Java详解如何将excel数据转为树形
目录
- 前言
- 拆分原始数据
- 1.创建实体类
- 2.处理数据
- 手动设置每棵树每个节点的id以及父id
- 递归封装为树结构
- 总结
前言
今天收到一个导入的任务,要求将excel数据保存到数据库中,不同于普通的导入,这个导入的数据是一个树形结构,如下图:
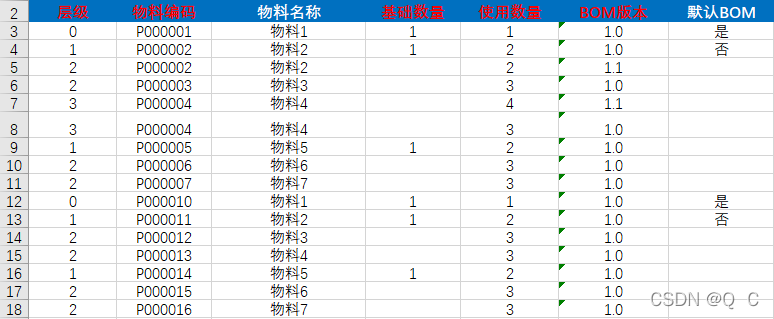
通过观察数据中的层级列我们发现表格数据由2棵树组成,分别是第3,4,5,6,7,8,9,10,11和12,13,14,15,16,17,18,它们由0作树的根节点,1为0的子节点,2为相邻1的子节点,由此得出第一颗树的结构为:

拆分原始数据
1.创建实体类
创建vo接收解析数据,在这里,我们只关心层级属性
@Excel(name = "层级")
private String hierarchy;
@Excel(name = "物料编码")
private String materialCode;
@Excel(name = "物料名称")
private String materialName;
@Excel(name = "基础数量")
private BigDecimal materialNum;
@Excel(name = "使用数量")
private BigDecimal useAmount;
@Excel(name = "BOM版本")
private String version;
@Excel(name = "默认BOM")
private String isDefaults;
2.处理数据
将数据源拆分为若干棵树的数据集
代码如下(示例):
/**
* 将集合对象按指定元素分割存储
*
* @param materialVos 原始集合
* @param s 分割元素(这里是当集合对象层级为0时则分割,也就是树的根节点为0)
* @return 每棵树的结果集
*/
private List<List<MatMaterialBomImportVo>> subsection(List<MatMaterialBomImportVo> materialVos, String s) {
List<List<MatMaterialBomImportVo>> segmentedData = new ArrayList<>();
if (materialVos != null) {
//获取指定元素的数量,判断出最终将拆分为多少段
List<MatMaterialBomImportVo> collect = materialVos.stream().filter(bom -> s.equals(bom.getHierarchy())).collect(Collectors.toList());
int count = 0;
for (int i = 0; i < collect.size(); i++) {
List<MatMaterialBomImportVo> bomImportVo = new ArrayList<>();
boolean num = false;
//遍历数据源
for (; count < materialVos.size(); count++) {
//第一个必然为树的根节点,直接获取并跳过
if (count == 0) {
bomImportVo.add(materialVos.get(count));
continue;
}
//当数据源第n个等于根节点并且已经成功添加过数据时判断为一段数据的结束,跳出循环,
if (s.equals(materialVos.get(count).getHierarchy()) && num) {
break;
}
bomImportVo.add(materialVos.get(count));
num = true;
}
segmentedData.add(bomImportVo);
}
}
return segmentedData;
}
手动设置每棵树每个节点的id以及父id
代码如下(示例):
for (List<MatMaterialBomImportVo> segmentedDatum : subsection(materialVos, "0")) {
//设置id以及父id
int i = 0;
for (MatMaterialBomImportVo vo : segmentedDatum) {
BeanTrim.beanAttributeValueTrim(vo);
vo.setPrimaryKey(i);
getParentId(vo, segmentedDatum);
i++;
}
}
/**
* 设置父id
*
* @param vo
* @param segmentedDatum
*/
private void getParentId(MatMaterialBomImportVo vo, List<MatMaterialBomImportVo> segmentedDatum) {
for (int j = vo.getPrimaryKey(); j >= 0; j--) {
if (Integer.parseInt(segmentedDatum.get(j).getHierarchy()) == Integer.parseInt(vo.getHierarchy()) - 1) {
vo.setForeignKey(segmentedDatum.get(j).getPrimaryKey());
