下面几个特点:
- 第一层级字典的键当做了DataFrame的字段
- 第二层级的键默认当做了行索引
下面重点解释下参数orident
参数orident
取值可以是:split、records、index、columns、values
orident="split"
json文件的key的名字只能为index,cloumns,data;不多也不能少。
split' : dict like {index -> [index], columns -> [columns], data -> [values]}
In [3]:
data1 = '{"index":[1,2],"columns":["name","age"],"data":[["xiaoming",28], ["zhouhong",20]]}'
In [4]:
df1 = pd.read_json(data1, orient="split") df1
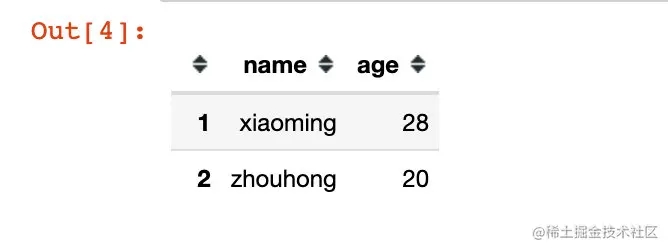
结果表明:
- index:当做行索引
- columns:列名
- data:具体的取值
如果我们改变其中一个key,比如data换成information就报错了:


orient="records"
当orient="records"的时候,数据是以字段 + 取值的形式存放的。
‘records' : list like [{column -> value}, … , {column -> value}]
In [7]:
data2 = '[{"name":"Peter","sex":"male","age":20},{"name":"Tom","age":27},{"sex":"male"}]'
In [8]:
df2 = pd.read_json(data2, orient="records") df2

生成数据的特点:
- 列表中元素是以字典的形式存放
- 列表中每个元素(字典)的key,如果没有出现则取值为NaN
orient="index"
当orient="index"的时候,数据是以行的形式来存储。
dict like {index -> {column -> value}}
In [9]:
data3 = '{"id1":{"name":"Mike","age":20,"sex":"male","score":80},"id2":{"name":"Jack","sex":"female","score":90}}'
In [10]:
df3 = pd.read_json(data3, orient="index") df3

- 每个id存放一条数据
- 未出现的key取值为NaN
orient="columns"
在这种情况下数据是以列的形式来存储的。
dict like {column -> {index -> value}}
In [11]:
data4 = '{"sex":{"id1":"Peter","id2":"Tom","id3":"Jimmy"},"age":{"id1": 20,"id3":28}}'
In [12]:
df4 = pd.read_json(data4, orient="columns") df4
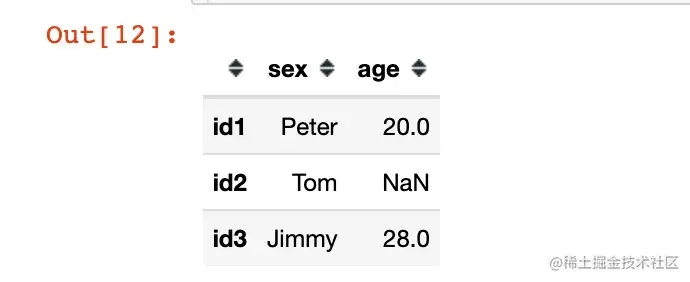
如果我们对上面的结果实施转置(两种方法):

我们会发现这个结果和orient="index"的读取结果是相同的:

orient="values"
在这种情况下,数据是以数组的形式存在的:
‘values' : just the values array
In [16]:
data5 = '[["深圳",2000],["广州",1900],["北京",2500]]'
In [17]:
df5 = pd.read_json(data5, orient="values") df5

对生成的列名进行重新命名:

to_json
将DataFrame数据保存成json格式的文件
DataFrame.to_json(path_or_buf=None, # 路径
orient=None, # 转换类型
date_format=None, # 日期转换类型
double_precision=10, # 小数保留精度
force_ascii=True, # 是否显示中文
date_unit='ms', # 日期显示最小单位
default_handler=None,
lines=False,
compression='infer',
index=True, # 是否保留行索引
indent=None, # 空格数
storage_options=None)
官网学习地址:
pandas.pydata.org/docs/refere…
1、默认保存
df.to_json("df_to_json_1.json", force_ascii=True) # 不显示中文
显示结果为一行数据,且存在unicode编码,中文无法显示:
{"sex":{"Jimmy":"male","Tom":"female","Jack":"male","Mike":"female"},"age":{"Jimmy":20,"Tom":18,"Jack":29,"Mike":26},"height":{"Jimmy":187,"Tom":167,"Jack":178,"Mike":162},"address":{"Jimmy":"\u6df1\u5733","Tom":"\u4e0a\u6d77","Jack":"\u5317\u4eac","Mike":"\u5e7f\u5dde"}}
2、显示中文
df.to_json("df_to_json_2.json", force_ascii=False) # 显示中文
中文能够正常显示:
{"sex":{"Jimmy":"male","Tom":"female","Jack":"male","Mike":"female"},"age":{"Jimmy":20,"Tom":18,"Jack":29,"Mike":26},"height":{"Jimmy":187,"Tom":167,"Jack":178,"Mike":162},"address":{"Jimmy":"深圳","Tom":"上海","Jack":"北京","Mike":"广州"}}
3、不同的orient显示 + 换行(indent参数)
df.to_json("df_to_json_3.json", force_ascii=False, orient="index",indent=4)
# index + 换行
显示结果中键为name信息:
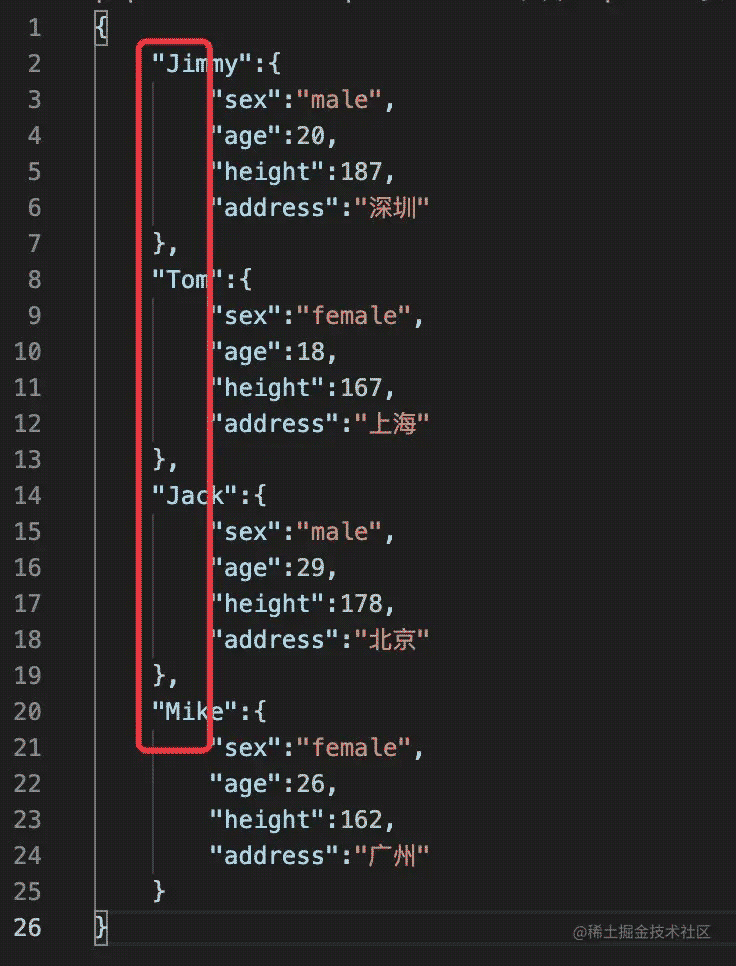
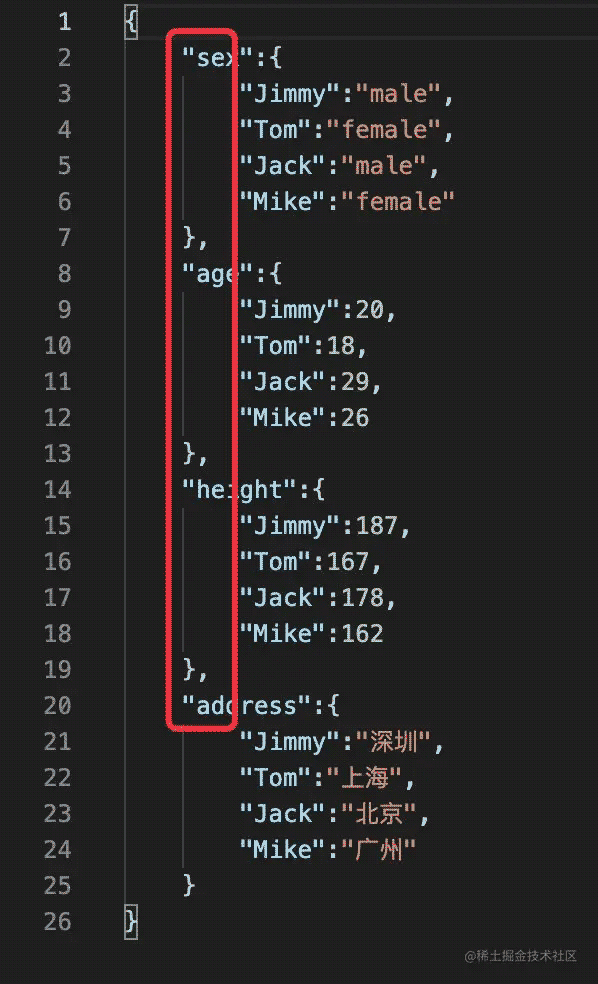
4、改变index
df.to_json("df_to_json_4.json", force_ascii=False, orient="columns",indent=4) # columns + 换行
以上就是Pandas读存JSON数据操作示例详解的详细内容,更多关于Pandas读存JSON数据的资料请关注我们其它相关文章!
