Sharding-JDBC自动实现MySQL读写分离的示例代码
目录
- 一、ShardingSphere和Sharding-JDBC概述
- 1.1、ShardingSphere简介
- 1.2、Sharding-JDBC简介
- 1.3、Sharding-JDBC作用
- 1.4、ShardingSphere规划线路图
- 1.5、ShardingSphere三种产品的区别
- 二、数据库中间件
- 2.1、数据库中间件简介
- 2.2、Sharding-JDBC和MyCat区别
- 三、Sharding-JDBC+MyBatisPlus实现读写分离
- 3.0、项目代码结构和建表SQL语句
- 3.1、引入Maven依赖
- 3.2、yml文件配置
- 3.3、UserEntity实体类
- 3.4、UserMapper接口
- 3.5、UserService类
- 3.6、UserController类
- 3.7、项目启动测试
- 四、HikariCP连接池使用遇到的两个Bug
- 五、读写分离架构,经常出现的读延迟的问题如何解决?
- 参考链接:
前言:上一篇博客我用AOP+AbstractRoutingDataSource实现了MySQL读写分离,自己写代码实现判断该使用哪个数据源挺麻烦的。Sharding-JDBC 是 Apache 旗下的 ShardingSphere 中的一款轻量级产品,引入 jar 即可完成读写分离的需求,可以理解为增强版的 JDBC,现在被使用的较多。使用Sharding-JDBC配置MySQL读写分离,优点在于数据源完全有Sharding-JDBC托管,写操作自动执行master库,读操作自动执行slave库。不需要程序员在程序中关注这个实现,比你自己去配多数据源简单多了。
一、ShardingSphere和Sharding-JDBC概述
1.1、ShardingSphere简介
在介绍Sharding-JDBC之前,有必要先介绍下Sharding-JDBC的大家族ShardingSphere。在介绍ShardingSphere之后,相信大家会对ShardingSphere的整体架构以及Sharding-JDBC扮演的角色会有更深的了解。
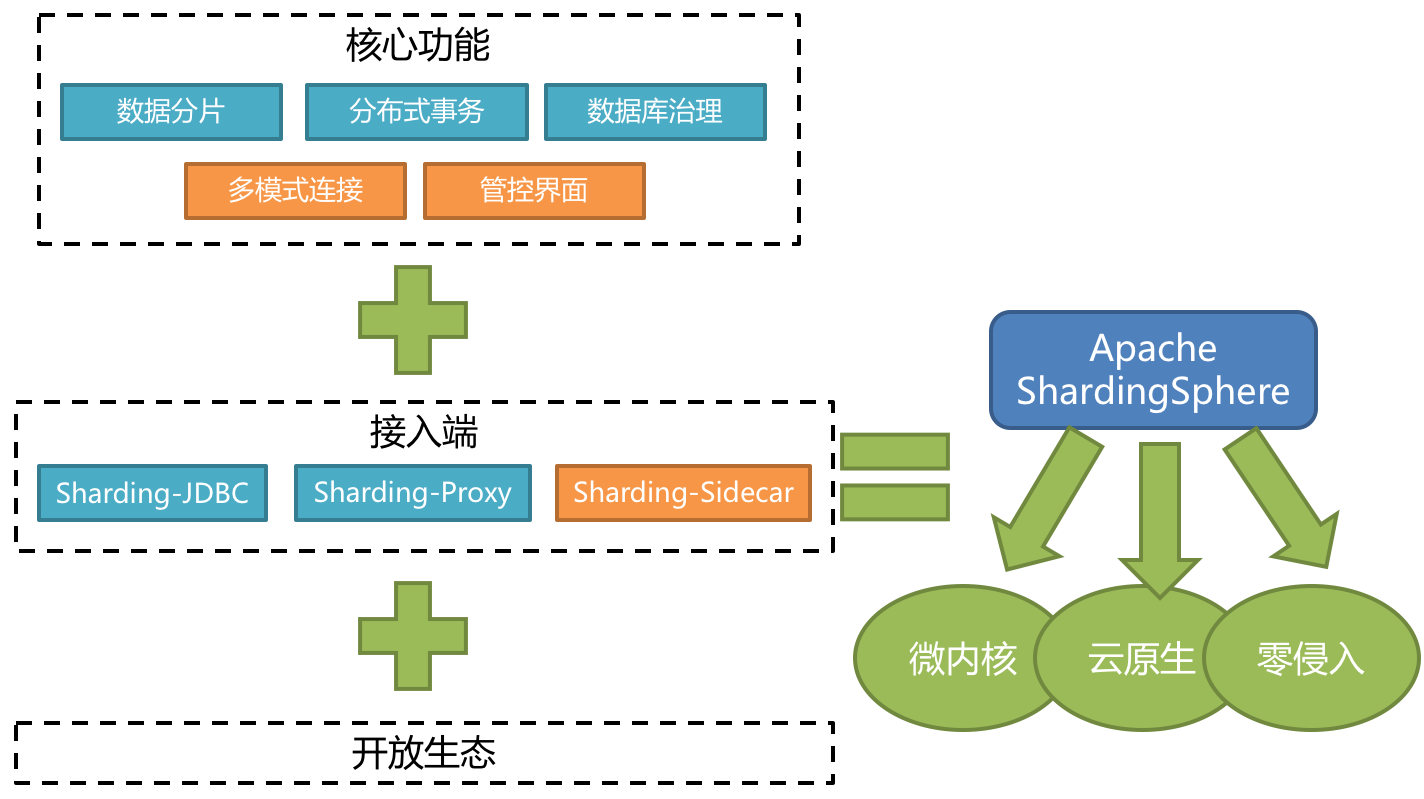
ShardingSphere是后来规划的,最开始是只有 Sharding-JDBC 一款产品,基于客户端形式的分库分表。后面发展变成了现在的Apache ShardingSphere(Incubator) ,它是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(规划中)这3款相互独立,却又能够混合部署配合使用的产品组成。它们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、容器、云原生等各种多样化的应用场景。
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它与NoSQL和NewSQL是并存而非互斥的关系。NoSQL和NewSQL作为新技术探索的前沿,放眼未来,拥抱变化,是非常值得推荐的。反之,也可以用另一种思路看待问题,放眼未来,关注不变的东西,进而抓住事物本质。 关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
1.2、Sharding-JDBC简介
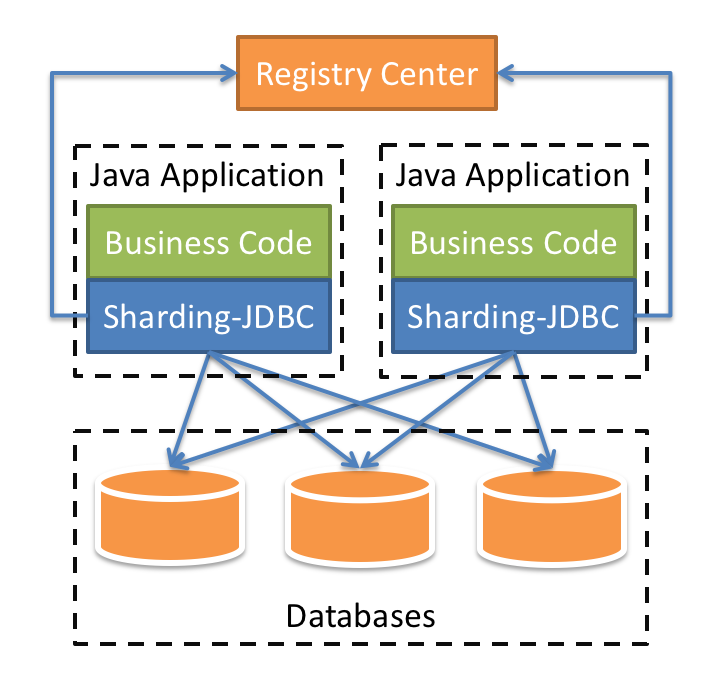
定位为轻量级Java框架,在Java的JDBC层提供的额外服务。 它使用客户端直连数据库,以jar包形式提供服务,无需额外部署和依赖,可理解为增强版的JDBC驱动,完全兼容JDBC和各种ORM框架。
- 适用于任何基于Java的ORM框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template或直接使用JDBC。
- 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP等。
- 支持任意实现JDBC规范的数据库。目前支持MySQL,Oracle,SQLServer和PostgreSQL。