break;
}
if (j == 0) {
vo.setForeignKey(-1);
}
}
}
说明:拆分为若干棵树后设置每条数据的虚拟id为自己的索引,每棵树的id互相隔离,
根据表格数据规律得出子节点只可能存在于自己节点以下,以及下一个相同节地以上,根据这个规律设置每个节点的父id
递归封装为树结构
代码如下(示例):
/**
* 递归遍历为树形结构
*
* @param vo 当前处理的元素
* @param segmentedDatum 每棵树的数据集
*/
private void treeData(MatMaterialBomImportVo vo, List<MatMaterialBomImportVo> segmentedDatum) {
for (int i = vo.getPrimaryKey(); i < segmentedDatum.size(); i++) {
if (i + 1 == segmentedDatum.size()) {
if (vo.getForeignKey() == null) {
getParentId(vo, segmentedDatum);
}
break;
}
int v = Integer.parseInt(vo.getHierarchy());
int vs = Integer.parseInt(segmentedDatum.get(i + 1).getHierarchy());
if (vs == v + 1) {
if (v > 1) {
vo.setForeignKey(segmentedDatum.get(i).getPrimaryKey());
for (int j = vo.getPrimaryKey(); j > 0; j--) {
if (Integer.parseInt(segmentedDatum.get(j).getHierarchy()) == Integer.parseInt(vo.getHierarchy()) - 1) {
vo.setForeignKey(segmentedDatum.get(j).getPrimaryKey());
}
}
}
vo.getImportVoList().add(segmentedDatum.get(i + 1));
}
if (vs <= v) {
if (vo.getForeignKey() == null) {
for (int j = vo.getPrimaryKey(); j > 0; j--) {
if (Integer.parseInt(segmentedDatum.get(j).getHierarchy()) == Integer.parseInt(vo.getHierarchy()) - 1) {
vo.setForeignKey(segmentedDatum.get(j).getPrimaryKey());
break;
}
}
}
break;
}
}
if (vo.getImportVoList() != null && vo.getImportVoList().size() > 0) {
for (MatMaterialBomImportVo matMaterialBomImportVo : vo.getImportVoList()) {
treeData(matMaterialBomImportVo, segmentedDatum);
}
}
}
说明:我这里传进来的vo是没有设置id和父id的,只对数据源做了树拆分处理,因为业务需求,后面并没有使用这套递归的方法组装为树,所以递归代码可能有点误差,仅供参考
总结
这里主要针对导入数据为树形,以及没有具体的id以及父id的处理,在拆分开没棵树的数据并且每棵树的节点有了父子关系后就可以通过正常的流程处理
到此这篇关于Java详解如何将excel数据转为树形的文章就介绍到这了,更多相关Java excel内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
java解析Excel文件的方法实例详解
目录 介绍 1.1 pom依赖 1.2 将数据流转化为可解析的Workbook类型文件 1.3 解析 1.4 Controller层接收前端传递的Excel文件(前端使用Element-ui的<el-upload>组件) 1.5 ServiceIMPL层解析Excel文件并将解析结果返回 1.6 前端VUE实现Excel文件的上传(使用Element-ui的<el-upload>组件) 总结 在做一个项目时,有很多原本保存在Excel文件中的基础数据,如此则需要一个Excel文件解
-

Java easyexcel使用教程之导出篇
目录 EasyExcel简介 1.导入Maven依赖 2.新建Student.java类 3.generateStudentUtil.java类,随机生成Student对象 4.BaseTest.java 4.导出Excel报表 5.把姓名格式化:1显示男,0显示女 6.把体重保留2位小数 7.过滤字段不生成excel 8.冻结列, 冻结姓名列 总结 EasyExcel简介 EasyExcel是一个基于Java的简单.省内存的读写Excel的开源项目.在尽可能节约内存的情况下支持读写百M的Exc
-
Java实现生成Excel树形表头完整代码示例
