Spring Cloud Stream分区分组原理图解
消息分组
通常在生产环境,我们的每个服务都不会以单节点的方式运行在生产环境,当同一个服务启动多个实例的时候,这些实例都会绑定到同一个消息通道的目标主题(Topic)上。默认情况下,当生产者发出一条消息到绑定通道上,这条消息会产生多个副本被每个消费者实例接收和处理,但是有些业务场景之下,我们希望生产者产生的消息只被其中一个实例消费,这个时候我们需要为这些消费者设置消费组来实现这样的功能。

当把消费者复制一份,发现2个都能收到消息

2个消费者都加入同一个消费者

发现只有一个能收到
消息分区
有一些场景需要满足, 同一个特征的数据被同一个实例消费, 比如同一个id的传感器监测数据必须被同一
个实例统计计算分析, 否则可能无法获取全部的数据。又比如部分异步任务,首次请求启动task,二次
请求取消task,此场景就必须保证两次请求至同一实例.

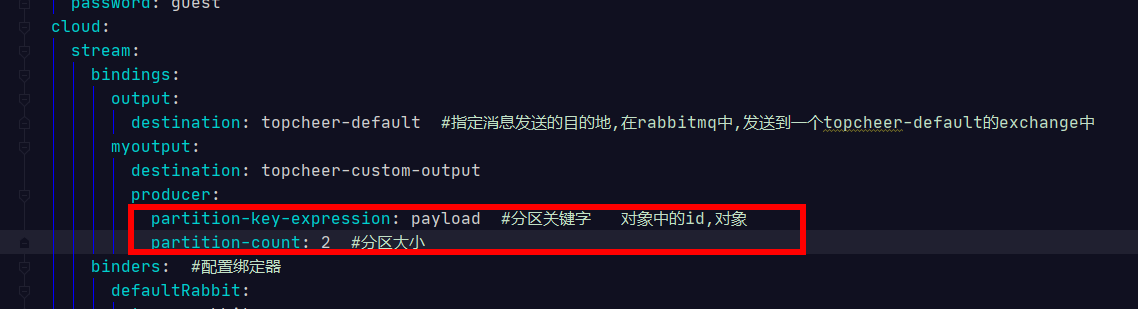


从上面的配置中,我们可以看到增加了这两个参数:
1. pring.cloud.stream.bindings.output.producer.partitionKeyExpression :通过该参数指定了分区键的表达式规则,我们可以根据实际的输出消息规则来配置SpEL来生成合适的分区键;
2. spring.cloud.stream.bindings.output.producer.partitionCount :该参数指定了消息分
区的数量。
到这里消息分区配置就完成了,我们可以再次启动这两个应用,同时消费者启动多个,但需要注意的是要为消费者指定不同的实例索引号,这样当同一个消息被发给消费组时,我们可以发现只有一个消费实例在接收和处理这些相同的消息。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

