OpenCV目标检测Meanshif和Camshift算法解析
目录
- 学习目标
- Meanshift
- OpenCV中的Meanshift
- Camshift
- OpenCV中的Camshift
- 附加资源
学习目标
在本章中,将学习用于跟踪视频中对象的Meanshift和Camshift算法
Meanshift
Meanshift背后的原理很简单,假设有点的集合(它可以是像素分布,例如直方图反投影)。 给定一个小窗口(可能是一个圆形),必须将该窗口移动到最大像素密度(或最大点数)的区域。如下图所示:

初始窗口以蓝色圆圈显示,名称为“C1”。其原始中心以蓝色矩形标记,名称为“C1_o”。但是,如果找到该窗口内点的质心,则会得到点“C1_r”(标记为蓝色小圆圈),它是窗口的真实质心。当然,二者是不匹配的。因此,移动窗口使新窗口的圆与上一个质心匹配。再次找到新的质心。很可能不会匹配。因此,再次移动它,并继续迭代,以使窗口的中心及其质心落在同一位置(或在很小的期望误差内)。因此,最终获得的是一个具有最大像素分布的窗口。它带有一个绿色圆圈,名为“C2”。正如您在图像中看到的,它具有最大的点数。整个过程在下面的静态图像上演示:

因此,通常会传递直方图反投影图像和初始目标位置。当对象移动时,显然该移动会反映在直方图反投影图像中。因此,Meanshift算法就是将窗口移动到最大密度的新位置的算法。
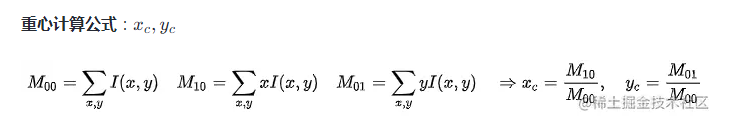
OpenCV中的Meanshift
要在OpenCV中使用Meanshift,首先需要设置目标,找到其直方图,以便可以将目标反投影到每帧上以计算均值偏移。我们还需要提供窗口的初始位置。对于直方图,此处仅考虑色相(Hue)。另外,为避免由于光线不足而产生错误的值,可以使用cv2.inRange()函数丢弃光线不足的值。 使用的视频中的三帧如下:
import cv2
import numpy as np
video_file = 'slow_traffic_small.mp4'
cap = cv2.VideoCapture(video_file)
# take first frame of the video
ret, frame = cap.read()
# setup initial location of window
x, y, w, h = 300, 200, 100, 50 # simply hardcoded the values
track_window = (x, y, w, h)
# setup the roi for tracking
roi = frame[y:y+h, x:x+w]
hsv_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv2.calcHist([hsv_roi], [0], mask, [180], [0, 180])
cv2.normalize(roi_hist, roi_hist, 0, 255, cv2.NORM_MINMAX)
# setup the termination criteria, either 10 iteration or move by atleast 1 pt
term_crit = (cv2.TERM_CRITERIA_EPS|cv2.TERM_CRITERIA_COUNT, 10, 1)
while True:
ret, frame = cap.read()
if ret == True:
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv], [0], roi_hist, [0, 180], 1)
# apply meansift to get the new location
ret, track_window = cv2.meanShift(dst, track_window, term_crit)
# draw it on image
x, y, w, h = track_window
img2 = cv2.rectangle(frame, (x, y), (x+w, y+h), 255, 2)
cv2.imshow('img2', img2)
cv2.waitKey(0)
else:
cv2.destroyAllWindows()
break