1.3、Sharding-JDBC作用

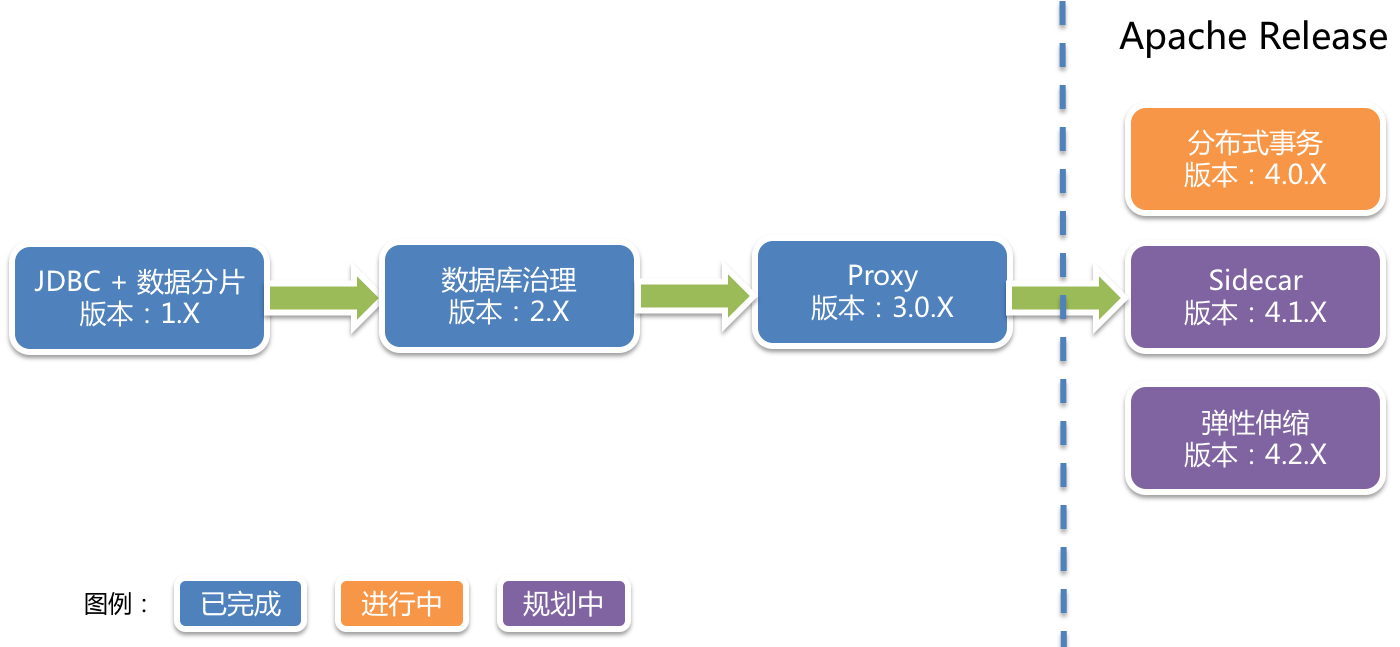
1.4、ShardingSphere规划线路图
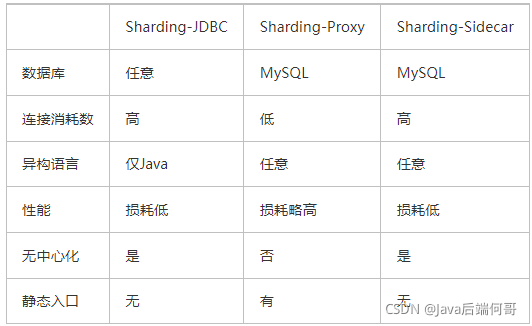
1.5、ShardingSphere三种产品的区别
二、数据库中间件
透明化读写分离所带来的影响,让使用方尽量像使用一个数据库一样使用主从数据库,是读写分离数据库中间件的主要功能。
2.1、数据库中间件简介
数据库中间件可以简化对读写分离以及分库分表的操作,并隐藏底层实现细节,可以像操作单库单表那样操作多库多表,主流的设计方案主要有两种:
- 服务端代理:需要独立部署一个代理服务,该代理服务后面管理多个数据库实例,在应用中通过一个数据源与该代理服务器建立连接,由该代理去操作底层数据库,并返回相应结果。优点是支持多语言,对业务透明,缺点是实现复杂,实现难度大,同时代理需要确保自身高可用
- 客户端代理:在连接池或数据库驱动上进行一层封装,内部与不同的数据库建立连接,并对
SQL进行必要的操作,比如读写分离选择走主库还是从库,分库分表select后如何聚合结果。优点是实现简单,天然去中心化,缺点是支持语言较少,版本升级困难
一些常见的数据库中间件如下:
Cobar:阿里开源的关系型数据库分布式服务中间件,已停更DRDS:脱胎于Cobar,全称分布式关系型数据库服务MyCat:开源数据库中间件,目前更新了MyCat2版本Atlas:Qihoo 360公司Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目,同时还有一个NoSQL的版本,叫Pikatddl:阿里巴巴自主研发的分布式数据库服务Sharding-JDBC:ShardingShpere的一个子产品,一个轻量级Java框架
2.2、Sharding-JDBC和MyCat区别
1)mycat是一个中间件的第三方应用,sharding-jdbc是一个jar包
2)使用mycat时不需要改代码,而使用sharding-jdbc时需要修改代码
Mycat(proxy中间件层):

Sharding-jdbc(TDDL为代表的应用层):
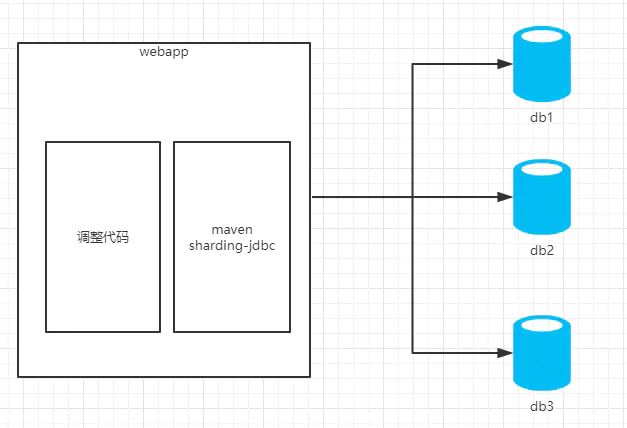
可以看出sharding-jdbc作为一个组件集成在应用内,而mycat则作为一个独立的应用需要单独部署。从架构上看sharding-jdbc更符合分布式架构的设计,直连数据库,没有中间应用,理论性能是最高的(实际性能需要结合具体的代码实现,理论性能可以理解为上限,通过不断优化代码实现,逐渐接近理论性能)。同时缺点也很明显,由于作为组件存在,需要集成在应用内,意味着作为使用方,必须要集成到代码里,使得开发成本相对较高;另一方面,由于需要集成在应用内,使得需要针对不同语言(java、C、PHP……)有不同的实现(事实上sharding-jdbc目前只支持Java),这样组件本身的维护成本也会很高。最终将应用场景限定在由Java开发的应用这一种场景下。
Sharding-JDBC较于MyCat,我认为最大的优势是:sharding-jdbc是轻量级的第三方工具,直连数据库,没有中间应用,我们只需要在项目中引用指定的jar包即可,然后根据项目的业务需要配置分库分表或者读写分离的规则和方式。
三、Sharding-JDBC+MyBatisPlus实现读写分离
3.0、项目代码结构和建表SQL语句
(1) 项目代码结构

(2) 建表SQL语句
DROP TABLE IF EXISTS `user`; CREATE TABLE `user` ( `user_id` int(11) NOT NULL AUTO_INCREMENT, `account` varchar(45) NOT NULL, `nickname` varchar(18) NOT NULL, `password` varchar(45) NOT NULL, `headimage_url` varchar(45) DEFAULT NULL, `introduce` varchar(45) DEFAULT NULL, PRIMARY KEY (`user_id`), UNIQUE KEY `account_UNIQUE` (`account`), UNIQUE KEY `nickname_UNIQUE` (`nickname`) ) ENGINE=InnoDB AUTO_INCREMENT=66 DEFAULT CHARSET=utf8;
