详解Python利用APScheduler框架实现定时任务
目录
- 背景
- 样例代码
- 代码详解
- 执行结果
- 知识点补充
背景
最近在做一些python工具的时候,常常会碰到定时器问题,总觉着使用threading.timer或者schedule模块非常不优雅。所以这里给自己做个记录,也分享一个定时任务框架APScheduler。具体的架构原理就不细说了,用个例子说明一下怎么简易的使用。
样例代码
先上样例代码,如下:
#!/user/bin/env python
# coding=utf-8
"""
@project : csdn
@author : 剑客阿良_ALiang
@file : apschedule_tool.py
@ide : PyCharm
@time : 2022-03-02 17:34:17
"""
from apscheduler.schedulers.background import BackgroundScheduler
from multiprocessing import Process, Queue
import time
import random
# 具体工作实现
def do_job(q: Queue):
while True:
if not q.empty():
_value = q.get(False)
print('{} poll -> {}'.format(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()), _value))
else:
break
def put_job(q: Queue):
while True:
_value = str(random.randint(1, 10))
q.put(_value)
print('{} put -> {}'.format(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()), _value))
time.sleep(1)
if __name__ == '__main__':
q = Queue()
scheduler = BackgroundScheduler()
# 每隔5秒运行一次
scheduler.add_job(do_job, trigger='cron', second='*/5', args=(q,))
scheduler.start()
Process(target=put_job, args=(q,)).start()
代码详解
1、调度器的选择主要取决于编程环境以及 APScheduler 的用途。主要有以下几种调度器:
apscheduler.schedulers.blocking.BlockingScheduler:当调度器是程序中唯一运行的东西时使用,阻塞式。
apscheduler.schedulers.background.BackgroundScheduler:当调度器需要后台运行时使用。
apscheduler.schedulers.asyncio.AsyncIOScheduler:当程序使用 asyncio 框架时使用。
apscheduler.schedulers.gevent.GeventScheduler:当程序使用 gevent 框架时使用。
apscheduler.schedulers.tornado.TornadoScheduler:当构建 Tornado 程序时使用
apscheduler.schedulers.twisted.TwistedScheduler:当构建 Twisted 程序时使用
apscheduler.schedulers.qt.QtScheduler:当构建 Qt 程序时使用
个人觉着BackgroundScheduler已经很够用了,在后台启动定时任务,也不会阻塞进程。
2、trigger后面跟随的类似linux系统下cron写法,样例代码中是每5秒执行一次。
3、这里加了一个多进程通讯的队列multiprocessing.Queue,主要是样例代码解决的场景是我实际工作中常碰到的,举个栗子:多个进程间通讯,其中一个进程需要定时获取另一个进程中的数据。可以参考样例代码。
执行结果
2022-03-02 19:31:27 put -> 4
2022-03-02 19:31:28 put -> 10
2022-03-02 19:31:29 put -> 1
2022-03-02 19:31:30 poll -> 4
2022-03-02 19:31:30 poll -> 10
2022-03-02 19:31:30 poll -> 1
2022-03-02 19:31:30 put -> 2
2022-03-02 19:31:31 put -> 1
