如何使用Python的OpenCV库处理图像和视频
目录
- 介绍
- 计算机视觉
- OpenCV
- 应用:
- 安装
- 使用 OpenCV 处理图像
- 1. 从文件中读取图像
- 2. 调整图像大小:
- 3. 旋转图像
- 4. 翻转图像:
- 5. 重写图像
- 6. 裁剪图像
- 7. 绘制形状
- 使用 OpenCV 处理视频
- 1. 捕获视频帧的属性:
- 2. 读取视频文件
- 3. 编写视频文件
- 结论
- 总结
介绍
众所周知,计算机视觉在机器学习和人工智能领域获得了巨大的普及。图像识别技术允许计算机处理比人眼更多的信息,通常更快、更准确,或者只是在人们不参与观看的情况下处理。因此,你可能想知道机器如何学习和解释视觉世界。
在本文中,我将介绍如何使用 Python 的 OpenCV 库开始处理图像和视频。我们将涵盖以下主题:
- 计算机视觉简介
- OpenCV 库及其应用简介
- 如何使用 OpenCV 库处理图像和视频
计算机视觉
它是人工智能和计算机科学的一个领域,训练计算机理解视觉世界。它是机器学习的主要组成部分之一。它处理自然世界的图像(高维数据)。它执行各种任务,例如获取、分析和处理以理解图像并将其转换为数字或符号信息。
当今的计算机视觉算法基于模式识别,通常依赖于卷积神经网络 (CNN)。由于该领域的各种进步,计算机视觉正在蓬勃发展,并且它的受欢迎程度在过去几年中呈指数增长。
计算机视觉的应用范围从缺陷检测到入侵者检测、口罩检测到肿瘤检测、作物监测到植物监测、车辆分类到交通流量分析等。该技术主要应用于零售和制造、交通、媒体、农业、医疗保健、体育、银行、增强现实、家庭安全等。
OpenCV
Python 包含一个名为 OpenCV 的库,用于在计算机视觉领域工作。它是一个开源库,于 1999 年推出。我们可以执行图像处理、图像分析、视频分析等任务。该库主要用 C++ 编写,具有 C++、Python、Java 和 MATLAB 等接口。
应用:
- 2D 和 3D 特征工具包
- 视频/图像搜索检索
- 人脸识别系统
- 手势识别
- 移动机器人
- 对象识别
- 医学影像分析
- 运动追踪
- 增强现实
安装
使用 pip 命令可以轻松安装 OpenCV,如下所示
pip install opencv-python
使用 OpenCV 处理图像
在处理图像时,OpenCV 有许多可以对图像执行的操作。其中,我将讨论:
- 读取图像
- 调整图像大小
- 旋转图像
- 翻转图像
- 重写图像
- 裁剪图像
- 在图像上绘制各种形状
1. 从文件中读取图像
- 使用函数imread()读取图片 (支持BMP、jpeg、tiff、png、便携图片格式等)
- 为了显示我们在上一步中读取的图像,我们使用函数“imshow()”。这个函数的第一个参数是标题,第二个是我们读到的图像。
- waitkey() 函数显示一个窗口几毫秒。毫秒数作为参数传递给函数。如果 0 作为参数传递,它将永远等待,直到按下任何键。
- 最后,destroyAllWindows() 将图像窗口显示后从内存中删除。
例子:
python 代码:
import cv2
img=cv2.imread('img.jpeg')
cv2.imshow('Image',img)
cv2.waitKey()
cv2.destroyAllWindows()
输出

2. 调整图像大小:
在图像处理中,经常需要调整图像的大小。OpenCV 为我们提供了几种轻松重新缩放图像的方法。让我们通过一个例子来理解。
例子:
img2=cv2.resize(img,(400,400)) #resize by a fraction of original size img3=cv2.resize(img,(0,0),fx=0.5,fy=0.6) #using INTER_AREA to shrink the image img4=cv2.resize(img,(600,700),interpolation=cv2.INTER_AREA)
3. 旋转图像
使用 OpenCV 旋转图像的语法是
M=cv2.getRotationMatrix2D(center, angle,scale)
然后我们使用方法
cv2.wrapAffine(src,M, (h,w))
让我们通过一个例子来深入了解:
例子:
#calculate height and width to get center (h,w)=img.shape[:2] center=(w/2,h/2) #rotate by 90 degrees M = cv2.getRotationMatrix2D(center, 90, 1.0) img90 = cv2.warpAffine(img, M, (h, w)) #rotate by 180 degrees M = cv2.getRotationMatrix2D(center, 180, 1.0) img180 = cv2.warpAffine(img, M, (h, w)) #rotate by 270 degrees M = cv2.getRotationMatrix2D(center, 270, 1.0) img270 = cv2.warpAffine(img, M, (h, w))