3.1、引入Maven依赖
<!--Sharding-JDBC实现读写分离-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>4.1.1</version>
</dependency>
<!-- mybatis-plus 依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.2</version>
</dependency>
<!-- mysql 依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<!--支持Web开发,包括Tomcat和spring-webmvc-->
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--LomBok使用@Data注解-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.4</version>
<scope>provided</scope>
</dependency>
3.2、yml文件配置
Spring Boot 2.x中,对数据源的选择也紧跟潮流,默认采用了目前性能最佳的HikariCP
spring:
shardingsphere:
datasource:
names: master,slave # 数据源名字
master:
type: com.zaxxer.hikari.HikariDataSource # 连接池
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://xxxxxx:3306/test?allowMultiQueries=true&useSSL=false&useUnicode=true&characterEncoding=utf-8 #主库地址
username: root
password: xxxxxx
hikari:
maximum-pool-size: 20 #最大连接数量
minimum-idle: 10 #最小空闲连接数
max-lifetime: 0 #最大生命周期,0不过期。不等于0且小于30秒,会被重置为默认值30分钟.设置应该比mysql设置的超时时间短
idle-timeout: 30000 #空闲连接超时时长,默认值600000(10分钟)
connection-timeout: 60000 #连接超时时长
data-source-properties:
prepStmtCacheSize: 250
prepStmtCacheSqlLimit: 2048
cachePrepStmts: true
useServerPrepStmts: true
slave:
type: com.zaxxer.hikari.HikariDataSource # 连接池
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: jdbc:mysql://xxxxxx:3306/test?allowMultiQueries=true&useSSL=false&useUnicode=true&characterEncoding=utf-8 #从库地址
username: root
password: xxxxxx
hikari:
maximum-pool-size: 20
minimum-idle: 10
max-lifetime: 0
idle-timeout: 30000
connection-timeout: 60000
data-source-properties:
prepStmtCacheSize: 250
prepStmtCacheSqlLimit: 2048
cachePrepStmts: true