2022-03-02 19:31:32 put -> 6
2022-03-02 19:31:33 put -> 4
2022-03-02 19:31:34 put -> 8
2022-03-02 19:31:35 poll -> 2
2022-03-02 19:31:35 poll -> 1
2022-03-02 19:31:35 poll -> 6
2022-03-02 19:31:35 poll -> 4
2022-03-02 19:31:35 poll -> 8
2022-03-02 19:31:35 put -> 8
2022-03-02 19:31:36 put -> 10
2022-03-02 19:31:37 put -> 7
2022-03-02 19:31:38 put -> 2
2022-03-02 19:31:39 put -> 3
2022-03-02 19:31:40 poll -> 8
2022-03-02 19:31:40 poll -> 10
2022-03-02 19:31:40 poll -> 7
2022-03-02 19:31:40 poll -> 2
2022-03-02 19:31:40 poll -> 3
2022-03-02 19:31:40 put -> 5Process finished with exit code -1
知识点补充
APScheduler(advanceded python scheduler)基于Quartz的一个Python定时任务框架,实现了Quartz的所有功能,使用起来十分方便。提供了基于日期、固定时间间隔以及crontab类型的任务,并且可以持久化任务。基于这些功能,我们可以很方便的实现一个Python定时任务系统。
它有以下三个特点:
- 类似于 Liunx Cron 的调度程序(可选的开始/结束时间)
- 基于时间间隔的执行调度(周期性调度,可选的开始/结束时间)
- 一次性执行任务(在设定的日期/时间运行一次任务)
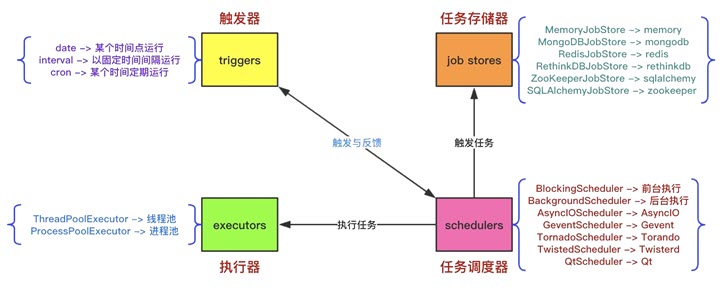
APScheduler有四种组成部分:
- 触发器(trigger) 包含调度逻辑,每一个作业有它自己的触发器,用于决定接下来哪一个作业会运行。除了他们自己初始配置意外,触发器完全是无状态的。
- 作业存储(job store) 存储被调度的作业,默认的作业存储是简单地把作业保存在内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据讲在保存在持久化作业存储时被序列化,并在加载时被反序列化。调度器不能分享同一个作业存储。
- 执行器(executor) 处理作业的运行,他们通常通过在作业中提交制定的可调用对象到一个线程或者进城池来进行。当作业完成时,执行器将会通知调度器。
- 调度器(scheduler) 是其他的组成部分。你通常在应用只有一个调度器,应用的开发者通常不会直接处理作业存储、调度器和触发器,相反,调度器提供了处理这些的合适的接口。配置作业存储和执行器可以在调度器中完成,例如添加、修改和移除作业。通过配置executor、jobstore、trigger,使用线程池(ThreadPoolExecutor默认值20)或进程池(ProcessPoolExecutor 默认值5)并且默认最多3个(max_instances)任务实例同时运行,实现对job的增删改查等调度控制
示例代码:
from apscheduler.schedulers.blocking import BlockingScheduler
from datetime import datetime
# 输出时间
def job():
print(datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
# BlockingScheduler
sched = BlockingScheduler()
sched.add_job(my_job, 'interval', seconds=5, id='my_job_id')
sched.start()
到此这篇关于详解Python利用APScheduler框架实现定时任务的文章就介绍到这了,更多相关Python定时任务内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python定时任务APScheduler的实例实例详解
APScheduler 支持三种调度任务:固定时间间隔,固定时间点(日期),Linux 下的 Crontab 命令.同时,它还支持异步执行.后台执行调度任务. 一.基本架构 触发器 triggers:设定触发任务的条件 描述一个任务何时被触发,按日期或按时间间隔或按 cronjob 表达式三种方式触发 任务存储器 job stores:存放任务,可以放内存(默认)或数据库 注:调度器之间不能共享任务存储器 执行器 executors:用于执行任务,可设定执行模式 将指定的作业提交到线程池或者进程