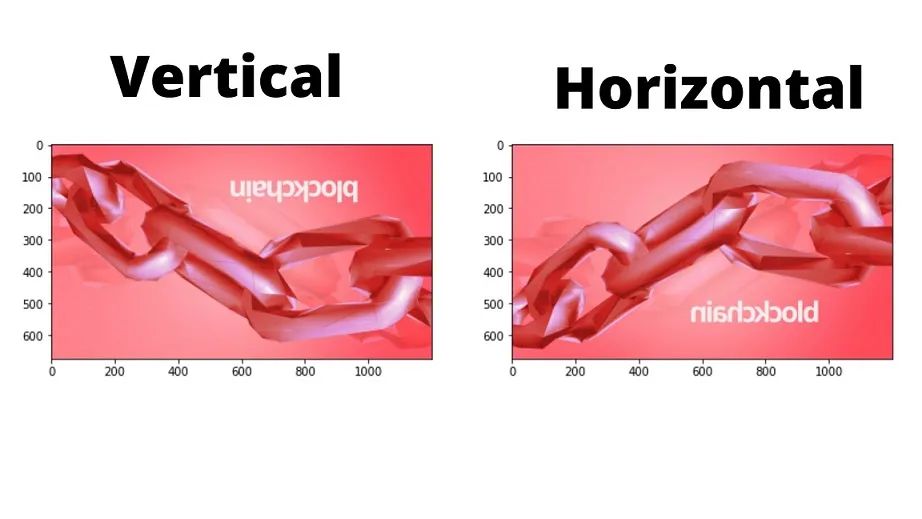
4. 翻转图像:
要翻转图像,我们使用函数 cv2.flip() 并传递参数,即图像和翻转代码(水平或垂直)
例子:
#flip- vertical axes img=cv2.flip(img,0) #flip- horizontal axes img=cv2.flip(img,1)
5. 重写图像
要将图像重写为新文件,我们使用函数 imwrite() 如下:
cv2.imwrite('new_img.jpg',img)
6. 裁剪图像
#crop from top img=img[0:100,0:100] #crop by specifying height and width img=img[50:200,50:100]
7. 绘制形状
使用 OpenCV,我们可以使用不同的函数在图像上快速绘制各种形状,如圆形、矩形、多边形等。让我们用一个例子来理解:
例子:
#creating a blank image import cv2 as cv2 import numpy as np img=np.zeros((500,500,3),dtype=float) #changing the color of the image to green img[:]=0,255,0 #Red img[:]=0,0,255
#changing the color of a particular portion img[200:300,300:450]=0,255,0 #drawing a rectangle cv2.rectangle(img,(100,100),(180,180),color=(255,0,0),thickness=5) #draw a circle with filling the color cv2.circle(img,center=(100,300),radius=60,color=(0,255,0),thickness=-1) #drawing a line cv2.line(img,(0,0),(317,356),thickness=3,color=(0,255,0)) #adding text cv2.putText(img,org=(50,50),fontScale=3,color=(255,0,0) ,thickness=2,lineType=cv2.LINE_AA,text="IMAGES", fontFace=cv2.FONT_HERSHEY_COMPLEX_SMALL) cv2_imshow(img) cv2.waitKey(0)

使用 OpenCV 处理视频
视频是帧序列或图像序列。图像通常采用 BGR(蓝、绿、红)的形式。每个像素的值都在 0-255 之间。要开始使用 OpenCV 处理视频,我们使用以下函数:
Cv2.VideoCapture():它建立与视频的连接。它带有一个参数,该参数指示是使用内置摄像头还是附加摄像头。值“0”表示内置摄像头。
Cap.read():这个方法可以让我们得到一个帧。
Cv2.cvtColor():允许你更改图像使用的颜色模型。这包括从 BGR 转换为 RGB 和灰度。
在处理视频方面,在本文中,我们将学习
- 如何捕获视频帧的不同属性
- 读取视频文件
- 写视频
1. 捕获视频帧的属性:
让我们看几个捕获视频属性的示例。
要捕获帧形状:
frame.shape (2160, 3840, 3) plt.imshow(frame) plt.show()
要更改框架的颜色,我们使用函数 cv2.cvtColor(),如下所示:
#changing the color of the frame plt.show() plt.imshow(cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY))

为了捕捉视频,我们使用函数 cv2.VideoCapture()
cap=cv2.VideoCapture('/content/video.mp4')
cap.read()
要获取框架的高度,我们使用 cap.get() 函数如下:
#height cap.get(cv2.CAP_PROP_FRAME_HEIGHT)
为了获得框架的宽度,我们使用:
#width cap.get(cv2.CAP_PROP_FRAME_WIDTH)
要获取帧数,我们使用函数 cap.get() 如下:
#number of frames
cap.get(cv2.CAP_PROP_FRAME_COUNT)
为了获得每秒的帧数,我们使用
#number of frames per sec cap.get(cv2.CAP_PROP_FPS)
2. 读取视频文件