useServerPrepStmts: true
masterslave:
load-balance-algorithm-type: round_robin # 负载均衡算法,用于配置从库负载均衡算法类型,可选值:ROUND_ROBIN(轮询),RANDOM(随机)
name: ms # 最终的数据源名称
master-data-source-name: master # 主库数据源名称
slave-data-source-names: slave # 从库数据源名称列表,多个逗号分隔
props:
sql:
show: true # 在执行SQL时,会打印SQL,并显示执行库的名称,默认false
3.3、UserEntity实体类
package com.hs.sharingjdbc.entity;
import com.baomidou.mybatisplus.annotation.IdType;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
@Data
//定义表名:当数据库名与实体类名不一致或不符合驼峰命名时,需要在此注解指定表名
@TableName(value = "user")
public class UserEntity {
//指定主键自增策略:value与数据库主键列名一致,若实体类属性名与表主键列名一致可省略value
@TableId(type = IdType.AUTO)
private Integer user_id;
private String account;
private String nickname;
private String password;
private String headimage_url;
private String introduce;
}
3.4、UserMapper接口
编写的接口需要继承 BaseMapper接口,该接口源码定义了一些通用的操作数据库方法, 单表大部分 CRUD 操作都能直接搞定,相比原生的MyBatis,效率提高了很多
package com.hs.sharingjdbc.mapper;
import com.baomidou.mybatisplus.core.mapper.BaseMapper;
import com.hs.sharingjdbc.entity.UserEntity;
public interface UserMapper extends BaseMapper<UserEntity> {
// int insert(T entity);
//
// int deleteById(Serializable id);
//
// int deleteByMap(@Param("cm") Map<String, Object> columnMap);
//
// int delete(@Param("ew") Wrapper<T> queryWrapper);
//
// int deleteBatchIds(@Param("coll") Collection<? extends Serializable> idList);
//
// int updateById(@Param("et") T entity);
//
// int update(@Param("et") T entity, @Param("ew") Wrapper<T> updateWrapper);
//
// T selectById(Serializable id);
//
// List<T> selectBatchIds(@Param("coll") Collection<? extends Serializable> idList);
//
// List<T> selectByMap(@Param("cm") Map<String, Object> columnMap);
//
// T selectOne(@Param("ew") Wrapper<T> queryWrapper);
//
// Integer selectCount(@Param("ew") Wrapper<T> queryWrapper);
//
