Python自定义指标聚类实例代码
目录
- 前言
- 与KMeans++比较
- Yolo检测框聚类
- 总结
前言
最近在研究 Yolov2 论文的时候,发现作者在做先验框聚类使用的指标并非欧式距离,而是IOU。在找了很多资料之后,基本确定 Python 没有自定义指标聚类的函数,所以打算自己做一个
设训练集的 shape 是 [n_sample, n_feature],基本思路是:
- 簇中心初始化:第 1 个簇中心取样本的特征均值,shape = [n_feature, ];从第 2 个簇中心开始,用距离函数 (自定义) 计算每个样本到最近中心点的距离,归一化后作为选取下一个簇中心的概率 —— 迭代到选取到足够的簇中心为止
- 簇中心调整:训练多轮,每一轮以样本点到最近中心点的距离之和作为 loss,梯度下降法 + Adam 优化器逼近最优解,在 loss 浮动值小于阈值的次数达到一定值时停止训练
因为设计之初就打算使用自定义距离函数,所以求导是很大的难题。笔者不才,最终决定借助 PyTorch 自动求导的天然优势
先给出欧式距离的计算函数
def Eu_dist(data, center):
""" 以 欧氏距离 为聚类准则的距离计算函数
data: 形如 [n_sample, n_feature] 的 tensor
center: 形如 [n_cluster, n_feature] 的 tensor"""
data = data.unsqueeze(1)
center = center.unsqueeze(0)
dist = ((data - center) ** 2).sum(dim=2)
return dist
然后就是聚类器的代码:使用时只需关注 __init__、fit、classify 函数
import torch
import numpy as np
import matplotlib.pyplot as plt
Adam = torch.optim.Adam
def get_progress(current, target, bar_len=30):
""" current: 当前完成任务数
target: 任务总数
bar_len: 进度条长度
return: 进度条字符串"""
assert current <= target
percent = round(current / target * 100, 1)
unit = 100 / bar_len
solid = int(percent / unit)
hollow = bar_len - solid
return "■" * solid + "□" * hollow + f" {current}/{target}({percent}%)"
class Cluster:
""" 聚类器
n_cluster: 簇中心数
dist_fun: 距离计算函数
kwargs:
data: 形如 [n_sample, n_feather] 的 tensor
center: 形如 [n_cluster, n_feature] 的 tensor
return: 形如 [n_sample, n_cluster] 的 tensor
init: 初始簇中心
max_iter: 最大迭代轮数
lr: 中心点坐标学习率
stop_thresh: 停止训练的loss浮动阈值
cluster_centers_: 聚类中心
labels_: 聚类结果"""
def __init__(self, n_cluster, dist_fun, init=None, max_iter=300, lr=0.08, stop_thresh=1e-4):
self._n_cluster = n_cluster
self._dist_fun = dist_fun
self._max_iter = max_iter
self._lr = lr
self._stop_thresh = stop_thresh
# 初始化参数
self.cluster_centers_ = None if init is None else torch.FloatTensor(init)
self.labels_ = None
self._bar_len = 20
def fit(self, data):
""" data: 形如 [n_sample, n_feature] 的 tensor
return: loss浮动日志"""
if self.cluster_centers_ is None:
self._init_cluster(data, self._max_iter // 5)
log = self._train(data, self._max_iter, self._lr)
# 开始若干轮次的训练,得到loss浮动日志
return log
def classify(self, data, show=False):
""" data: 形如 [n_sample, n_feature] 的 tensor
show: 绘制分类结果
return: 分类标签"""
dist = self._dist_fun(data, self.cluster_centers_)
self.labels_ = dist.argmin(axis=1)
# 将标签加载到实例属性
if show:
for idx in range(self._n_cluster):
container = data[self.labels_ == idx]
plt.scatter(container[:, 0], container[:, 1], alpha=0.7)
plt.scatter(self.cluster_centers_[:, 0], self.cluster_centers_[:, 1], c="gold", marker="p", s=50)
plt.show()
return self.labels_
def _init_cluster(self, data, epochs):
self.cluster_centers_ = data.mean(dim=0).reshape(1, -1)
for idx in range(1, self._n_cluster):
dist = np.array(self._dist_fun(data, self.cluster_centers_).min(dim=1)[0])
new_cluster = data[np.random.choice(range(data.shape[0]), p=dist / dist.sum())].reshape(1, -1)
# 取新的中心点
self.cluster_centers_ = torch.cat([self.cluster_centers_, new_cluster], dim=0)
progress = get_progress(idx, self._n_cluster, bar_len=self._n_cluster if self._n_cluster <= self._bar_len else self._bar_len)
print(f"\rCluster Init: {progress}", end="")
self._train(data, epochs, self._lr * 2.5, init=True)
# 初始化簇中心时使用较大的lr
def _train(self, data, epochs, lr, init=False):
center = self.cluster_centers_.cuda()
center.requires_grad = True
data = data.cuda()
optimizer = Adam([center], lr=lr)
# 将中心数据加载到 GPU 上
init_patience = int(epochs ** 0.5)
patience = init_patience
update_log = []
min_loss = np.inf
for epoch in range(epochs):
# 对样本分类并更新中心点
sample_dist = self._dist_fun(data, center).min(dim=1)
self.labels_ = sample_dist[1]
loss = sum([sample_dist[0][self.labels_ == idx].mean() for idx in range(len(center))])
# loss 函数: 所有样本到中心点的最小距离和 - 中心点间的最小间隔
loss.backward()
optimizer.step()
optimizer.zero_grad()
# 反向传播梯度更新中心点
loss = loss.item()
progress = min_loss - loss
update_log.append(progress)
if progress > 0:
self.cluster_centers_ = center.cpu().detach()
min_loss = loss
# 脱离计算图后记录中心点
if progress < self._stop_thresh:
patience -= 1
# 耐心值减少
if patience < 0:
break
# 耐心值归零时退出
else:
patience = init_patience
# 恢复耐心值
progress = get_progress(init_patience - patience, init_patience, bar_len=self._bar_len)
if not init:
print(f"\rCluster: {progress}\titer: {epoch + 1}", end="")
if not init:
print("")
return torch.FloatTensor(update_log)
与KMeans++比较
KMeans++ 是以欧式距离为聚类准则的经典聚类算法。在 iris 数据集上,KMeans++ 远远快于我的聚类器。但在我反复对比测试的几轮里,我的聚类器精度也是不差的 —— 可以看到下图里的聚类结果完全一致
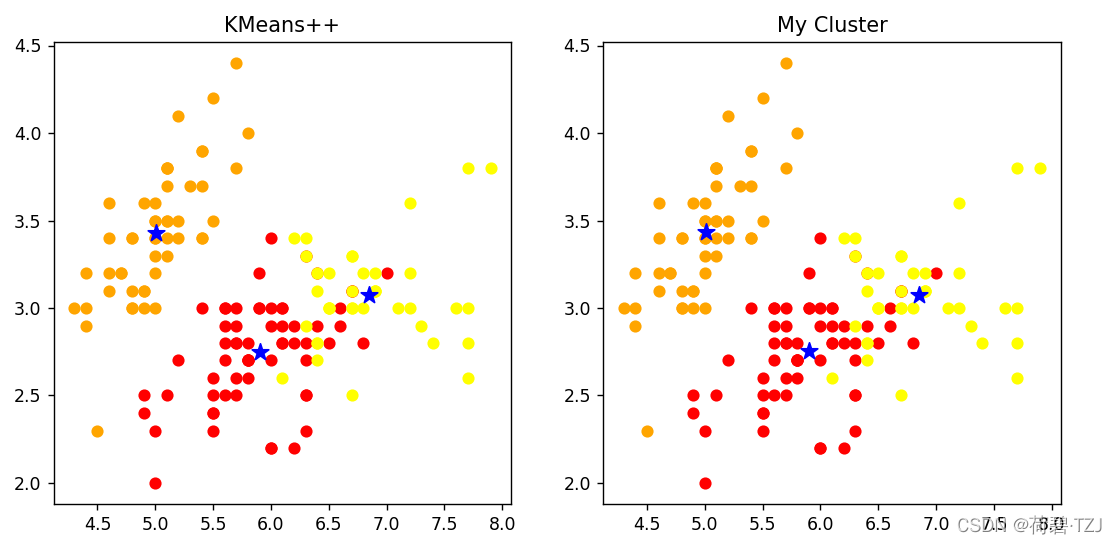
| KMeans++ | My Cluster | |
| Cost | 145 ms | 1597 ms |
| Center |
[[5.9016, 2.7484, 4.3935, 1.4339], [5.0060, 3.4280, 1.4620, 0.2460], |
[[5.9016, 2.7485, 4.3934, 1.4338], [5.0063, 3.4284, 1.4617, 0.2463], [6.8500, 3.0741, 5.7420, 2.0714]] |
虽然速度方面与老牌算法对比的确不行,但是我的这个聚类器最大的亮点还是自定义距离函数
Yolo 检测框聚类
本来想用 Yolov4 检测框聚类引入的 CIoU 做聚类,但是没法解决梯度弥散的问题,所以退其次用了 DIoU
def DIoU_dist(boxes, anchor):
""" 以 DIoU 为聚类准则的距离计算函数
boxes: 形如 [n_sample, 2] 的 tensor
anchor: 形如 [n_cluster, 2] 的 tensor"""
n_sample = boxes.shape[0]
n_cluster = anchor.shape[0]
dist = Eu_dist(boxes, anchor)
# 计算欧式距离
union_inter = torch.prod(boxes, dim=1).reshape(-1, 1) + torch.prod(anchor, dim=1).reshape(1, -1)
boxes = boxes.unsqueeze(1).repeat(1, n_cluster, 1)
anchor = anchor.unsqueeze(0).repeat(n_sample, 1, 1)
compare = torch.stack([boxes, anchor], dim=2)
# 组合检测框与 anchor 的信息
diag = torch.sum(compare.max(dim=2)[0] ** 2, dim=2)
dist /= diag
# 计算外接矩形的对角线长度
inter = torch.prod(compare.min(dim=2)[0], dim=2)
iou = inter / (union_inter - inter)
# 计算 IoU
dist += 1 - iou
return dist
我提取了 DroneVehicle 数据集的 650156 个预测框的尺寸做聚类,在这个过程中发现因为小尺寸的预测框过多,导致聚类中心聚集在原点附近。所以对 loss 函数做了改进:先分类,再计算每个分类下的最大距离之和
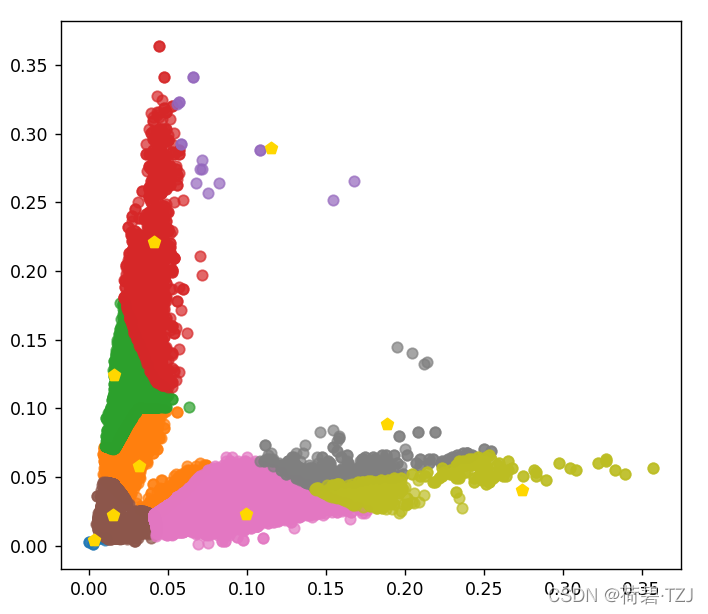
横轴表示检测框的宽度,纵轴表示检测框的高度,其数值都是相对于原图尺寸的比例。若原图尺寸为 608 * 608,则得到的 9 个先验框为:
| [ 2, 3 ] | [ 9, 13 ] | [ 19, 35 ] |
| [ 10, 76 ] | [ 60, 14 ] | [ 25, 134 ] |
| [ 167, 25 ] | [ 115, 54 ] | [ 70, 176 ] |