Camshift

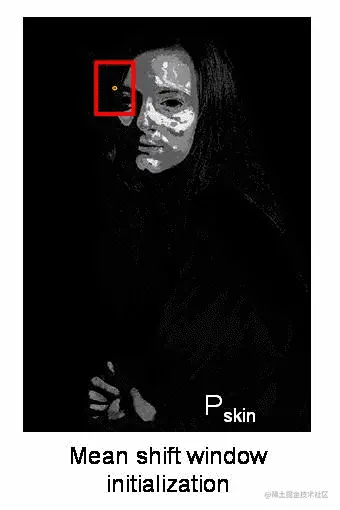
度为止。

OpenCV中的Camshift
它与Meanshift相似,但是返回一个旋转的矩形和box参数(用于在下一次迭代中作为搜索窗口传递)。
import cv2
import numpy as np
video_file = 'slow_traffic_small.mp4'
cap = cv2.VideoCapture(video_file)
# take first frame of the video
ret, frame = cap.read()
# setup initial location of window
x, y, w, h = 300, 200, 100, 50 # simply hardcoded the values
track_window = (x, y, w, h)
# setup the roi for tracking
roi = frame[y:y+h, x:x+w]
hsv_roi = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV)
mask = cv2.inRange(hsv_roi, np.array((0., 60.,32.)), np.array((180.,255.,255.)))
roi_hist = cv2.calcHist([hsv_roi], [0], mask, [180], [0, 180])
cv2.normalize(roi_hist, roi_hist, 0, 255, cv2.NORM_MINMAX)
# setup the termination criteria, either 10 iteration or move by atleast 1 pt
term_crit = (cv2.TERM_CRITERIA_EPS|cv2.TERM_CRITERIA_COUNT, 10, 1)
while True:
ret, frame = cap.read()
if ret == True:
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
dst = cv2.calcBackProject([hsv], [0], roi_hist, [0, 180], 1)
# apply meansift to get the new location
ret, track_window = cv2.CamShift(dst, track_window, term_crit)
# draw it on image
pts = cv2.boxPoints(ret) # find four points of the box
pts = np.int0(pts)
img2 = cv2.polylines(frame, [pts], True, 255, 2)
cv2.imshow('img2', img2)
cv2.waitKey(0)
else:
cv2.destroyAllWindows()
break
三帧的结果如下:

附加资源
- French Wikipedia page on Camshift
- Bradski, G.R., "Real time face and object tracking as a component of a perceptual user interface," Applications of Computer Vision, 1998. WACV '98. Proceedings., Fourth IEEE Workshop on , vol., no., pp.214,219, 19-21 Oct 1998
以上就是OpenCV目标检测Meanshif和Camshift算法解析的详细内容,更多关于OpenCV Meanshif Camshift算法的资料请关注我们其它相关文章!
相关推荐
-
OpenCV立体图像深度图Depth Map基础
目录 目标 基础 代码 目标 在本节中,将学习 根据立体图像创建深度图 基础 在上一节中,看到了对极约束和其他相关术语等基本概念.如果有两个场景相同的图像,则可以通过直观的方式从中获取深度信息.下面是一张图片和一些简单的数学公式证明了这种想法. 上图包含等效三角形.编写它们的等式将产生以下结果: xxx和x′x'x′是图像平面中与场景点3D相对应的点与其相机中心之间的距离.BBB是两个摄像机之间的距离(已知),fff是摄像机的焦距(已知).简而言之,上述方程式表示场景中某个点的深度与相应图像点及
-
OpenCV使用KNN完成OCR手写体识别
目录 目标 手写数字的OCR 也可以用来预测单个数字 英文字母的OCR 目标 在本章中,将学习 使用kNN来构建基本的OCR应用程 使用OpenCV自带的数字和字母数据集 手写数字的OCR 目标是构建一个可以读取手写数字的应用程序.为此,需要一些 train_data 和test_data .OpenCV git项目中有一个图片 digits.png (opencv/samples/data/ 中),其中包含 5000 个手写数字(每个数字500个),每个数字都是尺寸大小为 20x20 的图像.
-
python OpenCV实现图像特征匹配示例详解
目录 目标 Brute-Force匹配器的基础 使用ORB描述符进行Brute-Force匹配 什么是Matcher对象? 带有SIFT描述符和比例测试的Brute-Force匹配 基于匹配器的FLANN 目标 在本章中,将学习: 如何将一个图像中的特征与其他图像进行匹配 在OpenCV中使用Brute-Force匹配器和FLANN匹配器 Brute-Force匹配器的基础 暴力匹配器很简单.它使用第一组中一个特征的描述符,并使用一些距离计算将其与第二组中的所有其他特征匹配.并返回最接近的一个.
-
OpenCV之理解KNN邻近算法k-Nearest Neighbour
目录 目标 理论 OpenCV中的kNN 目标 在本章中,将理解 k最近邻(kNN)算法的概念 理论 kNN是可用于监督学习的最简单的分类算法之一.这个想法是在特征空间中搜索测试数据的最近邻.用下面的图片来研究它. 在图像中,有两个族类,蓝色正方形和红色三角形.称每一种为类(Class).他们的房屋显示在他们的城镇地图中,我们称之为特征空间( Feature Space). (可以将特征空间视为投影所有数据的空间.例如,考虑一个2D坐标空间.每个数据都有两个特征,x和y坐标.可以在2D坐标空间中
-
OpenCV 光流Optical Flow示例
目录 目标 光流 OpenCV 中的 Lucas-Kanade 光流 OpenCV 中的密集光流 目标 在本章中,将学习: 使用 Lucas-Kanade 方法理解光流的概念及其估计 使用cv2.calcOpticalFlowPyrLK()等函数来跟踪视频中的特征点 使用cv2.calcOpticalFlowFarneback()方法创建一个密集的光流场 光流 光流是由物体或相机的运动引起的图像物体在两个连续帧之间的明显运动的模式.它是二维向量场,其中每个向量都是一个位移向量,显示点从第一帧到第
-

