Sql学习第四天——SQL 关于with cube,with rollup和grouping解释及演示
关于with cube ,with rollup 和 grouping
通过查看sql 2005的帮助文档找到了CUBE 和 ROLLUP 之间的具体区别:
CUBE 生成的结果集显示了所选列中值的所有组合的聚合。ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合。
再看看对grouping的解释:
当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。
仅在与包含 CUBE 或 ROLLUP 运算符的 GROUP BY 子句相关联的选择列表中才允许分组。
当看到以上的解释肯定非常的模糊,不知所云和不知道该怎样用,下面通过实例操作来体验一下:
CREATE TABLE [dbo].[PeopleInfo](
[id] [int] IDENTITY(1,1) NOT NULL,
[name] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[numb] [nchar](10) COLLATE Chinese_PRC_CI_AS NOT NULL,
[phone] [nchar](10) COLLATE Chinese_PRC_CI_AS NULL,
[FenShu] [int] NULL
) ON [PRIMARY]
insert into peopleinfo([name],numb,phone,fenshu) values ('李欢','3223','1365255',80)
insert into peopleinfo([name],numb,phone,fenshu) values ('李欢','322123','1',90)
insert into peopleinfo([name],numb,phone,fenshu) values ('李名','3213112352','13152',56)
insert into peopleinfo([name],numb,phone,fenshu) values ('李名','32132312','13342563',60)
insert into peopleinfo([name],numb,phone,fenshu) values ('王华','3223','1365255',80)
select * from dbo.PeopleInfo
结果如图:

操作一:先试试:1, 查询所有数据;2,用group by 查询所有数据;3,用with cube。这三种情况的比较
select * from dbo.PeopleInfo --1, 查询所有数据;
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb --2,用group by 查询所有数据;
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with cube --3,用with cube。这三种情况的比较
结果如图:

结果分析:
用第三种(用with cube)为什么会多出来有null的字段值呢?通过分析图上的值得组合会发现是怎么回事儿了,以第三条数据(李欢,null,170)为例:它只是把姓名是【李欢】的分为了一组,而没有考虑【numb】,所以有多出来了第三条数据,也说明了170是怎么来的。其他的也是这样。再回顾一下帮助文档的解释:CUBE 生成的结果集显示了所选列中值的所有组合的聚合, 发现明了了许多。
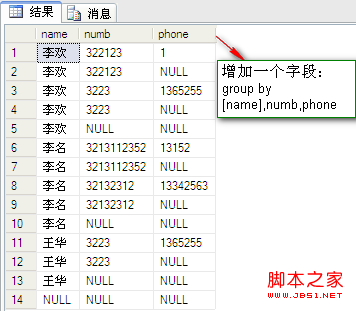
操作二:1,用with cube;2,用with rollup 这两种情况的比较
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with cube --用with cube。
select [name],numb,sum(fenshu) from dbo.PeopleInfo group by [name],numb with rollup --用with rollup。
结果如图:

结果分析:
为什么with cube 比 with rollup多出来一部分呢?原来它没有显示,以【numb】分组而不考虑【name】的数据情况。再回顾一下帮助文档的解释:ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合,那这个【某一层次】又是以什么为标准的呢?我的猜想是:距离group up最近的字段必须考虑在分组内。
证明猜想实例:
操作:用两个group up 交换字段位置的sql语句和一个在group up 后面增加一个字段的sql语句进行比较:
select [name],numb from dbo.PeopleInfo group by [name],numb with rollup
select [name],numb from dbo.PeopleInfo group by numb,[name] with rollup
select [name],numb,phone from dbo.PeopleInfo group by [name],numb,phone with rollup
结果如图:
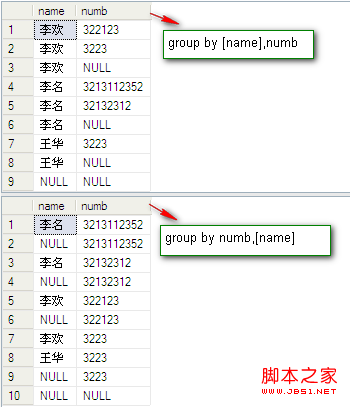
通过结果图的比较发现猜想是正确的。
---------------------------------------------------grouping-------------------------------------------------
现在来看看grouping的实例:
SQL语句看看与with rollup的结合(与with cube的结合是一样的):
代码如下:
select [name],numb,grouping(numb) from dbo.PeopleInfo group by [name],numb with rollup
结果如图:

结果分析:
结合帮助文档的解释:当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1;当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0。 很容易理解再此就不多解释了。
相关推荐
-
SQLServer中汇总功能的使用GROUPING,ROLLUP和CUBE
第一次看到这样的SQL语句,看不懂,其中用到了下面的不常用的 聚集函数:GROUPING 用于汇总数据用的运算符: ROLLUP SELECT CASE GROUPING(o.customerid) WHEN 0 THEN o.customerid ELSE '(Total)' END AS AllCustomersSummary, CASE GROUPING(od.orderid) WHEN 0 THEN od.orderid ELSE -1 END AS IndividualCustome
-
SQLServer 数据库的数据汇总完全解析(WITH ROLLUP)
现有表A,内容如下: 编码 仓库 数量 01 A 6 01 B 7 02 A 8 02 B 9 现在想按编码查询出这种格式: 01 A 6 01 B 7 汇总小计: 13 02 A 8 02 B 9 汇总小计: 17 问:该如何实现? 乍一看,好像很容易,用group by好像能实现?但仔细研究下去,你又会觉得group by也是无能为力,总欠缺点什么,无从下手.那么,到底该如何做呢?别急,SQL Server早就帮我们做好了,下面,跟我来. 首先,让我们来看一段话: 在生成包含小计和合计的报表
-
SQLSERVER中union,cube,rollup,cumpute运算符使用说明
/* --1 UNION 运算符是将两个或更多查询的结果组合为单个结果集 使用 UNION 组合查询的结果集有两个最基本的规则: 1.所有查询中的列数和列的顺序必须相同. 2.数据类型必须兼容 a.UNION的结果集列名与第一个select语句中的结果集中的列名相同,其他select语句的结果集列名被忽略 b.默认情况下,UNION 运算符是从结果集中删除重复行.如果使用all关键字,那么结果集将包含所有行并且不删除重复行 c.sql是从左到右对包含UNION 运算符的语句进行取值,使用括号可以
-
Sql Server 分组统计并合计总数及WITH ROLLUP应用
WITH ROLLUP 在生成包含小计和合计的报表时,ROLLUP 运算符很有用.ROLLUP 运算符生成的结果集类似于 CUBE 运算符所生成的结果集. 复制代码 代码如下: SELECT [Source], COUNT(*) AS OrderTotal FROM [ExternalOrder] Where OrderStatus=1 AND (CheckPayment=1 ) and TicketDate >= '2012-11-1' AND TicketDate < '2012-12-1
-