相关推荐
-
pandas.DataFrame.to_json按行转json的方法
最近需要将csv文件转成DataFrame并以json的形式展示到前台,故需要用到Dataframe的to_json方法 to_json方法默认以列名为键,列内容为值,形成{col1:[v11,v21,v31-],col2:[v12,v22,v32],-}这种格式,但有时我们需要按行来转为json,形如这种格式[row1:{col1:v11,col2:v12,col3:v13-},row2:{col1:v21,col2:v22,col3:v23-}] 通过查找官网我们可以看到to_json方法有
-
解决Pandas to_json()中文乱码,转化为json数组的问题
问题出现与解决 Pandas进行数据处理之后,假如想将其转化为json,会出现一个bug,就是中文文字是以乱码存储的,也就是\uXXXXXX的形式,翻了翻官网文档,查了源码的参数,(多谢网友提醒)需要设置js001 = df1.to_json(force_ascii=False),即可显示中文编码 以下是原文的额外内容,DataFrame 转化为json数组 于是决定自己写一个.首先用demojson的类库尝试了一下,不行,依旧编码问题.之后考虑python 原生的 json 应该有编码转换功能
-
Pandas常用的读取和保存数据的函数使用(csv,mysql,json,excel)
pandas 是基于NumPy 的一种工具,该工具是为解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具.Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis).pandas提供了大量能使我们快速便捷地处理数据的函数和方法.它是使Python成为强大而高效的数据分析环境的重要因素之一.pandas的IO工具支持非常多的数据输入输出方式.包括csv.json.Excel.数据库等. 本
-
对pandas处理json数据的方法详解
今天展示一个利用pandas将json数据导入excel例子,主要利用的是pandas里的read_json函数将json数据转化为dataframe. 先拿出我要处理的json字符串: strtext='[{"ttery":"min","issue":"20130801-3391","code":"8,4,5,2,9","code1":"297734529
-
Python基于pandas实现json格式转换成dataframe的方法
本文实例讲述了Python基于pandas实现json格式转换成dataframe的方法.分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #!python3 import re import json from bs4 import BeautifulSoup import pandas as pd import requests import os from pandas.io.json import json_normalize class image_str
-