-
python定时任务apscheduler的详细使用教程
目录 前言 安装 主要组成部分 简单应用 完整代码 总结 前言 我们项目中总是避免不了要使用一些定时任务,比如说最近的项目,用户点击报名考试以后需要在考试日期临近的时候推送小程序消息提醒到客户微信上,翻了翻 fastapi 中的实现,虽然方法和包也不少,但是要不就是太重了(比如需要再开服务,还要依赖 redis,都不好用),虽然也可以使用 time 模块的 time.sleep()机上 fastapi 的后台任务变相实现,但是相对简单的功能还行,复杂点的代码起来就麻烦了,所以还是专人专事找个负责
-
Python定时任务框架APScheduler原理及常用代码
APScheduler简介 在平常的工作中几乎有一半的功能模块都需要定时任务来推动,例如项目中有一个定时统计程序,定时爬出网站的URL程序,定时检测钓鱼网站的程序等等,都涉及到了关于定时任务的问题,第一时间想到的是利用time模块的time.sleep()方法使程序休眠来达到定时任务的目的,虽然这样也可以,但是总觉得不是那么的专业,^_^所以就找到了python的定时任务模块APScheduler: APScheduler基于Quartz的一个Python定时任务框架,实现了Quartz的所有功
-

Python使用APScheduler实现定时任务过程解析
前言 APScheduler是基于Quartz的一个Python定时任务框架.提供了基于日期.固定时间间隔以及crontab类型的任务,并且可以持久化任务. 在线文档:https://apscheduler.readthedocs.io/en/latest/userguide.html 一.安装APScheduler pip install apscheduler 二.基本概念 APScheduler有四大组件: 1.触发器 triggers : 触发器包含调度逻辑.每个作业都有自己的触发器,用
-
Python定时任务工具之APScheduler使用方式
APScheduler (advanceded python scheduler)是一款Python开发的定时任务工具. 文档地址 apscheduler.readthedocs.io/en/latest/u- 特点: 不依赖于Linux系统的crontab系统定时,独立运行 可以 动态添加 新的定时任务,如下单后30分钟内必须支付,否则取消订单,就可以借助此工具(每下一单就要添加此订单的定时任务) 对添加的定时任务可以做持久保存 1 安装 pip install apscheduler 2 组
-
python 基于Apscheduler实现定时任务
导语 在工作场景遇到了这么一个场景,就是需要定期去执行一个缓存接口,用于同步设备配置.首先想到的就是Linux上的crontab,可以定期,或者间隔一段时间去执行任务.但是如果你想要把这个定时任务作为一个模块集成到Python项目中,或者想持久化任务,显然crontab不太适用.Python的APScheduler模块能够很好的解决此类问题,所以专门写这篇文章,从简单入门开始记录关于APScheduler最基础的使用场景,以及解决持久化任务的问题,最后结合其他框架深层次定制定时任务模块这几个点入
-
详解Python利用APScheduler框架实现定时任务
目录 背景 样例代码 代码详解 执行结果 知识点补充 背景 最近在做一些python工具的时候,常常会碰到定时器问题,总觉着使用threading.timer或者schedule模块非常不优雅.所以这里给自己做个记录,也分享一个定时任务框架APScheduler.具体的架构原理就不细说了,用个例子说明一下怎么简易的使用. 样例代码 先上样例代码,如下: #!/user/bin/env python # coding=utf-8 """ @project : csdn @aut
-
详解Python的爬虫框架 Scrapy
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便. 一.概述 下图显示了Scrapy的大体架构,其中包含了它的主要组件及系统的数据处理流程(绿色箭头所示).下面就来一个个解释每个组件的作用及数据的处理过程(注:图片来自互联网). 二.组件 1.Scrapy Engine(Scrapy引擎) Scrapy引擎
-
详解Python使用apscheduler定时执行任务