OpenCV特征匹配和单应性矩阵查找对象详解
目录 目标 基础 实现 附加资源 目标 在本章中,将学习 将从Calib3D模块中混淆特征匹配和找到(单应性矩阵)homography,以查找复杂图像中的已知对象. 基础 在之前的内容中,使用了一个query image,在其中找到了一些特征点,拍摄了另一张train image,也在该图像中找到了特征,找到了其中最好的匹配.简而言之,在另一张杂乱的图像中找到了物体某些部分的位置.该信息足以准确地在train image上找到对象. 为此,可以使用calib3d模块的函数,即cv2.findHo
-
基于Opencv图像识别实现答题卡识别示例详解
目录 1. 项目分析 2.项目实验 3.项目结果 总结 在观看唐宇迪老师图像处理的课程中,其中有一个答题卡识别的小项目,在此结合自己理解做一个简单的总结. 1. 项目分析 首先在拿到项目时候,分析项目目的是什么,要达到什么样的目标,有哪些需要注意的事项,同时构思实验的大体流程. 图1. 答题卡测试图像 比如在答题卡识别的项目中,针对测试图片如图1 ,首先应当实现的功能是: 能够捕获答题卡中的每个填涂选项. 将获取的填涂选项与正确选项做对比计算其答题正确率. 2.项目实验 在对测试图像进行形态学操
-
Python 使用Opencv实现目标检测与识别的示例代码
在上章节讲述到图像特征检测与匹配 ,本章节是讲述目标检测与识别.后者是在前者的基础上进一步完善. 在本章中,我们使用HOG算法,HOG和SIFT.SURF同属一种类型的描述符.功能代码如下: import cv2 def is_inside(o, i): ox, oy, ow, oh = o ix, iy, iw, ih = i # 如果符合条件,返回True,否则返回False return ox > ix and oy > iy and ox + ow < ix + iw and o
-
基于深度学习和OpenCV实现目标检测
目录 使用深度学习和 OpenCV 进行目标检测 MobileNets:高效(深度)神经网络 使用 OpenCV 进行基于深度学习的对象检测 使用 OpenCV 检测视频 使用深度学习和 OpenCV 进行目标检测 基于深度学习的对象检测时,您可能会遇到三种主要的对象检测方法: Faster R-CNNs (Ren et al., 2015) You Only Look Once (YOLO) (Redmon et al., 2015) Single Shot Detectors (SSD)(L
-
Qt+OpenCV实现目标检测详解
目录 一.创建项目&UI设计 二.代码与演示 演示效果 拓展阅读 一.创建项目&UI设计 创建项目,UI设计如下 文件类型判断 简单的判断文件类型 QString file("sample.jpg"); if (file.contains(".jpg") || file.contains(".bmp") || file.contains(".png")) qDebug()<<"这是图片.&
-
Opencv基于CamShift算法实现目标跟踪
CamShift算法全称是"Continuously Adaptive Mean-Shift"(连续的自适应MeanShift算法),是对MeanShift算法的改进算法,可以在跟踪的过程中随着目标大小的变化实时调整搜索窗口大小,对于视频序列中的每一帧还是采用MeanShift来寻找最优迭代结果,至于如何实现自动调整窗口大小的,可以查到的论述较少,我的理解是通过对MeanShift算法中零阶矩的判断实现的. 在MeanShift算法中寻找搜索窗口的质心用到窗口的零阶矩M00和一阶矩M1
-
Python Opencv实现单目标检测的示例代码