// List<T> selectList(@Param("ew") Wrapper<T> queryWrapper);
//
// List<Map<String, Object>> selectMaps(@Param("ew") Wrapper<T> queryWrapper);
//
// List<Object> selectObjs(@Param("ew") Wrapper<T> queryWrapper);
//
// <E extends IPage<T>> E selectPage(E page, @Param("ew") Wrapper<T> queryWrapper);
//
// <E extends IPage<Map<String, Object>>> E selectMapsPage(E page, @Param("ew") Wrapper<T> queryWrapper);
}
主类添加@MapperScan("com.hs.sharingjdbc.mapper"),扫描所有Mapper接口
package com.hs.sharingjdbc;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication()
@MapperScan("com.hs.sharingjdbc.mapper")
public class SharingJdbcApplication {
public static void main(String[] args) {
SpringApplication.run(SharingJdbcApplication.class, args);
}
}
3.5、UserService类
package com.hs.sharingjdbc.service;
import com.hs.sharingjdbc.entity.UserEntity;
import com.hs.sharingjdbc.mapper.UserMapper;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;
import java.util.List;
@Service
public class UserService {
@Autowired
UserMapper userMapper;
public List<UserEntity> findAll()
{
//selectList() 方法的参数为 mybatis-plus 内置的条件封装器 Wrapper,这里不填写表示无任何条件,全量查询
List<UserEntity> userEntities = userMapper.selectList(null);
return userEntities;
}
public int insertUser(UserEntity user)
{
int i = userMapper.insert(user);
return i;
}
}
3.6、UserController类
package com.hs.sharingjdbc.controller;
import com.hs.sharingjdbc.entity.UserEntity;
import com.hs.sharingjdbc.service.UserService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
public class UserController
{
@Autowired
UserService userService;
@RequestMapping("/listUser")
public List<UserEntity> listUser()
{
List<UserEntity> users = userService.findAll();
return users;
}
@RequestMapping("/insertUser")
public void insertUser()
{
UserEntity userEntity = new UserEntity();
userEntity.setAccount("22222");
