详解Java如何实现小顶堆和大顶堆
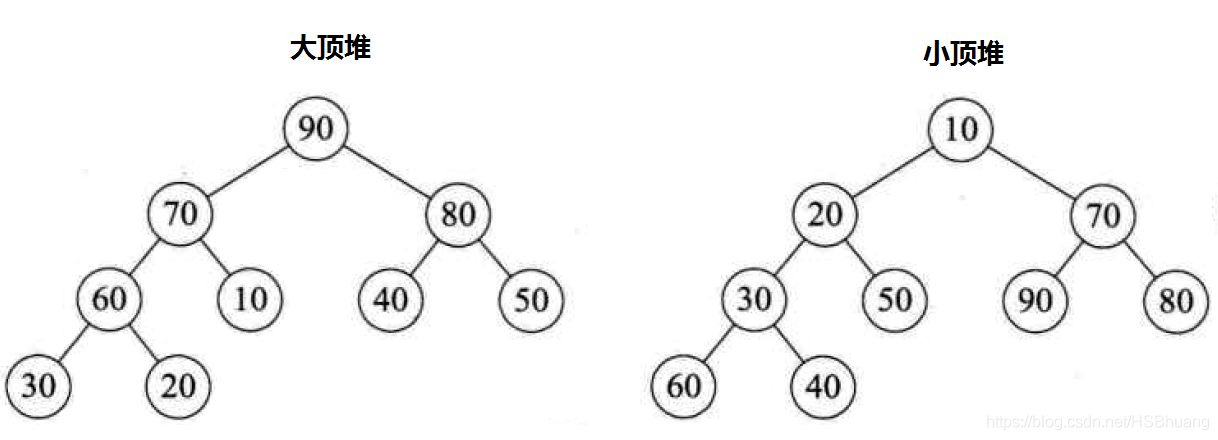
大顶堆
每个结点的值都大于或等于其左右孩子结点的值
小顶堆
每个结点的值都小于或等于其左右孩子结点的值
对比图
实现代码
public class HeapNode{
private int size;//堆大小
private int[] heap;//保存堆数组
//初始化堆
public HeapNode(int n) {
heap = new int[n];
size = 0;
}
//小顶堆建堆
public void minInsert(int key){
int i = this.size;
if (i==0) heap[0] = key;
else {
while (i>0 && heap[i/2]>key){
heap[i] = heap[i/2];
i = i/2;
}
heap[i] = key;
}
this.size++;
}
//大顶堆建堆
public void maxInsert(int key){
int i = this.size;
if (i==0) heap[0] = key;
else {
while (i>0 && heap[i/2]<key){
heap[i] = heap[i/2];
i = i/2;
}
heap[i] = key;
}
this.size++;
}
//小顶堆删除
public int minDelete(){
if (this.size==0) return -1;
int top = heap[0];
int last = heap[this.size-1];
heap[0] = last;
this.size--;
//堆化
minHeapify(0);
return top;
}
//大顶堆删除
public int maxDelete(){
if (this.size==0) return -1;
int top = heap[0];
int last = heap[this.size-1];
heap[0] = last;
this.size--;
//堆化
maxHeapify(0);
return top;
}
//小顶堆化
public void minHeapify(int i){
int L = 2*i,R=2*i+1,min;
if (L<=size && heap[L] < heap[i]) min = L;
else min = i;
if (R <= size && heap[R] < heap[min]) min = R;
if (min!=i){
int t = heap[min];
heap[min] = heap[i];
heap[i] = t;
minHeapify(min);
}
}
//大顶堆化
public void maxHeapify(int i){
int L = 2*i,R=2*i+1,max;
if (L<=size && heap[L] > heap[i]) max = L;
else max = i;
if (R <= size && heap[R] > heap[max]) max = R;
if (max!=i){
int t = heap[max];
heap[max] = heap[i];
heap[i] = t;
maxHeapify(max);
}
}
//输出堆
public void print(){
for (int i = 0; i < this.size; i++) {
System.out.print(heap[i]+" ");
}
System.out.println();
}
}
测试
public class Heap {
static int[] a = {5,3,6,4,2,1};
static int n = a.length;
public static void main(String[] args){
HeapNode heapNode = new HeapNode(n);
for (int i = 0; i < n; i++) {
heapNode.maxInsert(a[i]);
}
heapNode.print();
for (int i = 0; i < n; i++) {
int min = heapNode.maxDelete();
System.out.print("堆顶:"+min+" 剩下堆元素:");
heapNode.print();
}
}
}
结果