SpringCloud+MyBatis分页处理(前后端分离)
分页处理,这是做JavaWeb项目中常见的场景. 背景: 1.系统架构:SpringCloud分布式 2.持久层:MyBatis 3.前端:前后分离vue.js/bootstrap等. 后台提供restful api 接口,前端访问后端接口展示数据. 2种方式提供分页处理方案: 一.直接MyBatis数据库进行分页 controller接口 @ApiImplicitParams({ @ApiImplicitParam(name = "categoryId", value = "
-
详解spring cloud分布式日志链路跟踪
首先要明白一点,为什么要使用链路跟踪? 当我们微服务之间调用的时候可能会出错,但是我们不知道是哪个服务的问题,这时候就可以通过日志链路跟踪发现哪个服务出错. 它还有一个好处:当我们在企业中,可能每个人都负责一个服务,我们可以通过日志来检查自己所负责的服务不会出错,当调用其它服务时,这时候出现错误,那么就可以判定出不是自己的服务出错,从而也可以发现责任不是自己的. 基于微服务之间的调用开始,如果看不懂的小伙伴,请先参考我上篇博客:spring cloud中微服务之间的调用以及eureka的自我保护
-
Spring Cloud Hystrix入门和Hystrix命令原理分析
断路由器模式 在分布式架构中,当某个服务单元发生故障之后,通过断路由器的故障监控(类似熔断保险丝),向调用方返回一个错误响应,而不是长时间的等待.这样就不会使得线程因调用故障服务被长时间占用不释放,避免了故障在分布式系统中的蔓延. Spring Cloud Hystrix针对上述问题实现了断路由器.线程隔离等一系列服务保护功能.它是基于Netflix Hystrix实现,该框架的目标在于通过控制那些访问远程系统.服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力. Hystrix具备服务
-
详解spring cloud分布式关于熔断器
spring cloud分布式中,熔断器就是断路器,其实都是一个意思. 为什么要使用熔断器呢? 在分布式中,我们会根据业务或功能将项目拆分为多个服务单元,各个服务单元之间通过服务注册和订阅的方式相互依赖和调用功能,随着项目和业务的不断拓展,服务单元数量也逐渐增多,相互之间的依赖关系也越来越复杂,这时候,可能会某个服务单元出现问题或网络原因依赖调用出错或延迟,此时如果调用该依赖的请求不断增加,那么要调用该服务的服务将都会等待或者出现故障,如果后续连锁反应越来越多,Servlet容器的线程资源会被消
-
SpringCloud整合分布式服务跟踪zipkin的实现
1.zipkin zipkin是Twitter的一个开源项目,它基于Google Dapper实现.我们可以使用它来收集各个服务器上请求链路的跟踪数据,并通过它提供的REST API接口来辅助我们查询跟踪数据以实现对分布式系统的监控程序,从而及时地发现系统中出现的延迟升高问题并找出系统性能瓶颈的根源.除了面向开发的API接口之外,它也提供了方便的UI组件来帮助我们直观的搜索跟踪信息和分析请求链路明细,比如:可以查询某段时间内各用户请求的处理时间等. zipkin的架构图如下: 由上面的架构图可以
-
SpringCloud分布式链路跟踪的方法
注:作者使用IDEA + Gradle 注:需要有一定的java SpringBoot and SSM+Springcloud基础 程序测试错误追责 我举个例子,我现在要做一个电商项目,项目里面有一个购买模块,那我这边可能要执行一个代码,比如减库存之类的东西,那我两个服务不就是要相互调用嘛,我自身是一个服务,我现在要调用减库存这个服务: 你调用它,你知道它一定能执行成功吗?肯定是不一定: 比如说,我现在要执行一个减库存的代码,我调用这个方法会进行库存的一个更改,这个库存减少成功还好,万一要是失败
-
详解spring cloud分布式整合zipkin的链路跟踪
为什么使用zipkin? 上篇主要写了:spring cloud分布式日志链路跟踪 从上篇中可以看出服务之间的调用,假设现在有十几台服务,那么在查找日志的时候比较繁琐.复杂,而且在查看调用的时候也会像蜘蛛网一样,量太大. 这时候zipkin可以把链路调用整个过程给升级起来,只需要到一个地方去查找,就可以知道哪一步出错. zipkin也分为服务器和客户端,服务器就是zipkin,微服务就是客户端. 首先,建立服务器zipkin 在此服务build.gradle加上zipkin的依赖: compil
-
spring cloud 分布式链路追踪的方法
一篇讲了微服务之间的调用spring cloud eureka 微服务之间的调用 微服务之间进行调用 那么如果我负责一个模块 别人负责另一个模块 我调用了他的方法 测试那边却报了错 那是我的问题还是他的问题 这个时候大家应该就能想到日志可以解决这个问题 如何使用日志呢 先在配置文件中加 logging: path: D:\logs\poppy-mall #日志的存放地址 最好再加个项目名的文件夹 可以更容易的区分 level: org.poppy.mall: info #日志的级别 org.po
-
Spring Cloud Stream分区分组原理图解
消息分组 通常在生产环境,我们的每个服务都不会以单节点的方式运行在生产环境,当同一个服务启动多个实例的时候,这些实例都会绑定到同一个消息通道的目标主题(Topic)上.默认情况下,当生产者发出一条消息到绑定通道上,这条消息会产生多个副本被每个消费者实例接收和处理,但是有些业务场景之下,我们希望生产者产生的消息只被其中一个实例消费,这个时候我们需要为这些消费者设置消费组来实现这样的功能. 当把消费者复制一份,发现2个都能收到消息 2个消费者都加入同一个消费者 发现只有一个能收到 消息分区 有一些场
-
