mysql查询表里的重复数据方法
INSERT INTO hk_test(username, passwd) VALUES
('qmf1', 'qmf1'),('qmf2', 'qmf11')
delete from hk_test where username='qmf1' and passwd='qmf1'

MySQL里查询表里的重复数据记录:
先查看重复的原始数据:

场景一:列出username字段有重读的数据
select username,count(*) as count from hk_test group by username having count>1; SELECT username,count(username) as count FROM hk_test GROUP BY username HAVING count(username) >1 ORDER BY count DESC;

这种方法只是统计了该字段重复对应的具体的个数
场景二:列出username字段重复记录的具体指:
select * from hk_test where username in (select username from hk_test group by username having count(username) > 1) SELECT username,passwd FROM hk_test WHERE username in ( SELECT username FROM hk_test GROUP BY username HAVING count(username)>1) 但是这条语句在mysql中效率太差,感觉mysql并没有为子查询生成临时表。在数据量大的时候,耗时很长时间

解决方法:
于是使用先建立临时表 create table `tmptable` as ( SELECT `name` FROM `table` GROUP BY `name` HAVING count(`name`) >1 ); 然后使用多表连接查询 SELECT a.`id`, a.`name` FROM `table` a, `tmptable` t WHERE a.`name` = t.`name`; 结果这次结果很快就出来了。 用 distinct去重复 SELECT distinct a.`id`, a.`name` FROM `table` a, `tmptable` t WHERE a.`name` = t.`name`;
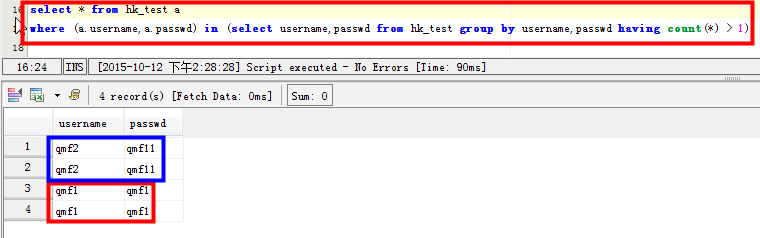
场景三:查看两个字段都重复的记录:比如username和passwd两个字段都有重复的记录:
select * from hk_test a where (a.username,a.passwd) in (select username,passwd from hk_test group by username,passwd having count(*) > 1)
场景四:查询表中多个字段同时重复的记录:
select username,passwd,count(*) from hk_test group by username,passwd having count(*) > 1

MySQL查询表内重复记录 查询及删除重复记录的方法 (一) 1、查找表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断 select * from people where peopleId in (select peopleId from people group by peopleId having count(peopleId)>1) 2、删除表中多余的重复记录,重复记录是根据单个字段(peopleId)来判断,只留有一个记录 delete from people where peopleId in (select peopleId from people group by peopleId having count(peopleId)>1) and min(id) not in (select id from people group by peopleId having count(peopleId)>1) 3、查找表中多余的重复记录(多个字段) select * from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*)>1) 4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录 delete from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1) and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1) 5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录 select * from vitae a where (a.peopleId,a.seq) in (select peopleId,seq from vitae group by peopleId,seq having count(*) > 1) and rowid not in (select min(rowid) from vitae group by peopleId,seq having count(*)>1) (二) 比方说 在A表中存在一个字段“name”,而且不同记录之间的“name”值有可能会相同,现在就是需要查询出在该表中的各记录之间,“name”值存在重复的项; Select Name,Count(*) From A Group By Name Having Count(*) > 1 如果还查性别也相同大则如下: Select Name,sex,Count(*) From A Group By Name,sex Having Count(*) > 1 (三) 方法一 declare @max integer,@id integer declare cur_rows cursor local for select 主字段,count(*) from 表名 group by 主字段 having count(*) >; 1 open cur_rows fetch cur_rows into @id,@max while @@fetch_status=0 begin select @max = @max -1 set rowcount @max delete from 表名 where 主字段 = @id fetch cur_rows into @id,@max end close cur_rows set rowcount 0