- 导入 cv2
- 然后我们使用函数 cv2.VideoCapture() 来捕捉视频。
- 接下来,我们循环遍历每一帧并使用函数 cap.read() 读取帧。
- 为了显示每一帧,我们使用方法 cv2.imshow()。
- 最后,我们使用 waitKey() 函数中断循环,当用户按下任意键时,该函数会中断循环。
- destroyAllWindows() 函数将关闭窗口。
例子:
#importing dependencies
import cv2
from matplotlib import pyplot as plt
#establish capture
cap=cv2.VideoCapture('/content/video.mp4')
#loop through each frame
while(cap.isOpened()):
ret,frame=cap.read()
frame=cv2.resize(frame,(1200,700))
cv2.imshow(‘Video',frame)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
#close down everything
cap.release()
cv2.destroyALLWindows()
3. 编写视频文件
- 导入 cv2
- 使用函数 cv2.VideoCapture() 捕获视频
- 然后我们使用函数 cv2.VideoWriter 来编写视频。该函数将参数作为
- cv2.VideoWriter(filename, fourcc, fps, framesize)
- filename - 捕获的输入视频文件
- Fourcc - 用于指定视频编解码器的代码
- fps - 每秒帧数
- framesize - 视频框的高度和宽度
- 接下来,我们循环遍历每一帧并使用对象 video_writer 来写入帧。
- 最后,我们使用 waitKey() 函数来打破循环
- 使用函数 destroyAllWindows() 关闭窗口
import cv2
from google.colab.patches import cv2_imshow
cap=cv2.VideoCapture('/content/video.mp4')
height=int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
width=int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
fps=int(cap.get(cv2.CAP_PROP_FPS))
frame_size = (width,height)
video_writer= cv2.VideoWriter('/content/output.avi',cv2.VideoWriter_fourcc('M','J','P','G'), fps, frame_size)
for frame_idx in range(int(cap.get(cv2.CAP_PROP_FRAME_COUNT))):
ret,frame=cap.read()
gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)
video_writer.write(gray)
if cv2.waitKey(10) & 0xFF== ord('q'):
break
cap.release()
cv2.destroyALLWindows()
结论
本文帮助你创建了与计算机视觉相关的出色应用程序。希望你现在对以下内容有一个很好的了解:
- 什么是计算机视觉
- OpenCV 库的应用
- 使用 OpenCV 库处理图像
- 使用 OpenCV 库处理视频
总结
到此这篇关于如何使用Python的OpenCV库处理图像和视频的文章就介绍到这了,更多相关Python OpenCV处理图像和视频内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
在Python下利用OpenCV来旋转图像的教程
OpenCV是应用最被广泛的的开源视觉库.他允许你使用很少的代码来检测图片或视频中的人脸. 这里有一些互联网上的教程来阐述怎么在OpenCV中使用仿射变换(affine transform)旋转图片--他们并没有处理旋转一个图片里的矩形一般会把矩形的边角切掉这一问题,所以产生的图片需要修改.当正确的使用一点代码时,这是一点瑕疵. def rotate_about_center(src, angle, scale=1.): w = src.shape[1] h = src.shape[0] ran
-

Python Opencv实现图像轮廓识别功能