到此这篇关于详解Java如何实现小顶堆和大顶堆的文章就介绍到这了,更多相关Java实现小顶堆和大顶堆内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

java堆排序概念原理介绍
堆排序介绍: 堆排序可以分为两个阶段.在堆的构造阶段,我们将原始数组重新组织安排进一个堆中:然后在下沉排序阶段,我们从堆中按顺序取出所有元素并得到排序结果. 1.堆的构造,一个有效的方法是从右到左使用sink()下沉函数构造子堆.数组的每个位置都有一个子堆的根节点,sink()对于这些子堆也适用,如果一个节点的两个子节点都已经是堆了,那么在该节点上调用sink()方法可以把他们合并成一个堆.我们可以跳过大小为1的子堆,因为大小为1的不需要sink()也就是下沉操作,有关下沉和上浮操作可以参考我写
-
Java 堆排序实例(大顶堆、小顶堆)
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法.堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点. 堆排序的平均时间复杂度为Ο(nlogn) . 算法步骤: 1. 创建一个堆H[0..n-1] 2. 把堆首(最大值)和堆尾互换 3. 把堆的尺寸缩小1,并调用shift_down(0),目的是把新的数组顶端数据调整到相应位置 4. 重复步骤2,直到堆的尺寸为1 堆: 堆实际上是一棵完全二叉树,其任何一非叶节点满足性质:
-
JAVA堆排序算法的讲解
预备知识 堆排序 堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序.首先简单了解下堆结构. 堆 堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆:或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆.如下图: 同时,我们对堆中的结点按层进行编号,将这种逻辑结构映射到数组中就是下面这个样子 该数组从逻辑上讲就是一个堆结构,我们用简单的公式来描述一下堆的定义就是: 大顶
-
堆排序实例(Java数组实现)
堆排序:利用大根堆 数组全部入堆,再出堆从后向前插入回数组中,数组就从小到大有序了. public class MaxHeap<T extends Comparable<? super T>> { private T[] data; private int size; private int capacity; public MaxHeap(int capacity) { this.data = (T[]) new Comparable[capacity + 1]; size =
-
详解Java如何实现小顶堆和大顶堆
大顶堆 每个结点的值都大于或等于其左右孩子结点的值 小顶堆 每个结点的值都小于或等于其左右孩子结点的值 对比图 实现代码 public class HeapNode{ private int size;//堆大小 private int[] heap;//保存堆数组 //初始化堆 public HeapNode(int n) { heap = new int[n]; size = 0; } //小顶堆建堆 public void minInsert(int key){ int i = this.
-
详解Java的堆内存与栈内存的存储机制
堆与内存优化 今天测了一个项目的数据自动整理功能,对数据库中几万条记录及图片进行整理操作,运行接近到最后,爆出了java.lang.outOfMemoryError,java heap space方面的错误,以前写程序很少遇到这种内存上的错误,因为java有垃圾回收器机制,就一直没太关注.今天上网找了点资料,在此基础上做了个整理. 一.堆和栈 堆-用new建立,垃圾回收器负责回收 1.程序开始运行时,JVM从OS获取一些内存,部分是堆内存.堆内存通常在存储地址的底层,向上排列. 2.堆
-
Java实现二叉堆、大顶堆和小顶堆
目录 什么是二叉堆 什么是大顶堆.小顶堆 建堆 程序实现 建立大顶堆 逻辑过程 程序实现 建立小顶堆 逻辑过程 程序实现 从堆顶取数据并重构大小顶堆 什么是二叉堆 二叉堆就是完全二叉树,或者是靠近完全二叉树结构的二叉树.在二叉树建树时采取前序建树就是建立的完全二叉树.也就是二叉堆.所以二叉堆的建堆过程理论上讲和前序建树一样. 什么是大顶堆.小顶堆 二叉堆本质上是一棵近完全的二叉树,那么大顶堆和小顶堆必然也是满足这个结构要求的.在此之上,大顶堆要求对于一个节点来说,它的左右节点都比它小:小顶堆要求
