python人工智能TensorFlow自定义层及模型保存
目录
- 一、自定义层和网络
- 1.自定义层
- 2.自定义网络
- 二、模型的保存和加载
- 1.保存参数
- 2.保存整个模型
一、自定义层和网络
1.自定义层
①必须继承自layers.layer
②必须实现两个方法,__init__和call
这个层,实现的就是创建参数,以及一层的前向传播。
添加参数使用self.add_weight,直接调用即可,因为已经在母类中实现。
在call方法中,实现前向传播并返回结果即可。

2.自定义网络
①必须继承自keras.Model
②必须实现两个方法,__init__和call
这个网络,就可以使用我们定义好的MyDense层,来进行堆叠。
在init方法中设置好每一层的连接方式,以及维度。
在call方法中,就要实现前向传播,可以在这里对网络结构前向传播进行实现。如果在层中没有添加activation的话,在这里需要添加relu等激活函数。

二、模型的保存和加载
1.保存参数
通过save_weights方法可以保存参数,提供路径即可,加载的时候,先创建好和之前的网络结构一模一样的网络结构,导入参数即可。


2.保存整个模型
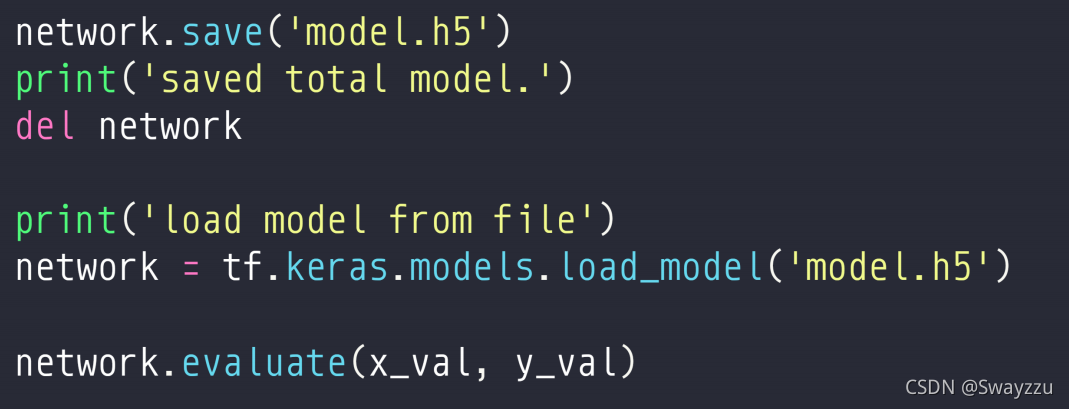
通过model.save(),保存整个模型,包括结构,层的名字,参数,维度等等所有信息。
恢复的时候不需要再创建网络。直接通过tf.keras.models.load_model读取即可。
以上就是python人工智能TensorFlow自定义层及模型保存的详细内容,更多关于TensorFlow自定义层及模型保存的资料请关注我们其它相关文章!
相关推荐
-
tensorflow之自定义神经网络层实例
如下所示: import tensorflow as tf tfe = tf.contrib.eager tf.enable_eager_execution() 大多数情况下,在为机器学习模型编写代码时,您希望在比单个操作和单个变量操作更高的抽象级别上操作. 1.关于图层的一些有用操作 许多机器学习模型可以表达为相对简单的图层的组合和堆叠,TensorFlow提供了一组许多常用图层,以及您从头开始或作为组合创建自己的应用程序特定图层的简单方法.TensorFlow在tf.keras包中包含完整的
-