userEntity.setNickname("hshshs");
userEntity.setPassword("123");
userService.insertUser(userEntity);
}
}
3.7、项目启动测试
http://localhost:8080/listUser ,执行查询语句,可以看到读操作在Slave从库进行:

http://localhost:8090/insertUser,执行插入语句,可以看到写操作在Master主库进行:

这样读写分离就算是可以了。
四、HikariCP连接池使用遇到的两个Bug
4.1、SpringBoot2关于HikariPool-1 - Failed to validate connection com.mysql.cj.jdbc.ConnectionImp
上面在使用springboot2.x 时遇到了一个很奇怪的问题,在程序运行起来之后,长时间的不进行数据库操作就会出现这样的错误,后面跟着这样的叙述, Connection is not available, request timed out after XXXms. Possibly consider using a shorter maxLifetime value.
为什么会存在不可用的连接呢?maxLifetime可以控制连接的生命周期,我们来以前看看maxLifetime参数。

我引一下chrome上面的中文翻译:
此属性控制数据库连接池中连接的最大生存期。使用中的连接永远不会停止,只有关闭连接后,连接才会被移除。在逐个连接的基础上,应用较小的负衰减以避免池中的质量消灭。 我们强烈建议设置此值,它应该比任何数据库或基础结构施加的连接时间限制短几秒钟。 值0表示没有最大寿命(无限寿命),当然要遵守该idleTimeout设置。 默认值:1800000(30分钟)
分析是HikariCP连接池对连接管理的问题,因此想方设法进行SpringBoot2.0 HikariCP连接池配置
hikari:
maximum-pool-size: 20 #最大连接数量
minimum-idle: 10 #最小空闲连接数
max-lifetime: 0 #最大生命周期,0不过期。不等于0且小于30秒,会被重置为默认值30分钟.设置应该比mysql设置的超时时间短
idle-timeout: 30000 #空闲连接超时时长,默认值600000(10分钟)
connection-timeout: 60000 #连接超时时长
data-source-properties:
prepStmtCacheSize: 250
prepStmtCacheSqlLimit: 2048
cachePrepStmts: true
useServerPrepStmts: true
spring.datasource.hikari.minimum-idle: 最小空闲连接,默认值10,小于0或大于maximum-pool-size,都会重置为maximum-pool-sizespring.datasource.hikari.maximum-pool-size: 最大连接数,小于等于0会被重置为默认值10;大于零小于1会被重置为minimum-idle的值spring.datasource.hikari.idle-timeout: 空闲连接超时时间,默认值600000(10分钟),大于等于max-lifetime且max-lifetime>0,会被重置为0;不等于0且小于10秒,会被重置为10秒。spring.datasource.hikari.max-lifetime: 连接最大存活时间,不等于0且小于30秒,会被重置为默认值30分钟.设置应该比mysql设置的超时时间短spring.datasource.hikari.connection-timeout: 连接超时时间:毫秒,小于250毫秒,否则被重置为默认值30秒
4.2、com.zaxxer.hikari.pool.HikariPool : datasource -Thread starvation or clock leap detected (housekeeper delta=4m32s295ms949µs223ns).