本文实例为大家分享了python opencv识别图像轮廓的具体代码,供大家参考,具体内容如下 要求:用矩形或者圆形框住图片中的云朵(不要求全部框出) 轮廓检测 Opencv-Python接口中使用cv2.findContours()函数来查找检测物体的轮廓. import cv2 img = cv2.imread('cloud.jpg') # 灰度图像 gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY) # 二值化 ret, binary = cv2.th
-
python opencv进行图像拼接
本文实例为大家分享了python opencv进行图像拼接的具体代码,供大家参考,具体内容如下 思路和方法 思路 1.提取要拼接的两张图片的特征点.特征描述符: 2.将两张图片中对应的位置点找到,匹配起来: 3.如果找到了足够多的匹配点,就能将两幅图拼接起来,拼接前,可能需要将第二幅图透视旋转一下,利用找到的关键点,将第二幅图透视旋转到一个与第一幅图相同的可以拼接的角度: 4.进行拼接: 5.进行拼接后的一些处理,让效果看上去更好. 实现方法 1.提取图片的特征点.描述符,可以使用opencv创
-
python+OpenCV实现图像拼接
本文实例为大家分享了利用python和OpenCV实现图像拼接,供大家参考,具体内容如下 python+OpenCV实现image stitching 在最新的OpenCV官方文档中可以找到C++版本的Stitcher类的说明, 但是python版本的还没有及时更新, 本篇对python版本的实现做一个简单的介绍. 由于官方文档中还没有python版本的Stitcher类的说明, 因此只能自己去GitHub源码上找, 以下是stitching的样例: from __future__ import
-
Python OpenCV处理图像之图像像素点操作
本文实例为大家分享了Python OpenCV图像像素点操作的具体代码,供大家参考,具体内容如下 0x01. 像素 有两种直接操作图片像素点的方法: 第一种办法就是将一张图片看成一个多维的list,例如对于一张图片im,想要操作第四行第四列的像素点就直接 im[3,3] 就可以获取到这个点的RGB值. 第二种就是使用 OpenCV 提供的 Get1D. Get2D 等函数. 推荐使用第一种办法吧,毕竟简单. 0x02. 获取行和列像素 有一下四个函数: cv.GetCol(im, 0): 返回第
-
python opencv实现图像边缘检测
本文利用python opencv进行图像的边缘检测,一般要经过如下几个步骤: 1.去噪 如cv2.GaussianBlur()等函数: 2.计算图像梯度 图像梯度表达的是各个像素点之间,像素值大小的变化幅度大小,变化较大,则可以认为是出于边缘位置,最多可简化为如下形式: 3.非极大值抑制 在获得梯度的方向和大小之后,应该对整幅图像做一个扫描,去除那些非边界上的点.对每一个像素进行检查,看这个点的梯度是不是周围具有相同梯度方向的点中最大的.如下图所示: 4.滞后阈值 现在要确定那些边界才是真正的
-
python opencv旋转图像(保持图像不被裁减)
本文实例为大家分享了python opencv旋转图像的具体代码,保持图像不被裁减,供大家参考,具体内容如下 # -*- coding:gb2312 -*- import cv2 from math import * import numpy as np img = cv2.imread("3-2.jpg") height,width=img.shape[:2] degree=45 #旋转后的尺寸 heightNew=int(width*fabs(sin(radians(degree)
-
如何使用Python的OpenCV库处理图像和视频
目录 介绍 计算机视觉 OpenCV 应用: 安装 使用 OpenCV 处理图像 1. 从文件中读取图像 2. 调整图像大小: 3. 旋转图像 4. 翻转图像: 5. 重写图像 6. 裁剪图像 7. 绘制形状 使用 OpenCV 处理视频 1. 捕获视频帧的属性: 2. 读取视频文件 3. 编写视频文件 结论 总结 介绍 众所周知,计算机视觉在机器学习和人工智能领域获得了巨大的普及.图像识别技术允许计算机处理比人眼更多的信息,通常更快.更准确,或者只是在人们不参与观看的情况下处理.因此,你可能想
-
Python基于OpenCV库Adaboost实现人脸识别功能详解
本文实例讲述了Python基于OpenCV库Adaboost实现人脸识别功能.分享给大家供大家参考,具体如下: 以前用Matlab写神经网络的面部眼镜识别算法,研究算法逻辑,采集大量训练数据,迭代,计算各感知器的系数...相当之麻烦~而现在运用调用pythonOpenCV库Adaboost算法,无需知道算法逻辑,无需进行模型训练,人脸识别变得相当之简单了. 需要用到的库是opencv(open source computer vision),下载安装方式如下: 使用pip install num
-
Python 第三方opencv库实现图像分割处理