Sql学习第四天——SQL 关于with cube,with rollup和grouping解释及演示
关于with cube ,with rollup 和 grouping 通过查看sql 2005的帮助文档找到了CUBE 和 ROLLUP 之间的具体区别: CUBE 生成的结果集显示了所选列中值的所有组合的聚合.ROLLUP 生成的结果集显示了所选列中值的某一层次结构的聚合. 再看看对grouping的解释: 当行由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 1:当行不由 CUBE 或 ROLLUP 运算符添加时,该函数将导致附加列的输出值为 0. 仅在与包含 C
-
SQL学习笔记四 聚合函数、排序方法
聚合函数 count,max,min,avg,sum... select count (*) from T_Employee select Max(FSalary) from T_Employee 排序 ASC升序 DESC降序 select * from T_Employee order by Fage 先按年龄降序排列.如果年龄相同,则按薪水升序排列 select * from T_Employee order by FAge DESC,FSalary ASC order by 要放在 wh
-
Sql学习第三天——SQL 关于CTE(公用表达式)的递归查询使用
关于使用CTE(公用表表达式)的递归查询----SQL Server 2005及以上版本 公用表表达式 (CTE) 具有一个重要的优点,那就是能够引用其自身,从而创建递归 CTE.递归 CTE 是一个重复执行初始 CTE 以返回数据子集直到获取完整结果集的公用表表达式. 当某个查询引用递归 CTE 时,它即被称为递归查询.递归查询通常用于返回分层数据,例如:显示某个组织图中的雇员或物料清单方案(其中父级产品有一个或多个组件,而那些组件可能还有子组件,或者是其他父级产品的组件)中的数据. 递归 C
-
Sql学习第三天——SQL 关于with ties介绍
关于with ties 对于with ties一般是和Top , order by相结合使用的,会查询出最后一条数据额外的返回值(解释:如果按照order by 参数排序TOP n(PERCENT)返回了前面n(pencent)个记录,但是n+1-n+k条记录和排序后的第n条记录的参数值(order by 后面的参数)相同,则n+1.-.n+k也返回.n+1.-.n+k就是额外的返回值). 实验: 实验用表(PeopleInfo): 复制代码 代码如下: CREATE TABLE [dbo].[
-
SQL注入的四种防御方法总结
目录 前言 限制数据类型 正则表达式匹配传入参数 函数过滤转义 预编译语句 总结 前言 最近了解到安全公司的面试中都问到了很多关于SQL注入的一些原理和注入类型的问题,甚至是SQL注入的防御方法.SQL注入真的算是web漏洞中的元老了,著名且危害性极大.下面这里就简单的分享一下我总结的四种SQL注入防御手段,加深理解,方便下次遇到这种问题时可以直接拿来使用.(主要是怕面试中脑壳打铁,这种情况太常见了) SQL注入占我们渗透学习中极大地一部分,拥有这很重要的地位.随着防御手段的不段深入,市面上存在
-
sql语句实现四种九九乘法表
下面用while 和 if 条件写的SQL语句的四种九九乘法表 sql语句实现--x 左下角九九乘法表 DECLARE @I INT ,@J INT,@S VARCHAR() SET @I= WHILE @I< BEGIN SET @J= SET @S='' WHILE @J<=@I BEGIN SET @S=@S+CAST(@J AS CHAR())+'*'+CAST(@I AS CHAR())+'='+CAST((@I*@J)AS CHAR()) SET @J=@J+ END PRINT
-
SQL数据库十四种案例介绍
数据表 /* Navicat SQLite Data Transfer Source Server : school Source Server Version : 30808 Source Host : :0 Target Server Type : SQLite Target Server Version : 30808 File Encoding : 65001 Date: 2021-12-23 16:06:04 */ PRAGMA foreign_keys = OFF; -- -----
-
pandas学习之txt与sql文件的基本操作指南
目录 前言 1.导入txt文件 2.导入sql文件 2.1 安装依赖库pymysql 3.小结 总结 前言 Pandas是python的一个数据分析包,是基于NumPy的一种工具提供了大量数据结构和函数,可以很方便的处理结构化数据,常见数据结构有: Series:一维数组,与Numpy中的一维array类似. DataFrame:二维的表格型数据结构,可以将DataFrame理解为Series的容器 Time- Series:以时间为索引的Series Panel :三维的数组,可以理解为Dat
-
SQL常用的四个排序函数梳理
目录 前言 1.ROW_NUMBER() 1.1 对学生成绩排序示例 2.RANK() 3.DENSE_RANK() 4.NTILE() 前言 今天就给大家介绍四个你不怎么常用排序函数,他们就是SQL Server排序中经常用到的ROW_NUMBER(),RANK(),DENSE_RANK(),NTILE()这四个好兄弟. 我们在写SQL代码时,只要有排序,首先想到的肯定是ORDER BY,以至于好多小伙伴觉得排序多简单啊. 今天就给大家介绍四个你不怎么常用排序函数,他们就是SQL Server
-
MyBatis学习教程(四)-如何快速解决字段名与实体类属性名不相同的冲突问题
在项目开发中,我们经常会遇到表中的字段名和表对应实体类的属性名称不一定都是完全相同的情况,下面小编给大家演示一下这种情况下的如何解决字段名与实体类属性名不相同的冲突问题,感兴趣的朋友一起学习吧. 一.准备演示需要使用的表和数据 CREATE TABLE orders( order_id INT PRIMARY KEY AUTO_INCREMENT, order_no VARCHAR(20), order_price FLOAT ); INSERT INTO orders(order_no, or