详解python os.walk()方法的使用
python os.walk()方法
os.walk方法是python中帮助我们高效管理文件、目录的工具,在深度学习中数据整理应用的很频繁,如数据集的名称格式化、将数据集的按一定比例划分训练集train_set、测试集test_set。
1.导入文件(使用os.walk方法前需要导入以下包)
import os import random # 后续用来将数据随机打乱和生成确定随机种子,保证每次生成的随机数据一样便于测试模型精准度
2.os.walk()参数解释
os.walk(top, topdown=True, οnerrοr=None, followlinks=False)(后两个参数我几乎没用过)
参数
--top 我们需要遍历的文件夹的地址(最好使用绝对地址,相对地址有时会出现未知错误) --topdown 该参数为True时,会优先遍历top目录,否则优先遍历top的子目录(默认值为 True) --onerror 需要一个 callable 对象,当walk需要异常时会调用 --followlinks 如果为真,则会遍历目录下的快捷方式(linux 下是 symbolic link)实际所指的目录(默认关闭)
os.walk 的返回值是一个生成器(generator),也就是说我们可以用循环去不遍历它,来获得其内容。每次遍历的对象都是返回的是一个三元组(root,dirs,files)
--root 指的是当前正在遍历的这个文件夹的本身的地址 --dirs 返回的是一个列表list,表中数据是该文件夹中所有的目录的名称(但不包括子目录名称) --files 返回的也是一个列表list , 表中数据是该文件夹中所有的文件名称(但不包括子目录名称)
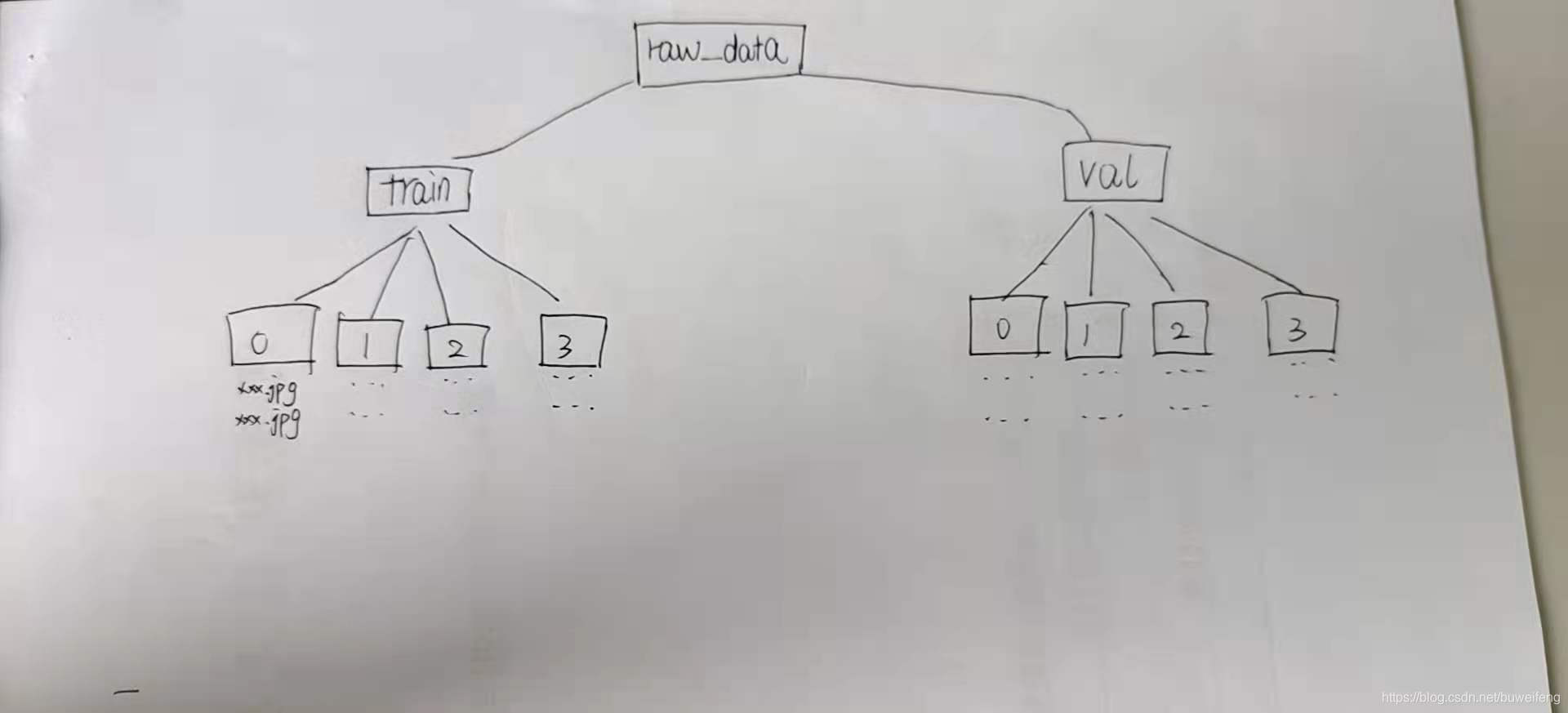
3.用于测试文件夹组织结构
 4.
4.
废话不说,看测试例子
4.1 os.walk(top, topdown=True)时打印返回的 root,dirs,files,顺便测试下topdown为真和假时的遍历顺序的区别。(这里就不展示运行后的结果了,代码拿走直接就可运行)
# topdown=True(该参数默认为真)
def _get_img_info():
#测试时将data_dir 换为自己的目标文件夹即可
data_dir = r'C:\Users\futiange\Desktop\Zero to Hero\expression_test\raw_data'
for root,dirs,files in os.walk(data_dir,topdown=True):
print('root={}'.format(root))
print('dirs={}'.format(dirs))
print('files={}'.format(files))
if __name__ == '__main__':
_get_img_info()
# topdown=False(该参数默认为假)
def _get_img_info():
data_dir = r'C:\Users\futiange\Desktop\Zero to Hero\expression_test\raw_data'
for root,dirs,files in os.walk(data_dir,topdown=False):
print('root={}'.format(root))
print('dirs={}'.format(dirs))
print('files={}'.format(files))
if __name__ == '__main__':
_get_img_info()
4.2 使用案例
在深度学习中遍历数据集时,我们可以对数据集划分,这里按train :test = 9 : 1划分。
import os
import random # 后续用来将数据随机打乱和生成确定随机种子,保证每次生成的随机数据一样便于测试模型精准度