目录 前言 1.加载图片 2.对图片做灰度处理 3.对图片做二值化处理 3.1.自定义阈值 4.提取轮廓 5.对轮廓画矩形框 6.分割图片并保存 7.查看分割图片 8.完整代码 前言 所需要安装的库有: pip install opencv-python pip install matplotlib Python接口帮助文档网址:https://docs.opencv.org/4.5.2/d6/d00/tutorial_py_root.html 本文所用到的图片素材: 首先,导入所用到的库: i
-
python用opencv批量截取图像指定区域的方法
代码如下 import os import cv2 for i in range(1,201): if i==169 or i==189: i = i+1 pth = "C:\\Users\\Desktop\\asd\\"+str(i)+".bmp" image = cv2.imread(pth) //从指定路径读取图像 cropImg = image[600:1200,750:1500] //获取感兴趣区域 cv2.imwrite("C:\\Users\
-
python使用OpenCV模块实现图像的融合示例代码
可以通过OpenCV函数cv.add()或简单地通过numpy操作添加两个图像,res = img1 + img2.两个图像应该具有相同的深度和类型,或者第二个图像可以是标量值. 三种融合 注意融合时,一般来说两个图像的尺寸是一样大小的,如果大小不一样,需要把大的图像的某一部分先截出来,与小的图先融合,再作为整体替换掉原来大图中抠出的小图部分. """ # @Time : 2020/4/3 # @Author : JMChen """ impor
-
Python下opencv库的安装过程及问题汇总
本文主要内容是python下opencv库的安装过程,涉及我在安装时遇到的问题,并且,将从网上搜集并试用的一些解决方案进行了简单的汇总,记录下来. 由于记录的是我第一次安装opencv库的过程,所以内容涵盖可能不全面,如果有出错的地方请务必指正.下面进入主题. 关于python的下载安装不再赘述,python的版本号是我们在opencv库的安装过程中需要用到的,cmd运行python可以进行查看. 通常,我们使用pip命令来安装扩展库. 打开cmd运行 pip install opencv-py
-
利用Python和OpenCV库将URL转换为OpenCV格式的方法
今天的博客是直接来源于我自己的个人工具函数库. 过去几个月,有些PyImageSearch读者电邮问我:"如何获取URL指向的图片并将其转换成OpenCV格式(不用将其写入磁盘再读回)".这篇文章我将展示一下怎么实现这个功能. 额外的,我们也会看到如何利用scikit-image从URL下载一幅图像.当然前行之路也会有一个常见的错误,它可能让你跌个跟头. 继续往下阅读,学习如何利用利用Python和OpenCV将URL转换为图像 方法1:OpenCV.NumPy.urllib 第一个方
-
Python基于opencv的简单图像轮廓形状识别(全网最简单最少代码)
可以直接跳到最后整体代码看一看是不是很少的代码!!!! 思路: 1. 数据的整合 2. 图片的灰度转化 3. 图片的二值转化 4. 图片的轮廓识别 5. 得到图片的顶点数 6. 依据顶点数判断图像形状 一.原数据的展示 图片文件共36个文件夹,每个文件夹有100张图片,共3600张图片. 每一个文件夹里都有形同此类的图形 二.数据的整合 对于多个文件夹,分析起来很不方便,所有决定将其都放在一个文件夹下进行分析,在python中具体实现如下: 本次需要的包 import cv2 import os
-
python计算机视觉OpenCV库实现实时摄像头人脸检测示例
目录 设备准备: 实现过程 调用模型库文件 打开摄像头 人脸检测 设置退出机制 程序运行 全部代码 OpenCV 是一个C++库,目前流行的计算机视觉编程库,用于实时处理计算机视觉方面的问题,它涵盖了很多计算机视觉领域的模块.在Python中常使用OpenCV库实现图像处理. 本文将介绍如何在Python3中使用OpenCV实现实时摄像头人脸检测: 设备准备: USB摄像头 接入PC电脑USB口,并调试正常打开视频.如果电脑内置了电脑摄像头,测试一下摄像头能否正常使用. 下载特征分类模型: XM
-
python使用opencv按一定间隔截取视频帧
关于opencv OpenCV 是 Intel 开源计算机视觉库 (Computer Version) .它由一系列 C 函数和少量 C++ 类构成,实现了图像处理和计算机视觉方面的很多通用算法. OpenCV 拥有包括 300 多个 C 函数的跨平台的中.高层 API .它不依赖于其它的外部库 -- 尽管也可以使用某些外部库. OpenCV 对非商业应用和商业应用都是免费 的.同时 OpenCV 提供了对硬件的访问,可以直接访问摄像头,并且 opencv 还提供了一个简单的 GUI(graph