分析:WARN警告级别,看起来不是什么错误,但是连接数据库就是连不上
英译汉:数据源-检测到线程饥饿或时钟跳动
人话:要么是检测到等待连接的时间过长,造成进饥饿;要么是检测到时钟跳动,反正最后是关闭了数据库连接。
其实,这里根本就没有报错,只是一个警告。是上游代码出了问题,长时间不调用Service层进行存储,然后Hikari数据源就关掉了自己;当有新的调用时,会启用新的数据源。
修改默认的连接池配置如下:
datasource:
type: com.zaxxer.hikari.HikariDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://${ip}:3306/${数据库}?useSSL=false&characterEncoding=UTF-8
username: ${username}
password: ${password}
hikari:
auto-commit: true
#空闲连接超时时长
idle-timeout: 60000
#连接超时时长
connection-timeout: 60000
#最大生命周期,0不过期
max-lifetime: 0
#最小空闲连接数
minimum-idle: 10
#最大连接数量
maximum-pool-size: 20
五、读写分离架构,经常出现的读延迟的问题如何解决?
刚插入一条数据,然后马上就要去读取,这个时候有可能会读取不到?归根到底是因为主节点写入完之后数据是要复制给从节点的,读不到的原因是复制的时间比较长,也就是说数据还没复制到从节点,你就已经去从节点读取了,肯定读不到。mysql5.7 的主从复制是多线程了,意味着速度会变快,但是不一定能保证百分百马上读取到,这个问题我们可以有两种方式解决:
(1)业务层面妥协,是否操作完之后马上要进行读取
(2)对于操作完马上要读出来的,且业务上不能妥协的,我们可以对于这类的读取直接走主库
当然Sharding-JDBC也是考虑到这个问题的存在,所以给我们提供了一个功能,可以让用户在使 用的时候指定要不要走主库进行读取。在读取前使用下面的方式进行设置就可以了:
public List<UserInfo> findAllUser()
{
// 强制路由主库
HintManager.getInstance().setMasterRouteOnly();
return this.list();
}
参考链接:
Spring Boot demo系列(十二):ShardingSphere + MyBatisPlus读写分离 + 主从复制
mycat和sharding-jdbc哪个比较好?各有什么优缺点?
Spring Boot 2.x基础教程:默认数据源Hikari的配置详解
解决springboot2.x遇到的一段时间内不使用,redis连接和HikariPool连接池超时的问题
Thread starvation or clock leap detected (housekeeper delta=4m32s295ms949µs223ns).
到此这篇关于Sharding-JDBC自动实现MySQL读写分离的文章就介绍到这了,更多相关Sharding-JDBC MySQL读写分离内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

SpringBoot整合Sharding-JDBC实现MySQL8读写分离
目录 一.前言 二.项目目录结构 三.pom文件 四.配置文件(基于YAML)及SQL建表语句 五.Mapper.xml文件及Mapper接口 六 .Controller及Mocel文件 七.结果 八.Sharding-JDBC不同版本上的配置 一.前言 这是一个基于SpringBoot整合Sharding-JDBC实现读写分离的极简教程,笔者使用到的技术及版本如下: SpringBoot 2.5.2 MyBatis-Plus 3.4.3 Sharding-JDBC 4.1.1 MySQL8集群
-
Sharding-JDBC自动实现MySQL读写分离的示例代码
目录 一.ShardingSphere和Sharding-JDBC概述 1.1.ShardingSphere简介 1.2.Sharding-JDBC简介 1.3.Sharding-JDBC作用 1.4.ShardingSphere规划线路图 1.5.ShardingSphere三种产品的区别 二.数据库中间件 2.1.数据库中间件简介 2.2.Sharding-JDBC和MyCat区别 三.Sharding-JDBC+MyBatisPlus实现读写分离 3.0.项目代码结构和建表SQL语句 3.