apscheduler 的使用 我们项目中总是避免不了要使用一些定时任务,比如说最近的项目,用户点击报名考试以后需要在考试日期临近的时候推送小程序消息提醒到客户微信上,翻了翻 fastapi 中的实现,虽然方法和包也不少,但是要不就是太重了(比如需要再开服务,还要依赖 redis,都不好用),虽然也可以使用 time 模块的 time.sleep()机上 fastapi 的后台任务变相实现,但是相对简单的功能还行,复杂点的代码起来就麻烦了,所以还是专人专事找个负责这个额的包吧.找来找去发现
-
详解Python利用configparser对配置文件进行读写操作
简介 想写一个登录注册的demo,但是以前的demo数据都写在程序里面,每一关掉程序数据就没保存住.. 于是想着写到配置文件里好了 Python自身提供了一个Module - configparser,来进行对配置文件的读写 Configuration file parser. A configuration file consists of sections, lead by a "[section]" header, and followed by "name: valu
-
详解Python nose单元测试框架的安装与使用
本文介绍了Python nose单元测试框架的安装与使用 ,分享给大家,具体如下: 安装(Python2下安装) pip install nose 原理与命名规则 Nose会自动查找源文件.目录或者包中的测试用例,符合正则表达式(?:^|[\b_\.%s-])[Tt]est,以及TestCase的子类都会被识别并执行. 例如:我们可以将python脚本文件名以"_test"结尾或包含"_test_",方法名以"_test"结尾. 使用方法 查看所
-
图文详解python安装Scrapy框架步骤
python书写爬虫的一个框架,它也提供了多种类型爬虫的基类,scrapy用途广泛,可以用于数据挖掘.监测和自动化测试 首先要先安装python 安装完成以后,配置一下环境变量. 还需要安装一些组件pywin32,百度搜索下载安装 pywin32安装完成还要安转pip,百度搜索pip下载下来,解压通过cmd命令进行安装 我查看一下pip是否安装成功 执行pip install Scrapy进行安装Scrapy 测试一下Scrapy框架是否安装成功,不报错就说明安装成功了
-
详解Python的Django框架中的模版相关知识
HTML被直接硬编码在 Python 代码之中. def current_datetime(request): now = datetime.datetime.now() html = "<html><body>It is now %s.</body></html>" % now return HttpResponse(html) 尽管这种技术便于解释视图是如何工作的,但直接将HTML硬编码到你的视图里却并不是一个好主意. 让我们来看一下
-
详解Python的Django框架中inclusion_tag的使用
另外一类常用的模板标签是通过渲染 其他 模板显示数据的. 比如说,Django的后台管理界面,它使用了自定义的模板标签来显示新增/编辑表单页面下部的按钮. 那些按钮看起来总是一样的,但是链接却随着所编辑的对象的不同而改变. 这就是一个使用小模板很好的例子,这些小模板就是当前对象的详细信息. 这些排序标签被称为 包含标签 .如何写包含标签最好通过举例来说明. 让我们来写一个能够产生指定作者对象的书籍清单的标签. 我们将这样利用标签: {% books_for_author author %} 结果
-
详解Python的Django框架中的通用视图
通用视图 1. 前言 回想一下,在Django中view层起到的作用是相当于controller的角色,在view中实施的 动作,一般是取得请求参数,再从model中得到数据,再通过数据创建模板,返回相应 响应对象.但在一些比较通用的功能中,比如显示对象列表,显示某对象信息,如果反复 写这么多流程的代码,也是一件浪费时间的事,在这里,Django同样给我们提供了类似的 "shortcut"捷径--通用视图. 2. 使用通用视图 使用通用视图的方法就是在urls.py这个路径配置文件中进
-
详解Python的Twisted框架中reactor事件管理器的用法
铺垫 在大量的实践中,似乎我们总是通过类似的方式来使用异步编程: 监听事件 事件发生执行对应的回调函数 回调完成(可能产生新的事件添加进监听队列) 回到1,监听事件 因此我们将这样的异步模式称为Reactor模式,例如在iOS开发中的Run Loop概念,实际上非常类似于Reactor loop,主线程的Run Loop监听屏幕UI事件,一旦发生UI事件则执行对应的事件处理代码,还可以通过GCD等方式产生事件至主线程执行. 上图是boost对Reactor模式的描绘,Twisted的设计就是基于