总结
到此这篇关于Python自定义指标聚类的文章就介绍到这了,更多相关Python自定义指标聚类内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现的KMeans聚类算法实例分析
本文实例讲述了Python实现的KMeans聚类算法.分享给大家供大家参考,具体如下: 菜鸟一枚,编程初学者,最近想使用Python3实现几个简单的机器学习分析方法,记录一下自己的学习过程. 关于KMeans算法本身就不做介绍了,下面记录一下自己遇到的问题. 一 .关于初始聚类中心的选取 初始聚类中心的选择一般有: (1)随机选取 (2)随机选取样本中一个点作为中心点,在通过这个点选取距离其较大的点作为第二个中心点,以此类推. (3)使用层次聚类等算法更新出初始聚类中心 我一开始是使用numpy
-
Python聚类算法之凝聚层次聚类实例分析
本文实例讲述了Python聚类算法之凝聚层次聚类.分享给大家供大家参考,具体如下: 凝聚层次聚类:所谓凝聚的,指的是该算法初始时,将每个点作为一个簇,每一步合并两个最接近的簇.另外即使到最后,对于噪音点或是离群点也往往还是各占一簇的,除非过度合并.对于这里的"最接近",有下面三种定义.我在实现是使用了MIN,该方法在合并时,只要依次取当前最近的点对,如果这个点对当前不在一个簇中,将所在的两个簇合并就行: 单链(MIN):定义簇的邻近度为不同两个簇的两个最近的点之间的距离. 全链(MAX
-
python中实现k-means聚类算法详解
算法优缺点: 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去. 1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好.另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚
-
Python实现简单层次聚类算法以及可视化
本文实例为大家分享了Python实现简单层次聚类算法,以及可视化,供大家参考,具体内容如下 基本的算法思路就是:把当前组间距离最小的两组合并成一组. 算法的差异在算法如何确定组件的距离,一般有最大距离,最小距离,平均距离,马氏距离等等. 代码如下: import numpy as np import data_helper np.random.seed(1) def get_raw_data(n): _data=np.random.rand(n,2) #生成数据的格式是n个(x,y) _grou
-
Python实现Kmeans聚类算法
本节内容:本节内容是根据上学期所上的模式识别课程的作业整理而来,第一道题目是Kmeans聚类算法,数据集是Iris(鸢尾花的数据集),分类数k是3,数据维数是4. 关于聚类 聚类算法是这样的一种算法:给定样本数据Sample,要求将样本Sample中相似的数据聚到一类.有了这个认识之后,就应该了解了聚类算法要干什么了吧.说白了,就是归类. 首先,我们需要考虑的是,如何衡量数据之间的相似程度?比如说,有一群说不同语言的人,我们一般是根据他们的方言来聚类的(当然,你也可以指定以身高来聚类).
-
Python自定义指标聚类实例代码
目录 前言 与KMeans++比较 Yolo检测框聚类 总结 前言 最近在研究 Yolov2 论文的时候,发现作者在做先验框聚类使用的指标并非欧式距离,而是IOU.在找了很多资料之后,基本确定 Python 没有自定义指标聚类的函数,所以打算自己做一个 设训练集的 shape 是 [n_sample, n_feature],基本思路是: 簇中心初始化:第 1 个簇中心取样本的特征均值,shape = [n_feature, ]:从第 2 个簇中心开始,用距离函数 (自定义) 计算每个样本到最近中
-
Django自定义manage命令实例代码
manage.py是在我们创建Django项目的时候就自动生成在根目录下的一个命令行工具,它可以执行一些简单的命令,其功能是将Django project放到sys.path目录中,同时设置DJANGO_SETTINGS_MODULE环境变量为当前project的setting.py文件. manage.py的代码是这样的: #!/usr/bin/env python import os import sys if __name__ == "__main__": os.environ.