本文主要分享了Java实现生成Excel树形表头完整代码示例,没有什么好解释的,直接看看代码过程. 源数据格式: String[] targetNames = { "指标名称", "单位", "xx_yy1", "xx_yy2_zz1", "xx_yy2_zz2", "2017年5月_主营业务收入_累计", "2017年5月_主营业务收入_同比", "201
-
Java树形结构数据生成导出excel文件方法记录
目录 什么是树形结构数据 效果 用法 源码 总结 什么是树形结构数据 效果 用法 String jsonStr = "{\"name\":\"aaa\",\"children\":[{\"name\":\"bbb\",\"children\":[{\"name\":\"eee\"},{\"name\":\"f
-
Java设置Excel数据验证的示例代码
数据验证是Excel 2013版本中,数据功能组下面的一个功能,在Excel2013之前的版本,包含Excel2010 Excel2007称为数据有效性.通过在excel表格中设置数据验证可有效规范数据输入.设置数据类型时,可设置如验证数字(数字区间/数字类型).日期.文本长度等.下面通过Java程序代码演示数据验证的设置方法及结果. 工具:Free Spire.XLS for Java (免费版) 注:可通过官网下载,并解压将lib文件夹下的jar文件导入java程序:或者通过maven下载导
-
Java Excel数据导入数据库的方法
目录 1.根据业务需求设计数据库表 2.根据数据库表设计一个Excel模板 3.环境准备 4.通过插件生成表对应的实体类 5.自定义编写工具类 6.编写具体业务逻辑Service 7.在dao层对应的xml文件中,编写批量上传的方法 8.Controller实现业务的控制 9.通过Swagger测试接口 10.在数据和控制台中查看导入效果 总结 1.根据业务需求设计数据库表 2.根据数据库表设计一个Excel模板 模板的每列属性必须与表字段一一对应 3.环境准备 我这里项目环境是基于Spring
-
Java实现Excel导入导出操作详解
目录 前言 1. 功能测试 1.1 测试准备 1.2 数据导入 1.2.1 导入解析为JSON 1.2.2 导入解析为对象(基础) 1.2.3 导入解析为对象(字段自动映射) 1.2.4 导入解析为对象(获取行号) 1.2.5 导入解析为对象(获取原始数据) 1.2.6 导入解析为对象(获取错误提示) 1.2.7 导入解析为对象(限制字段长度) 1.2.8 导入解析为对象(必填字段验证) 1.2.9 导入解析为对象(数据唯一性验证) 1.3 数据导出 1.3.1 动态导出(基础) 1.3.2 动
-
Java详解如何将excel数据转为树形
目录 前言 拆分原始数据 1.创建实体类 2.处理数据 手动设置每棵树每个节点的id以及父id 递归封装为树结构 总结 前言 今天收到一个导入的任务,要求将excel数据保存到数据库中,不同于普通的导入,这个导入的数据是一个树形结构,如下图: 通过观察数据中的层级列我们发现表格数据由2棵树组成,分别是第3,4,5,6,7,8,9,10,11和12,13,14,15,16,17,18,它们由0作树的根节点,1为0的子节点,2为相邻1的子节点,由此得出第一颗树的结构为: 拆分原始数据 1.创建实体类
-
详解C#设置Excel数据自适应行高、列宽的2种情况
Excel表格中,由于各种数据的复杂性,可能存在单元格中的数据字号大小.数据内容长度不一而出现,列宽过宽.过窄或者行高过大.过小的问题.常见的解决方法是调整行高.列宽.在Microsoft Excel中,在单元格格式设置中可手动设置自适应行高或自适应列宽,但通过代码,我们可以通过方法AutoFitColumns()或者AutoFitRows()来设置指定数据范围或整个工作表的自适应行高.列宽.这里设置自适应分以下2种情况来进行: 1. 固定数据,设置行高.列宽自适应数据 2. 固定行高.列宽,设
-
详解thinkphp实现excel数据的导入导出(附完整案例)
实现步骤: 一:在http://phpexcel.codeplex.com/下载最新PHPExcel放到Vendor下,注意位置:ThinkPHP\Extend\Vendor\PHPExcel\PHPExcel.php. 二:导出excel代码实现 /**方法**/ function index(){ $this->display(); } public function exportExcel($expTitle,$expCellName,$expTableData){ $xlsTitle =
-
详解Obejective-C中将JSON数据转为模型的方法
在我们的日常开发中需要对加载的一些本地数据例如plist.json等文件中的数据进行模型转化,而苹果也为我们提供了一种非常方便的键值转换方式KVC.然而KVC在某些情况下并不能保存数据的转换成功,比如必须保证模型的属性个数大于等于字典个数,也要必须属性名称与字典的key相同等.所以这次我们假设下属性名称与字典中的key不一致的时候转换方法. 首先我们还是先要尝试下使用KVC的方式来解决这个问题 模型如下: 复制代码 代码如下: @property (nonatomic, strong) NSSt
-
详解Springboot下载Excel的三种方式
汇总一下浏览器下载和代码本地下载实现的3种方式. (其实一般都是在代码生成excel,然后上传到oss,然后传链接给前台,但是我好像没有实现过直接点击就能在浏览器下载的功能,所以这次一起汇总一下3种实现方式.)