一文快速掌握Spring Cloud Stream
目录 一.概述简介 1.1. cloud Stream是什么 1.2. 设计思想 1.4. 注解 二.基于注解代码练习 2.1. 消息驱动之生产者 2.3. 目前存在的问题 2.4. 分组解决重复消费问题 2.5. 消息持久化 三.函数式编程练习 本篇文章所涉及到的demo练习 使用的cloud 2021.0.3+ springboot2.6.8 一.概述简介 官网:https://docs.spring.io/spring-cloud-stream/docs/current/reference
-
Spring Cloud Stream消息驱动组件使用方法介绍
目录 1.Stream解决的痛点问题 2.Stream重要概念 3.传统MQ模型与Stream消息驱动模型 4.Stream消息通信方式及编程模型 4.1.Stream消息通信方式 4.2.Stream编程注解 4.3.Stream消息驱动之开发生产者端 4.4.Stream消息驱动之开发消费者端 5.Stream高级之自定义消息通道 6.Stream高级之消息分组 MQ:消息队列/消息中间件/消息代理,产品有很多,ActiveMQ RabbitMQ RocketMQ Kafka 1.Strea
-
Spring Cloud Stream微服务消息框架原理及实例解析
随着近些年微服务在国内的盛行,消息驱动被提到的越来越多.主要原因是系统被拆分成多个模块后,一个业务往往需要在多个服务间相互调用,不管是采用HTTP还是RPC都是同步的,不可避免快等慢的情况发生,系统性能上很容易遇到瓶颈.在这样的背景下,将业务中实时性要求不是特别高且非主干的部分放到消息队列中是很好的选择,达到了异步解耦的效果. 目前消息队列有很多优秀的中间件,目前使用较多的主要有 RabbitMQ,Kafka,RocketMQ 等,这些中间件各有优势,有的对 AMQP(应用层标准高级消息队列协议
-
详解Spring Cloud Stream使用延迟消息实现定时任务(RabbitMQ)
我们在使用一些开源调度系统(比如:elastic-job等)的时候,对于任务的执行时间通常都是有规律性的,可能是每隔半小时执行一次,或者每天凌晨一点执行一次.然而实际业务中还存在另外一种定时任务,它可能需要一些触发条件才开始定时,比如:编写博文时候,设置2小时之后发送.对于这些开始时间不确定的定时任务,我们也可以通过Spring Cloud Stream来很好的处理. 为了实现开始时间不确定的定时任务触发,我们将引入延迟消息的使用.RabbitMQ中提供了关于延迟消息的插件,所以本文就来具体介绍
-
Spring Cloud Stream异常处理过程解析
应用处理 当消费者在处理接收到的消息时,有可能会由于某些原因而抛出异常.若希望对抛出来的异常进行处理的话,就需要采取一些异常处理手段,异常处理的方式可分为三种:应用层面的处理.系统层面的处理以及通过RetryTemplate进行处理. 本小节先来介绍较为常用的应用层面的异常处理方式,该方式又细分为局部处理和全局处理. 局部处理 Stream相关的配置内容如下: spring: cloud: stream: rocketmq: binder: name-server: 192.168.190.12
-
Spring Cloud Stream如何实现服务之间的通讯
Spring Cloud Stream Srping cloud Bus的底层实现就是Spring Cloud Stream,Spring Cloud Stream的目的是用于构建基于消息驱动(或事件驱动)的微服务架构.Spring Cloud Stream本身对Spring Messaging.Spring Integration.Spring Boot Actuator.Spring Boot Externalized Configuration等模块进行封装(整合)和扩展,下面我们实现两个
-
spring cloud Ribbon用法及原理解析
这篇文章主要介绍了spring cloud Ribbon用法及原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 简介 这篇文章主要介绍一下ribbon在程序中的基本使用,在这里是单独拿出来写用例测试的,实际生产一般是配置feign一起使用,更加方便开发.同时这里也通过源码来简单分析一下ribbon的基本实现原理. 基本使用 这里使用基于zookeeper注册中心+ribbon的方式实现一个简单的客户端负载均衡案例. 服务提供方 首先是一个
-
Spring Cloud Stream简单用法
目录 简单使用Spring Cloud Stream 构建基于RocketMQ的生产者和消费者 生产者 消费者 Stream其他特性 消息发送失败的处理 消费者错误处理 Spring Cloud Stream对Spring Cloud体系中的Mq进⾏了很好的上层抽象,可以让我们与具体消息中间件解耦合,屏蔽掉了底层具体MQ消息中间件的细节差异,就像Hibernate屏蔽掉了具体数据库(Mysql/Oracle⼀样).如此⼀来,我们学习.开发.维护MQ都会变得轻松.⽬前Spring Cloud St
-
Spring Cloud Stream 高级特性使用详解
目录 重试 消息发送失败的处理 消费错误处理 自定义MessageHandler类型 Endpoint端点 Metrics指标 Serverless Partition统一 Polling Consumer 支持多个Binder同时使用 建立事件机制 重试 Consumer端可以配置重试次数,当消息消费失败的时候会进行重试. 底层使用Spring Retry去重试,重试次数可自定义配置. # 默认重试次数为3,配置大于1时才会生效 spring.cloud.stream.bindings.<ch