一 简介 目标检测即为在图像中找到自己感兴趣的部分,将其分割出来进行下一步操作,可避免背景的干扰.以下介绍几种基于opencv的单目标检测算法,算法总体思想先尽量将目标区域的像素值全置为1,背景区域全置为0,然后通过其它方法找到目标的外接矩形并分割,在此选择一张前景和背景相差较大的图片作为示例. 环境:python3.7 opencv4.4.0 二 背景前景分离 1 灰度+二值+形态学 轮廓特征和联通组件 根据图像前景和背景的差异进行二值化,例如有明显颜色差异的转换到HSV色彩空间进行分割. 1
-
Python OpenCV基于霍夫圈变换算法检测图像中的圆形
目录 第一章:霍夫变换检测圆 ① 实例演示1 ② 实例演示2 ③ 霍夫变换函数解析 第二章:Python + opencv 完整检测代码 ① 源代码 ② 运行效果图 第一章:霍夫变换检测圆 ① 实例演示1 这个是设定半径范围 0-50 后的效果. ② 实例演示2 这个是设定半径范围 50-70 后的效果,因为原图稍微大一点,半径也大了一些. ③ 霍夫变换函数解析 cv.HoughCircles() 方法 参数分别为:image.method.dp.minDist.param1.param2.mi
-
python目标检测基于opencv实现目标追踪示例
目录 主要代码 信息封装类 更新utils python-opencv3.0新增了一些比较有用的追踪器算法,这里根据官网示例写了一个追踪器类 程序只能运行在安装有opencv3.0以上版本和对应的contrib模块的python解释器 主要代码 #encoding=utf-8 import cv2 from items import MessageItem import time import numpy as np ''' 监视者模块,负责入侵检测,目标跟踪 ''' class WatchDo
-
python+opencv轮廓检测代码解析
首先大家可以对OpenCV有个初步的了解,可以参考:简单了解OpenCV 轮廓(Contours),指的是有相同颜色或者密度,连接所有连续点的一条曲线.检测轮廓的工作对形状分析和物体检测与识别都非常有用. 在轮廓检测之前,首先要对图片进行二值化或者Canny边缘检测.在OpenCV中,寻找的物体是白色的,而背景必须是黑色的,因此图片预处理时必须保证这一点. import cv2 #读入图片 img = cv2.imread("1.png") # 必须先转化成灰度图 gray = cv2
-
python+opencv+caffe+摄像头做目标检测的实例代码
首先之前已经成功的使用Python做图像的目标检测,这回因为项目最终是需要用摄像头的, 所以实现摄像头获取图像,并且用Python调用CAFFE接口来实现目标识别 首先是摄像头请选择支持Linux万能驱动兼容V4L2的摄像头, 因为之前用学ARM的时候使用的Smart210,我已经确认我的摄像头是支持的, 我把摄像头插上之後自然就在 /dev 目录下看到多了一个video0的文件, 这个就是摄像头的设备文件了,所以我就没有额外处理驱动的部分 一.检测环境 再来在开始前因为之前按着国嵌的指导手册安
-
OpenCV+python实现实时目标检测功能
环境安装 安装Anaconda,官网链接Anaconda 使用conda创建py3.6的虚拟环境,并激活使用 conda create -n py3.6 python=3.6 //创建 conda activate py3.6 //激活 3.安装依赖numpy和imutils //用镜像安装 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy pip install -i https://pypi.tuna.tsinghua