一小时学会TensorFlow2之自定义层
目录 概述 Sequential Model & Layer 案例 数据集介绍 完整代码 概述 通过自定义网络, 我们可以自己创建网络并和现有的网络串联起来, 从而实现各种各样的网络结构. Sequential Sequential 是 Keras 的一个网络容器. 可以帮助我们将多层网络封装在一起. 通过 Sequential 我们可以把现有的层已经我们自己的层实现结合, 一次前向传播就可以实现数据从第一层到最后一层的计算. 格式: tf.keras.Sequential( layers=No
-
浅谈tensorflow模型保存为pb的各种姿势
一,直接保存pb 1, 首先我们当然可以直接在tensorflow训练中直接保存为pb为格式,保存pb的好处就是使用场景是实现创建模型与使用模型的解耦,使得创建模型与使用模型的解耦,使得前向推导inference代码统一.另外的好处就是保存为pb的时候,模型的变量会变成固定的,导致模型的大小会大大减小. 这里稍稍解释下pb:是MetaGraph的protocol buffer格式的文件,MetaGraph包括计算图,数据流,以及相关的变量和输入输出 主要使用tf.SavedModelBuilde
-
python深度学习TensorFlow神经网络模型的保存和读取
目录 之前的笔记里实现了softmax回归分类.简单的含有一个隐层的神经网络.卷积神经网络等等,但是这些代码在训练完成之后就直接退出了,并没有将训练得到的模型保存下来方便下次直接使用.为了让训练结果可以复用,需要将训练好的神经网络模型持久化,这就是这篇笔记里要写的东西. TensorFlow提供了一个非常简单的API,即tf.train.Saver类来保存和还原一个神经网络模型. 下面代码给出了保存TensorFlow模型的方法: import tensorflow as tf # 声明两个变量
-
tensorflow2.0保存和恢复模型3种方法
方法1:只保存模型的权重和偏置 这种方法不会保存整个网络的结构,只是保存模型的权重和偏置,所以在后期恢复模型之前,必须手动创建和之前模型一模一样的模型,以保证权重和偏置的维度和保存之前的相同. tf.keras.model类中的save_weights方法和load_weights方法,参数解释我就直接搬运官网的内容了. save_weights( filepath, overwrite=True, save_format=None ) Arguments: filepath: String,
-
python人工智能TensorFlow自定义层及模型保存
目录 一.自定义层和网络 1.自定义层 2.自定义网络 二.模型的保存和加载 1.保存参数 2.保存整个模型 一.自定义层和网络 1.自定义层 ①必须继承自layers.layer ②必须实现两个方法,__init__和call 这个层,实现的就是创建参数,以及一层的前向传播. 添加参数使用self.add_weight,直接调用即可,因为已经在母类中实现. 在call方法中,实现前向传播并返回结果即可. 2.自定义网络 ①必须继承自keras.Model ②必须实现两个方法,__init__和
-
tensorflow实现打印ckpt模型保存下的变量名称及变量值
有时候会需要通过从保存下来的ckpt文件来观察其保存下来的训练完成的变量值. ckpt文件名列表:(一般是三个文件) xxxxx.ckpt.data-00000-of-00001 xxxxx.ckpt.index xxxxx.ckpt.meta import os from tensorflow.python import pywrap_tensorflow checkpoint_path = os.path.join("文件夹路径", "xxxxx.ckpt")
-
python人工智能tensorflow构建循环神经网络RNN
目录 学习前言 RNN简介 tensorflow中RNN的相关函数 tf.nn.rnn_cell.BasicLSTMCell tf.nn.dynamic_rnn 全部代码 学习前言 在前一段时间已经完成了卷积神经网络的复习,现在要对循环神经网络的结构进行更深层次的明确. RNN简介 RNN 是当前发展非常火热的神经网络中的一种,它擅长对序列数据进行处理. 什么是序列数据呢?举个例子. 现在假设有四个字,“我” “去” “吃” “饭”.我们可以对它们进行任意的排列组合. “我去吃饭”,表示的就是我
-
python人工智能tensorflow常用激活函数Activation Functions
目录 常见的激活函数种类及其图像 1 sigmoid(logsig)函数 2 tanh函数 3 relu函数 4 softplus函数 tensorflow中损失函数的表达 1 sigmoid(logsig)函数 2 tanh函数 3 relu函数 4 softplus函数 激活函数在机器学习中常常用在神经网络隐含层节点与神经网络的输出层节点上,激活函数的作用是赋予神经网络更多的非线性因素,如果不用激励函数,输出都是输入的线性组合,这种情况与最原始的感知机相当,网络的逼近能力相当有限.如果能够引
-
python人工智能tensorflow函数tf.nn.dropout使用方法
目录 前言 tf.nn.dropout函数介绍 例子 代码 keep_prob = 0.5 keep_prob = 1 前言 神经网络在设置的神经网络足够复杂的情况下,可以无限逼近一段非线性连续函数,但是如果神经网络设置的足够复杂,将会导致过拟合(overfitting)的出现,就好像下图这样. 看到这个蓝色曲线,我就知道: 很明显蓝色曲线是overfitting的结果,尽管它很好的拟合了每一个点的位置,但是曲线是歪歪曲曲扭扭捏捏的,这个的曲线不具有良好的鲁棒性,在实际工程实验中,我们更希望得到
-
python人工智能tensorflow构建卷积神经网络CNN
目录 简介 隐含层介绍 1.卷积层 2.池化层 3.全连接层 具体实现代码 卷积层.池化层与全连接层实现代码 全部代码 学习神经网络已经有一段时间,从普通的BP神经网络到LSTM长短期记忆网络都有一定的了解,但是从未系统的把整个神经网络的结构记录下来,我相信这些小记录可以帮助我更加深刻的理解神经网络. 简介 卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),
-
python人工智能tensorflow函数tf.layers.dense使用方法
目录 参数数量及其作用 部分参数解释: 示例 参数数量及其作用 tf.layers.dense用于添加一个全连接层. 函数如下: tf.layers.dense( inputs, #层的输入 units, #该层的输出维度 activation=None, #激活函数 use_bias=True, kernel_initializer=None, # 卷积核的初始化器 bias_initializer=tf.zeros_initializer(), # 偏置项的初始化器 kernel_regul
-
python人工智能tensorflow函数tensorboard使用方法
目录 tensorboard相关函数及其常用参数设置 1 with tf.name_scope(layer_name): 2 tf.summary.histogram(layer_name+"/biases",biases) 3 tf.summary.scalar(“loss”,loss) 4 tf.summary.merge_all() 5 tf.summary.FileWriter(“logs/”,sess.graph) 6 write.add_summary(result,i)
-
python人工智能tensorflow函数tf.get_variable使用方法
目录 参数数量及其作用 例子 参数数量及其作用 该函数共有十一个参数,常用的有: 名称name 变量规格shape 变量类型dtype 变量初始化方式initializer 所属于的集合collections def get_variable(name, shape=None, dtype=None, initializer=None, regularizer=None, trainable=True, collections=None, caching_device=None, partiti
-
python人工智能tensorflow函数tf.get_collection使用方法
目录 参数数量及其作用 例子 参数数量及其作用 该函数共有两个参数,分别是key和scope. def get_collection(key, scope=None) Wrapper for Graph.get_collection() using the default graph. See tf.Graph.get_collection for more details. Args: key: The key for the collection. For example, the `Gra