def _get_img_info(rng_seed,split_n,mode):
image_path_list = [] #用来存放图片的路径
label_path_list = [] #用来存放图片对应的标签
data_dir = r'C:\Users\futiange\Desktop\Zero to Hero\expression_test\raw_data'
for root,dirs,files in os.walk(data_dir):
for file in files:
path_file = os.path.join(root,file)
print(path_file)
if path_file.endswith(".jpg"): #判断该路径下文件是不是以.jpg结尾
#print(os.path.basename(root)) #输出图片路径
#print(os.path.basename(root)[0]) #输出该图片所在的文件夹的第一个字符,我这里文件夹的第一个字符就是图片的标签,测试时可以根据自己的文件夹名称更改
#print(int(os.path.basename(root)[0]))
image_path_list.append(path_file) #将图片路径加入列表
label_path_list.append(os.path.basename(root)[0]) #根据文件夹名称确定标签,并加入列表
data_info = [[n,l] for n,l in zip(image_path_list,label_path_list)] #将图片路径-标签 关联起来
random.seed(rng_seed) # 该方法中传入参数,确保每次生成的种子都是一样的
random.shuffle(data_info) #上一行代码生成的种子是确定的,保证了每次将列表元素打乱后的结果一样,便于测试模型性能
split_idx = int(len(data_info) * split_n) # data_len * 0.9 # split_n代表数据集划分的比例
if mode == 'train':
img_set = data_info[:split_idx]
elif mode == 'val':
img_set = data_info[split_idx:]
else:
raise Exception("mode 无法识别,仅支持(train,valid)")
return img_set #返回随机打乱后的数据集,后续在对其进行格式化即可将数据集加载进模型测试
if __name__ == '__main__':
_get_img_info(1,0.9,'train')
到此这篇关于详解python os.walk()方法的使用的文章就介绍到这了,更多相关python os.walk()方法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python使用os.listdir()和os.walk()获取文件路径与文件下所有目录的方法
在python3.6版本中去掉了os.path.walk()函数 os.walk() 函数声明:walk(top,topdown=True,oneerror=None) 1.参数top表示需要遍历的目录树的路径 2.参数农户topdown默认是"True",表示首先返回根目录树下的文件,然后,再遍历目录树的子目录.topdown的值为"False",则表示先遍历目录树的子目录,返回子目录下的文件,最后返回根目录下的文件 3.参数oneerror的默认值是"
-
Python requests.post方法中data与json参数区别详解