SELECT * from tab1 where CompanyName in( SELECT companyname from tab1 GROUP BY CompanyName HAVING COUNT(*)>1); -- 129.433ms SELECT * from tab1 INNER join ( SELECT companyname from tab1 GROUP BY CompanyName HAVING COUNT(*)>1) as tab2 USING(CompanyName); -- 0.482ms 方法二 有两个意义上的重复记录,一是完全重复的记录,也即所有字段均重复的记录,二是部分关键字段重复的记录,比如Name字段重复,而其他字段不一定重复或都重复可以忽略。 1、对于第一种重复,比较容易解决,使用 select distinct * from tableName 就可以得到无重复记录的结果集。 如果该表需要删除重复的记录(重复记录保留1条),可以按以下方法删除 select distinct * into #Tmp from tableName drop table tableName select * into tableName from #Tmp drop table #Tmp 发生这种重复的原因是表设计不周产生的,增加唯一索引列即可解决。 2、这类重复问题通常要求保留重复记录中的第一条记录,操作方法如下 假设有重复的字段为Name,Address,要求得到这两个字段唯一的结果集 select identity(int,1,1) as autoID, * into #Tmp from tableName select min(autoID) as autoID into #Tmp2 from #Tmp group by Name,autoID select * from #Tmp where autoID in(select autoID from #tmp2) 最后一个select即得到了Name,Address不重复的结果集(但多了一个autoID字段,实际写时可以写在select子句中省去此列) (四)查询重复 select * from tablename where id in ( select id from tablename group by id having count(id) > 1) 常用的语句 1、查找表中多余的重复记录,重复记录是根据单个字段(mail_id)来判断 代码如下 复制代码 SELECT * FROM table WHERE mail_id IN (SELECT mail_id FROM table GROUP BY mail_id HAVING COUNT(mail_id) > 1); 2、删除表中多余的重复记录,重复记录是根据单个字段(mail_id)来判断,只留有rowid最小的记录 代码如下 复制代码 DELETE FROM table WHERE mail_id IN (SELECT mail_id FROM table GROUP BY mail_id HAVING COUNT(mail_id) > 1) AND rowid NOT IN (SELECT MIN(rowid) FROM table GROUP BY mail_id HAVING COUNT(mail_id )>1); 3、查找表中多余的重复记录(多个字段) 代码如下 复制代码 SELECT * FROM table WHERE (mail_id,phone) IN (SELECT mail_id,phone FROM table GROUP BY mail_id,phone HAVING COUNT(*) > 1); 4、删除表中多余的重复记录(多个字段),只留有rowid最小的记录 代码如下 复制代码 DELETE FROM table WHERE (mail_id,phone) IN (SELECT mail_id,phone FROM table GROUP BY mail_id,phone HAVING COU(www.jb51.net)NT(*) > 1) AND rowid NOT IN (SELECT MIN(rowid) FROM table GROUP BY mail_id,phone HAVING COUNT(*)>1); 5、查找表中多余的重复记录(多个字段),不包含rowid最小的记录 代码如下 复制代码 SELECT * FROM table WHERE (a.mail_id,a.phone) IN (SELECT mail_id,phone FROM table GROUP BY mail_id,phone HAVING COUNT(*) > 1) AND rowid NOT IN (SELECT MIN(rowid) FROM table GROUP BY mail_id,phone HAVING COUNT(*)>1); 存储过程 declare @max integer,@id integer declare cur_rows cursor local for select 主字段,count(*) from 表名 group by 主字段 having count(*) >; 1 open cur_rows fetch cur_rows into @id,@max while @@fetch_status=0 begin select @max = @max -1 set rowcount @max delete from 表名 where 主字段 = @id fetch cur_rows into @id,@max end close cur_rows set rowcount 0 (一)单个字段 1、查找表中多余的重复记录,根据(question_title)字段来判断 代码如下 复制代码 select * from questions where question_title in (select question_title from people group by question_title having count(question_title) > 1) 2、删除表中多余的重复记录,根据(question_title)字段来判断,只留有一个记录 代码如下 复制代码 delete from questions where peopleId in (select peopleId from people group by peopleId having count(question_title) > 1) and min(id) not in (select question_id from questions group by question_title having count(question_title)>1) (二)多个字段 删除表中多余的重复记录(多个字段),只留有rowid最小的记录 代码如下 复制代码 DELETE FROM questions WHERE (questions_title,questions_scope) IN (SELECT questions_title,questions_scope FROM que(www.jb51.net)stions GROUP BY questions_title,questions_scope HAVING COUNT(*) > 1) AND question_id NOT IN (SELECT MIN(question_id) FROM questions GROUP BY questions_scope,questions_title HAVING COUNT(*)>1) 用上述语句无法删除,创建了临时表才删的,求各位达人解释一下。 代码如下 复制代码 CREATE TABLE tmp AS SELECT question_id FROM questions WHERE (questions_title,questions_scope) IN (SELECT questions_title,questions_scope FROM questions GROUP BY questions_title,questions_scope HAVING COUNT(*) > 1) AND question_id NOT IN (SELECT MIN(question_id) FROM questions GROUP BY questions_scope,questions_title HAVING COUNT(*)>1); DELETE FROM questions WHERE question_id IN (SELECT question_id FROM tmp); DROP TABLE tmp;
查找mysql数据表中重复记录
mysql数据库中的数据越来越多,当然排除不了重复的数据,在维护数据的时候突然想到要把多余的数据给删减掉,剩下有价值的数据。
以下sql语句可以实现查找出一个表中的所有重复的记录.
select user_name,count(*) as count from user_table group by user_name having count>1;
参数说明:
user_name为要查找的重复字段.
count用来判断大于一的才是重复的.
user_table为要查找的表名.
group by用来分组
having用来过滤.
把参数换成自己数据表的相应字段参数,可以先在Phpmyadmin里面或者Navicat里面去运行,看看有哪些数据重复了,然后在数据库里面删除掉,也可以直接将SQL语句放到后台读取新闻的页面里面读取出来,完善成查询重复数据的列表,有重复的可以直接删除。
效果如下:

缺点:这种方法的缺点就是当你的数据库里面的数据量很大的时候,效率很低,我用的是Navicat测试的,数据量不大,效率很高,当然,网站还有其它查询数据重复的SQL语句,举一反三,大家好好研究研究,找到一个适合自己网站的查询语句。
相关推荐
-

MySQL 删除数据库中重复数据方法小结
刚开始,根据我的想法,这个很简单嘛,上sql语句 delete from zqzrdp where tel in (select min(dpxx_id) from zqzrdp group by tel having count(tel)>1); 执行,报错!!~!~ 异常意为:你不能指定目标表的更新在FROM子句.傻了,MySQL 这样写,不行,让人郁闷. 难倒只能分步操作,蛋疼 以下是网友写的,同样是坑爹的代码,我机器上运行不了. 1. 查询需要删除的记录,会保留一条记录. select
-
MySQL 查询某个字段不重复的所有记录
假设现在有如下N条记录 表明叫book id author title 1 aaa AAA 2 bbb BBB 3 ccc CCC 4 ddd DDD 5 eee AAA 现在想从这5条记录中查询所有title不重复的记录 select distinct title,author from book这样是不可以的 因为distinct只能作用于一个字段 想请教应该怎么写 答案: 复制代码 代码如下: select a.* from book a right join ( select max(i
-
mysql删除重复记录语句的方法
例如: id name value 1 a pp 2 a pp 3 b iii 4 b pp 5 b pp 6 c pp 7 c pp 8 c iii id是主键 要求得到这样的结果 id name value 1 a pp 3 b iii 4 b pp 6 c pp 8 c iii 方法1 delete YourTable where [id] not in ( select max([id]) from YourTable group by (name + value)) 方法2 delet
-
MySql避免重复插入记录的几种方法
方案一:使用ignore关键字 如果是用主键primary或者唯一索引unique区分了记录的唯一性,避免重复插入记录可以使用: 复制代码 代码如下: INSERT IGNORE INTO `table_name` (`email`, `phone`, `user_id`) VALUES ('test9@163.com', '99999', '9999'); 这样当有重复记录就会忽略,执行后返回数字0 还有个应用就是复制表,避免重复记录: 复制代码 代码如下: INSERT IGNORE INT
-
mysql 查询重复的数据的SQL优化方案
在mysql中查询不区分大小写重复的数据,往往会用到子查询,并在子查询中使用upper函数来将条件转化为大写.如: 复制代码 代码如下: select * from staticcatalogue WHERE UPPER(Source) IN (SELECT UPPER(Source) FROM staticcatalogue GROUP BY UPPER(Source) having count(UPPER(Source))>1) ORDER BY upper(Source) DESC; 这条
-
MySQL中distinct语句去查询重复记录及相关的性能讨论
在 MySQL 查询中,可能会包含重复值.这并不成问题,不过,有时您也许希望仅仅列出不同(distinct)的值. 关键词 DISTINCT 用于返回唯一不同的值,就是去重啦.用法也很简单: SELECT DISTINCT * FROM tableName DISTINCT 这个关键字来过滤掉多余的重复记录只保留一条. 另外,如果要对某个字段去重,可以试下: SELECT *, COUNT(DISTINCT nowamagic) FROM table GROUP BY nowamagic 这个用
-
MySQL大表中重复字段的高效率查询方法
MySQL大表重复字段应该如何查询到呢?这是很多人都遇到的问题,下面就教您一个MySQL大表重复字段的查询方法,供您参考. 数据库中有个大表,需要查找其中的名字有重复的记录id,以便比较.如果仅仅是查找数据库中name不重复的字段,很容易 复制代码 代码如下: SELECT min(`id`),`name` FROM `table` GROUP BY `name`; 但是这样并不能得到说有重复字段的id值.(只得到了最小的一个id值)查询哪些字段是重复的也容易 复制代码 代码如下: SELEC
-
mysql 数据表中查找重复记录
复制代码 代码如下: select user_name,count(*) as count from user_table group by user_name having count>1; 这个我在很早有发过一个asp下的ACCESS 的
-
Mysql一些复杂的sql语句(查询与删除重复的行)
1.查找重复的行 SELECT * FROM blog_user_relation a WHERE (a.account_instance_id,a.follow_account_instance_id) IN (SELECT account_instance_id,follow_account_instance_id FROM blog_user_relation GROUP BY account_instance_id, follow_account_instance_id HAVING C
-
MySQL中查询、删除重复记录的方法大全
前言 本文主要给大家介绍了关于MySQL中查询.删除重复记录的方法,分享出来供大家参考学习,下面来看看详细的介绍: 查找所有重复标题的记录: select title,count(*) as count from user_table group by title having count>1; SELECT * FROM t_info a WHERE ((SELECT COUNT(*) FROM t_info WHERE Title = a.Title) > 1) ORDER BY Titl