-
SpringBoot+MyBatis+AOP实现读写分离的示例代码
目录 一. MySQL 读写分离 1.1.如何实现 MySQL 的读写分离? 1.2.MySQL 主从复制原理? 1.3.MySQL 主从同步延时问题(精华) 二.SpringBoot+AOP+MyBatis实现MySQL读写分离 2.1.AbstractRoutingDataSource 2.2.如何切换数据源 2.3.如何选择数据源 三 .代码实现 3.0.工程目录结构 3.1.引入Maven依赖 3.2.编写配置文件,配置主从数据源 3.3.Enum类,定义主库从库 3.4.ThreadL
-
Java基于JNDI 实现读写分离的示例代码
目录 一.JNDI数据源配置 二.JNDI数据源使用 三.web.xml配置 四.spring-servlet.xml配置 五.spring-db.xml配置 六.log4j.properties配置 七.相关路由数据源切换逻辑代码 八.搭建过程中遇到的问题和解决方案 一.JNDI数据源配置 在Tomcat的conf目录下,context.xml在其中标签中添加如下JNDI配置: <Resource name="dataSourceMaster" factory="or
-
PHP实现的mysql读写分离操作示例
本文实例讲述了PHP实现的mysql读写分离操作.分享给大家供大家参考,具体如下: 首先mysql主从需配置好,基本原理就是判断sql语句是否是select,是的话走master库,否则从slave查 <?php /** * mysql读写分离 */ class db{ public function __construct($sql){ $chestr = strtolower(trim($sql)); //判断sql语句有select关键字的话,就连接读的数据库,否则就连接写数据库 if(s
-
Thinkphp实现MySQL读写分离操作示例
相对于其他方法实现MySQL的读写分离来说,采用Thinkphp框架实现MySQL的读写分离简单易用,其配置文件示例代码如下: 'DB_TYPE'=> 'mysql', 'DB_DEPLOY_TYPE' => 1, //开打支持多服务器 'DB_RW_SEPARATE'=>true,//数据库读写否分离 'DB_HOST'=> '192.168.11.101,192.168.11.102', 'DB_NAME'=>'test', 'DB_USER'=>'admin',
-
java使用spring实现读写分离的示例代码
最近上线的项目中数据库数据已经临近饱和,最大的一张表数据已经接近3000W,百万数据的表也有几张,项目要求读数据(select)时间不能超过0.05秒,但实际情况已经不符合要求,explain建立索引,使用redis,ehcache缓存技术也已经满足不了要求,所以开始使用读写分离技术,可能以后数据量上亿或者更多的时候,需要再去考虑分布式数据库的部署,但目前来看,读写分离+缓存+索引+表分区+sql优化+负载均衡是可以满足亿级数据量的查询工作的,现在就一起来看一下亲测可用的使用spring实现读写
-
MySQL 读写分离实例详解
MySQL 读写分离 MySQL读写分离又一好办法 使用 com.mysql.jdbc.ReplicationDriver 在用过Amoeba 和 Cobar,还有dbware 等读写分离组件后,今天我的一个好朋友跟我讲,MySQL自身的也是可以读写分离的,因为他们提供了一个新的驱动,叫 com.mysql.jdbc.ReplicationDriver 说明文档:http://dev.mysql.com/doc/refman/5.1/en/connector-j-reference-replic
-
基于 SpringBoot 实现 MySQL 读写分离的问题
- 前言 - 首先思考一个问题: 在高并发的场景中,关于数据库都有哪些优化的手段? 常用的实现方法有以下几种:读写分离.加缓存.主从架构集群.分库分表等,在互联网应用中,大部分都是读多写少的场景,设置两个库,主库和读库. 主库的职能是负责写,从库主要是负责读 , 可以建立读库集群 , 通过读写职能在数据源上的隔离达到减少读写冲突. 释压数据库负载.保护数据库的目的.在实际的使用中,凡是涉及到写的部分直接切换到主库,读的部分直接切换到读库,这就是典型的读写分离技术.本文将聚焦读写分
-
SpringBoot+Mybatis-Plus实现mysql读写分离方案的示例代码
1. 引入mybatis-plus相关包,pom.xml文件 2. 配置文件application.property增加多库配置 mysql 数据源配置 spring.datasource.primary.jdbc-url=jdbc:mysql://xx.xx.xx.xx:3306/portal?useUnicode=true&useJDBCCompliantTimezoneShift=true&useLegacyDatetimeCode=false&serverTimezone=
-
SpringBoot项目中如何实现MySQL读写分离详解
目录 1.MySQL主从复制 1.1.介绍 二进制日志: MySQL复制过程分成三步: 1.2.主从库搭建 1.2.1.主库配置 1.2.2.从库配置 1.3.坑位介绍 1.3.1.UUID报错 1.3.2.server_id报错 1.3.3.同步异常解决 操作不规范,亲人两行泪…… 2.项目中实现 2.1.ShardingJDBC 2.2.依赖导入 2.3.配置文件 2.4.测试跑路 总结 1.MySQL主从复制 但我们仔细观察我们会发现,当我们的项目都是用的单体数据库时,那么就可能会存在如下