-
详解Java 虚拟机垃圾收集机制
1 垃圾收集发生的区域 之前我们介绍过 Java 内存运行时区域的各个部分,其中程序计数器.虚拟机栈.本地方法栈三个区域随线程共存亡.栈中的每一个栈帧分配多少内存基本上在类结构确定下来时就已知,因此这几个区域的内存分配和回收都具有确定性,不需要考虑如何回收的问题,当方法结束或线程结束,内存自然也跟着回收了 而 Java 堆和方法区这两个区域则有显著的不确定性,只有在程序运行时我们才能知道程序究竟创建了哪些对象,创建了多少对象,所以这部分内存的分配和回收是动态的,垃圾收集器所关注的正是这部分内存该
-
详解JAVA中priorityqueue的具体使用
Java中PriorityQueue通过二叉小顶堆实现,可以用一棵完全二叉树表示.本文从Queue接口函数出发,结合生动的图解,深入浅出地分析PriorityQueue每个操作的具体过程和时间复杂度,将让读者建立对PriorityQueue建立清晰而深入的认识. 总体介绍 前面以JavaArrayDeque为例讲解了Stack和Queue,其实还有一种特殊的队列叫做PriorityQueue,即优先队列.优先队列的作用是能保证每次取出的元素都是队列中权值最小的(Java的优先队列每次取最小元素,
-
例题详解Java dfs与记忆化搜索和分治递归算法的使用
目录 一.dfs(深度优先搜索) 1.图的dfs 2.树的dfs 二.记忆化搜索 1.普通递归:O(2^n) 2.记忆化搜索: O(n) 三.分治 四.算法题 1.dia和威严 示例 2.小红点点点 示例1 3.kotori和素因子 示例1 示例2 4.kotori和糖果 示例 一.dfs(深度优先搜索) 1.图的dfs /** * 深度优先搜索 * * @param node * @param set */ public void DFS(Node node, Set<Node> set)
-
详解Java中Dijkstra(迪杰斯特拉)算法的图解与实现
目录 简介 工作过程 总体思路 实现 小根堆 Dijsktra 测试 简介 Dijkstra(迪杰斯特拉)算法是典型的单源最短路径算法,用于计算一个节点到其他所有节点的最短路径.主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止.Dijkstra算法是很有代表性的最短路径算法,在很多专业课程中都作为基本内容有详细的介绍,如数据结构,图论,运筹学等等.注意该算法要求图中不存在负权边.对应问题:在无向图G=(V,E)中,假设每条边E(i)的长度W(i),求由顶点V0到各节点的最短路径. 工作过
-
详解Java虚拟机管理的内存运行时数据区域
详解Java虚拟机管理的内存运行时数据区域 概述 Java虚拟机在执行Java程序的过程中会把它所管理的内存划分为若干个不同数据区域.这些区域都有各自的用途,以及创建和销毁的时间,有的区域随着虚拟机进程的启动而存在,有些区域则是依赖用户线程的启动和结束而建立和销毁. 程序计数器 程序计数器是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器.在虚拟机的概念模型里,字节码解释器工作时就是通过改变这个计数器的值来选取下一条需要执行的字节码指令,分支,循环,跳转,异常处理,线程恢复等基
-
详解java面试题中的i++和++i
代码如下所示: public class TestPlusPlus{ public static void main(String[] args){ int k = addAfterReturn(10); System.out.println(k); //输出 10 int k1 = addbeforeReturn(10); System.out.println(k1); //输出11 } public static int addbeforeReturn(int i){ return ++i;
-
详解Java虚拟机(JVM)运行时
JVM(Java虚拟机)是一个抽象的计算模型.就如同一台真实的机器,它有自己的指令集和执行引擎,可以在运行时操控内存区域.目的是为构建在其上运行的应用程序提供一个运行环境.JVM可以解读指令代码并与底层进行交互:包括操作系统平台和执行指令并管理资源的硬件体系结构.本文主要介绍Java虚拟机(JVM)运行时详解. 我们知道的JVM内存区域有:堆和栈,这是一种泛的分法,也是按运行时区域的一种分法,堆是所有线程共享的一块区域,而栈是线程隔离的,每个线程互不共享. 线程不共享区域 每个线程的数据区域包括