Pandas读存JSON数据操作示例详解
目录 引言 读取json数据 模拟数据 参数orident orident="split" orient="records" orient="index" orient="columns" orient="values" to_json 引言 本文介绍的如何使用Pandas来读取各种json格式的数据,以及对json数据的保存 读取json数据 使用的是pd.read_json函数,见官网:pandas.p
-
GO文件创建及读写操作示例详解
目录 三种文件操作比较 ioutil ioutil.ReadFile读 ioutil.WriteFile 写 ioutil.ReadAll 读 ioutil.ReadDir 查看路径下目录信息 ioutil.TempDir 创建临时目录 ioutil.TempFile 创建临时文件 os.file 方法 os.OpenFile() 创建文件 写入数据三种方式 第一种-WriteString( )函数 第二种-Write( )函数 第三种-WriteAt( )函数 读取文件 Read 读取文件 按
-
Python获取时间的操作示例详解
目录 获得当前时间时间戳 获取当前时间 获取昨天日期 生成日历 计算每个月天数 计算3天前并转换为指定格式 获取时间戳的旧时间 获取时间并指定格式 pandas 每日一练 21读取本地EXCEL数据 22查看df数据前5行 23将popularity列数据转换为最大值与最小值的平均值 24将数据根据project进行分组并计算平均分 25将test_time列具体时间拆分为两部分(一半日期,一半时间) 获得当前时间时间戳 # 注意时区的设置 import time # 获得当前时间时间戳 now
-
对pandas的算术运算和数据对齐实例详解
pandas可以对不同索引的对象进行算术运算,如果存在不同的索引对,结果的索引就是该索引对的并集. 一.算术运算 a.series的加法运算 s1 = Series([1,2,3],index=["a","b","c"]) s2 = Series([4,5,6],index=["a","c","e"]) print(s1+s2) ''' a 5.0 b NaN c 8.0 e NaN '
-
TensorFlow人工智能学习张量及高阶操作示例详解
目录 一.张量裁剪 1.tf.maximum/minimum/clip_by_value() 2.tf.clip_by_norm() 二.张量排序 1.tf.sort/argsort() 2.tf.math.topk() 三.TensorFlow高阶操作 1.tf.where() 2.tf.scatter_nd() 3.tf.meshgrid() 一.张量裁剪 1.tf.maximum/minimum/clip_by_value() 该方法按数值裁剪,传入tensor和阈值,maximum是把数
-
logback自定义json日志输出示例详解
目录 前言 依赖的jar maven坐标 配置Appender节点 appender配置说明: 配置logger节点 logger配置说明: 前言 先说下楼主的使用场景吧,将程序的某些方法调用以json格式的内容记录到文件中,提供给大数据做数据分析用.当然这个需求实现起来很简单,通过aop拦截切面统一输出内容到文件即可.下面要介绍的就是通过logback日志体系以及logstash提供的json log依赖将数据以json格式记录到日志文件的例子. 依赖的jar logstash-logback
-
Python实现批量采集商品数据的示例详解
目录 本次目的 知识点 开发环境 代码 本次目的 python批量采集某商品数据 知识点 requests 发送请求 re 解析网页数据 json 类型数据提取 csv 表格数据保存 开发环境 python 3.8 pycharm requests 代码 导入模块 import json import random import time import csv import requests import re import pymysql 核心代码 # 连接数据库 def save_sql(t
-
实现像php一样方便的go ORM数据库操作示例详解
目录 引言 php的方便 go的麻烦 解决方案 写在最后 引言 很多人都是从php转过来的吧,不知道你们有没有发现,go界的orm并没有像php的orm一样好用.这篇文章里,我们认真的讨论下这个问题,并且会在后面提出解决方案. php的方便 比如你想实现一个关联查询,在php里,你只需要不断的使用箭头函数就可以了. $users = DB::table('users')->whereIn('id', [1, 2, 3])->orderBy('name', 'desc')->get();
-
JavaIO字符操作和对象操作示例详解
目录 字符操作 编码与解码 String 的编码方式 Reader 与 Writer 实现逐行输出文本文件的内容 对象操作 序列化 Serializable transient 字符操作 编码与解码 编码就是把字符转换为字节,而解码是把字节重新组合成字符. 如果编码和解码过程使用不同的编码方式那么就出现了乱码. GBK 编码中,中文字符占 2 个字节,英文字符占 1 个字节: UTF-8 编码中,中文字符占 3 个字节,英文字符占 1 个字节: UTF-16be 编码中,中文字符和英文字符都占
-
Python实现监控远程主机实时数据的示例详解
目录 0 简述 1 程序说明文档 1.1 服务端 1.2 客户端 2 代码 0 简述 实时监控应用程序,使用Python的Socket库和相应的第三方库来监控远程主机的实时数据,比如CPU使用率.内存使用率.网络带宽等信息.可以允许多个用户同时访问服务端.注:部分指令响应较慢,请耐心等待. 1 程序说明文档 1.1 服务端 本程序为一个基于TCP协议的服务端程序,可以接收客户端发送的指令并执行相应的操作,最终将操作结果返回给客户端.程序运行在localhost(即本机)的8888端口. 主要功能