-
微信公众号测试账号自定义菜单的实例代码
自定义菜单接口可实现多种类型按钮,如下: 1.click:点击推事件 用户点击click类型按钮后,微信服务器会通过消息接口推送消息类型为event 的结构给开发者(参考消息接口指南),并且带上按钮中开发者填写的key值,开发者可以通过自定义的key值与用户进行交互: 2.view:跳转URL 用户点击view类型按钮后,微信客户端将会打开开发者在按钮中填写的网页URL,可与网页授权获取用户基本信息接口结合,获得用户基本信息. 3.scancode_push:扫码推事件 用户点击按钮后,微信客户
-
Python ldap实现登录实例代码
下面一段代码是小编给大家介绍的Python ldap实现登录实例代码,一起看看吧 ldap_config = { 'ldap_path': 'ldap://xx.xx.xx.xx:389', 'base_dn': 'ou=users,dc=ledo,dc=com', 'ldap_user': 'uid=reporttest,ou=users,dc=ledo,dc=com', 'ldap_pass': '111111.0', 'original_pass': '111111.0' } ldap_m
-
python+matplotlib演示电偶极子实例代码
使用matplotlib.tri.CubicTriInterpolator.演示变化率计算: 完整实例: from matplotlib.tri import ( Triangulation, UniformTriRefiner, CubicTriInterpolator) import matplotlib.pyplot as plt import matplotlib.cm as cm import numpy as np #---------------------------------
-
python的re正则表达式实例代码
本文研究的主要是python的re正则表达式的相关内容,具体如下. 概念:正则表达式(通项公式)是用来简洁表达一组字符串的表达式.优势是简洁,一行胜千言. 应用:字符串匹配. 实例代码: CODEC = 'UTF-8' #encoding:utf-8 import re p=re.compile("ab") str = "abfffa" #match必须匹配首字母 if p.match(str): print p.match(str).group() #match必
-
Python编程求质数实例代码
本文研究的主要是Python编程求质数实例,选取了几个数进行了测试,具体如下. 定义:质数又称素数.一个大于1的自然数,除了1和它自身外,不能被其他自然数整除的数叫做质数:否则称为合数. 我们知道自然数(除了0和1以外)都可以写成几个质数相乘再乘以一的格式,所以我们可以用以个数去试一试看看它能否将小于它的质数整除. 首先我们创建一个空的list,然后我们知道2是最小的质数,于是我们把2添加进这个空白的list,之后我们开始循环,第一个数从3开始,用3除以小于3的质数,没有小于它的质数能被它整除,
-
python模块之paramiko实例代码
本文研究的主要是python模块之paramiko的相关用法,具体实现代码如下,一起来看看. paramiko模块提供了ssh及sft进行远程登录服务器执行命令和上传下载文件的功能.这是一个第三方的软件包,使用之前需要安装. 1 基于用户名和密码的 sshclient 方式登录 # 建立一个sshclient对象 ssh = paramiko.SSHClient() # 允许将信任的主机自动加入到host_allow 列表,此方法必须放在connect方法的前面 ssh.set_missing_
-
简单的python协同过滤程序实例代码
本文研究的主要是python协同过滤程序的相关内容,具体介绍如下. 关于协同过滤的一个最经典的例子就是看电影,有时候不知道哪一部电影是我们喜欢的或者评分比较高的,那么通常的做法就是问问周围的朋友,看看最近有什么好的电影推荐.在问的时候,都习惯于问跟自己口味差不多的朋友,这就是协同过滤的核心思想. 这个程序完全是为了应付大数据分析与计算的课程作业所写的一个小程序,先上程序,一共55行.不在意细节的话,55行的程序已经表现出了协同过滤的特性了.就是对每一个用户找4个最接近的用户,然后进行推荐,在选择
-
python实现Adapter模式实例代码
本文研究的主要是python实现Adapter模式的相关内容,具体实现代码如下. Adapter模式有两种实现方式一种是类方式. #理解 #就是电源适配器的原理吧,将本来不兼容的接口类能够工作 #这个是类实现方式 #例子 #假如一个插座类输出脚是3脚的,而台灯需要的是两脚插座,现在就需要一个Adapter实现适配插座 #Adaptee class socket(object): def Trigle(self): print 'power supply' #target class tableL