在通过requests.post()进行POST请求时,传入报文的参数有两个,一个是data,一个是json. data与json既可以是str类型,也可以是dict类型. 区别: 1.不管json是str还是dict,如果不指定headers中的content-type,默认为application/json 2.data为dict时,如果不指定content-type,默认为application/x-www-form-urlencoded,相当于普通form表单提交的形式 3.data为s
-
python 获取文件下所有文件或目录os.walk()的实例
在python3.6版本中去掉了os.path.walk()函数 os.walk() 函数声明:walk(top,topdown=True,oneerror=None) 1.参数top表示需要遍历的目录树的路径 2.参数农户topdown默认是"True",表示首先返回根目录树下的文件,然后,再遍历目录树的子目录.topdown的值为"False",则表示先遍历目录树的子目录,返回子目录下的文件,最后返回根目录下的文件 3.参数oneerror的默认值是"
-
使用Python自动化Microsoft Excel和Word的操作方法
将Excel与Word集成,无缝生成自动报告 毫无疑问,微软的Excel和Word是公司和非公司领域使用最广泛的两款软件.它们实际上是"工作"的同义词.通常情况下,每一周我们都会将两者结合起来,并以某种方式发挥它们的优点.虽然一般的日常用途不会要求自动化,但有时自动化可能是必需的.也就是说,当您有大量的图表.图形.表格和报告要生成时,如果您选择手动方式,它可能会成为一项极其繁琐的工作.其实没必要这样.实际上,有一种方法可以在Python中创建一个管道,您可以将两者无缝集成,在Excel
-
详解python os.walk()方法的使用
python os.walk()方法 os.walk方法是python中帮助我们高效管理文件.目录的工具,在深度学习中数据整理应用的很频繁,如数据集的名称格式化.将数据集的按一定比例划分训练集train_set.测试集test_set. 1.导入文件(使用os.walk方法前需要导入以下包) import os import random # 后续用来将数据随机打乱和生成确定随机种子,保证每次生成的随机数据一样便于测试模型精准度 2.os.walk()参数解释 os.walk(top, topd
-
详解python os.path.exists判断文件或文件夹是否存在
os即operating system(操作系统),Python 的 os 模块封装了常见的文件和目录操作. os.path模块主要用于文件的属性获取,exists是"存在"的意思,所以顾名思义,os.path.exists()就是判断括号里的文件是否存在的意思,括号内的可以是文件路径. 举个栗子: import os #判断文件夹是否存在 dir = os.path.exists('C:\\Users\\Desktop') print('dir:', dir) #判断文件是否存在 f
-
详解Python中__new__方法的作用
目录 前言 一.__new__方法简介 1.初始化数据加载+解析类实例 2.初始化数据加载重写new方法+解析类实例 二.单例模式 1.用new方法如何实现单例模式 2.如何控制类仅执行一次初始化方法 三.多例模式 总结 前言 Python中类的构造方法__new__方法有何作用? Python类中有些方法名.属性名的前后都添加__双下画线,这种方法.属性通常属于Python的特殊方法和特殊属性.通过重写这些方法或直接调用这些方法来实现特殊功能.今天来聊聊构造方法__new__实际程序的应用场景
-
详解python中init方法和随机数方法
1.__init__方法的使用 2.random方法的使用 在python中,有一些方法是特殊的,是以两个下划线开始,两个下划线结束,定义类,最常用的方法就是__init__()方法,这是类的初始化方法,类似于C#或Java的构造函数.在创建对象的时候自动执行. class Person(object): ''' 这里定义的属性 为 静态的 ''' empCount = 0 # 创建对象的时候自动执行 def __init__(self, name): print('初始化方法.....') s