-
Java详解IO流创建读取与写入操作
目录 概念 io流对应的方法 一.File方法(创建文件) 二.FileInputStream(获取字节方法)输入流 三.FileOutputStream(写入字节方法)输出流 总结 概念 IO流可以初步的理解为数据间的传输,我们将一组数据入:1234567,将他们从hello文件中转入haha文件中,使用程序的方法进行转入的话则需要一个一个的传入,即为一个字节一个字节的传输,我们每次只能传入或读取一个字节,这就是io流的大致流程,io流对任何类型的文件都可以进行读取.如:文本文件,图片,歌曲m
-
实例详解Android文件存储数据方式
总体的来讲,数据存储方式有三种:一个是文件,一个是数据库,另一个则是网络.下面通过本文给大家介绍Android文件存储数据方式. 1.文件存储数据使用了Java中的IO操作来进行文件的保存和读取,只不过Android在Context类中封装好了输入流和输出流的获取方法. 创建的存储文件保存在/data/data/<package name>/files文件夹下. 2.操作. 保存文件内容:通过Context.openFileOutput获取输出流,参数分别为文件名和存储模式. 读取文件内容:通
-
Java 详解单向加密--MD5、SHA和HMAC及简单实现实例
Java 详解单向加密--MD5.SHA和HMAC及简单实现实例 概要: MD5.SHA.HMAC这三种加密算法,可谓是非可逆加密,就是不可解密的加密方法. MD5 MD5即Message-Digest Algorithm 5(信息-摘要算法5),用于确保信息传输完整一致.MD5是输入不定长度信息,输出固定长度128-bits的算法. MD5算法具有以下特点: 1.压缩性:任意长度的数据,算出的MD5值长度都是固定的. 2.容易计算:从原数据计算出MD5值很容易. 3.抗修改性:对原数据进行任何
-
详解用Python把PDF转为Word方法总结
先讲一下为啥要写这个文章,网上其实很多这种PDF转化的代码和软件.我一直想用Python做,但是网上搜到的代码很多都不能用,很多是2.7版本的代码,再就是PDF需要用到的库在导入的时候,很多的报错,解决起来特别费劲,而且自从2021年初以来,似乎网上很少有关PDF转化的代码出现了.我在研究了很多代码和pdfminer的用法后,总结了几个方法,目前这几种方法可以解决大多数格式的转化,后面我也专门放了提取PDF表格的代码,文末有高效的免费在线工具推荐. 下面这个是我最最推荐的方法 ,简单高效 ,只要
-
Java详解线上内存暴涨问题定位和解决方案
前因: 因为REST规范,定义资源获取接口使用GET请求,参数拼接在url上. 如果按上述定义,当参数过长,超过tomcat默认配置 max-http-header-size :8kb 会报一下错误信息: Request header is too large 可以修改springboot配置,调整请求头大小 server: max-http-header-size: xxx 后果: 如果max-http-header-size设置过大,会导致接口吞吐下降,jvm oom,内存泄漏. 因为tom