-
详解Python中time()方法的使用的教程
time()方法返回时间,在UTC时代以秒表示浮点数. 注意:尽管在时间总是返回作为一个浮点数,并不是所有的系统提供时间超过1秒精度.虽然这个函数正常返回非递减的值,就可以在系统时钟已经回来了两次调用期间返回比以前调用一个较低的值. 语法 以下是time()方法的语法: 参数 NA 返回值 此方法返回的时间,因为时代以秒表示浮点数(在UTC). 例子 下面的例子显示time()方法的使用. #!/usr/bin/python import time print "time.time(): %f
-
详解Python中expandtabs()方法的使用
expandtabs()方法返回制表符,即该字符串的一个副本. '\t'已经使用的空间,可选择使用给定的tabsize(默认8)扩展. 语法 以下是expandtabs()方法的语法: str.expandtabs(tabsize=8) 参数 tabsize -- 此选项指定要替换为制表符"\t' 的字符数. 返回值 此方法返回在制表符,即通过空格进行了扩展字符串,'\t'的副本. 例子 下面的例子显示expandtabs()方法的使用. #!/usr/bin/python str = &quo
-
详解Python中DOM方法的动态性
文档对象模型 xml.dom 模块对于 Python 程序员来说,可能是使用 XML 文档时功能最强大的工具.不幸的是,XML-SIG 提供的文档目前来说还比较少.W3C 语言无关的 DOM 规范填补了这方面的部分空白.但 Python 程序员最好有一个特定于 Python 语言的 DOM 的快速入门指南.本文旨在提供这样一个指南.在 上一篇专栏文章 中,某些样本中使用了样本 quotations.dtd 文件,并且这些文件可以与本文中的代码样本档案文件一起使用. 有必要了解 DOM 的确切含义
-
详解详解Python中writelines()方法的使用
writelines()方法写入字符串序列到文件.该序列可以是任何可迭代的对象产生字符串,字符串为一般列表.没有返回值. 语法 以下是writelines()方法的语法: fileObject.writelines( sequence ) 参数 sequence -- 这是字符串的序列. 返回值 此方法不返回任何值. 例子 下面的例子显示writelines()方法的使用. #!/usr/bin/python' # Open a file in witre mode fo = open("foo
-
详解Python中find()方法的使用
find()方法判断字符串str,如果起始索引beg和结束end索引能找到在字符串或字符串的一个子串中. 语法 以下是find()方法的语法: str.find(str, beg=0 end=len(string)) 参数 str -- 此选项指定要搜索的字符串. beg -- 这是开始索引,默认情况下为 0. end -- 这是结束索引,默认情况下它等于字符串的长度. 返回值 如果找到此方法返回的索引,否则返回-1. 例子 下面的例子显示了find()方法的使用. #!/usr/bin/pyt
-
详解Python常用标准库之os模块与shutil模块
目录 系统模块 常用方法 常用属性 文件操作 路径模块 文件复制移动模块(文件操作) copyfileobj -- 复制文件(内容) copyfile -- 复制文件(内容) copymode -- 复制文件(权限) copystat -- 复制文件(除了内容) copy & copy2 -- 复制文件 copytree -- 迭代复制文件夹中的所有 rmtree -- 迭代删除文件夹(即使文件夹中有文件) move -- 移动文件或文件夹 系统模块 import os 系统模块用于对系统进行操