浅谈Redis跟MySQL的双写问题解决方案
目录
- 写在前面
- 三种读写缓存策略
- Cache-AsidePattern(旁路缓存模式)
- Read-Through/Write-Through(读写穿透)
- WriteBehindPattern(异步缓存写入)
- 旁路缓存模式解析
- CacheAsidePattern的一些疑问
- CacheAsidePattern的缺陷
项目中有遇到这个问题,跟MySQL中的数据不一致,研究一番发现这里面细节并不简单,特此记录一下。
写在前面
严格意义上任何非原子操作都不可能保证一致性,除非用阻塞读写实现强一致性,所以缓存架构我们追求的目标是最终一致性。
缓存就是通过牺牲强一致性来提高性能的。
这是由CAP理论决定的。缓存系统适用的场景就是非强一致性的场景,它属于CAP中的AP。
以下3 种缓存读写策略各有优劣,不存在最佳。
三种读写缓存策略
Cache-Aside Pattern(旁路缓存模式)
Cache-Aside Pattern,即旁路缓存模式,它的提出是为了尽可能地解决缓存与数据库的数据不一致问题。
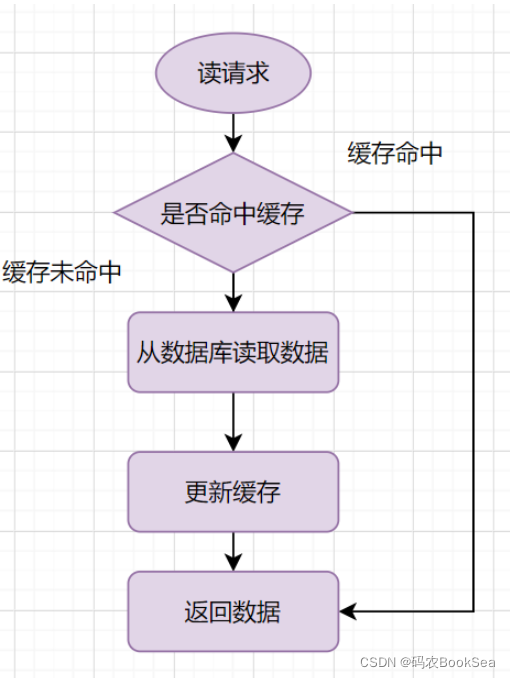
读 :从缓存读取数据,读到直接返回。如果读取不到的话,从数据库加载,写入缓存后,再返回响应。
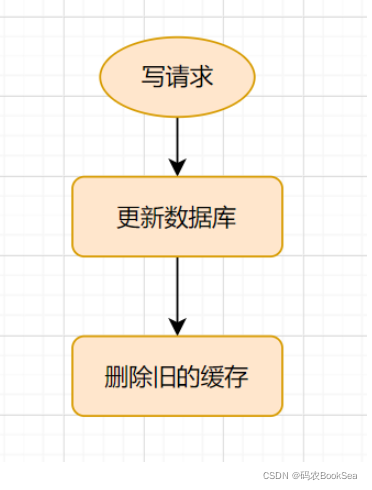
写:更新的时候,先更新数据库,然后再删除缓存。
Read-Through/Write-Through(读写穿透)
Read/Write Through Pattern 中服务端把 cache 视为主要数据存储,从中读取数据并将数据写入其中。cache 服务负责将此数据读取和写入 DB,从而减轻了应用程序的职责。
因为我们经常使用的分布式缓存 Redis 并没有提供 cache 将数据写入DB的功能,所以使用并不多。
写:先查 cache,cache 中不存在,直接更新 DB。cache 中存在,则先更新 cache,然后 cache 服务自己更新 DB(同步更新 cache和DB)。
读:从 cache 中读取数据,读取到就直接返回 。读取不到的话,先从 DB 加载,写入到 cache 后返回响应。
Write Behind Pattern(异步缓存写入)
Write Behind Pattern 和 Read/Write Through Pattern 很相似,两者都是由 cache 服务来负责 cache 和 DB 的读写。
但是,两个又有很大的不同:Read/Write Through 是同步更新 cache 和 DB,而 Write Behind Caching 则是只更新缓存,不直接更新 DB,而是改为异步批量的方式来更新 DB。
很明显,这种方式对数据一致性带来了更大的挑战,比如cache数据可能还没异步更新DB的话,cache服务可能就挂掉了,反而会带来更大的灾难。
这种策略在我们平时开发过程中也非常非常少见,但是不代表它的应用场景少,比如消息队列中消息的异步写入磁盘、MySQL 的 InnoDB Buffer Pool 机制都用到了这种策略。
Write Behind Pattern 下 DB 的写性能非常高,非常适合一些数据经常变化又对数据一致性要求没那么高的场景,比如浏览量、点赞量。
旁路缓存模式解析
Cache Aside Pattern 的一些疑问
旁路缓存模式是我们平时中使用最多的。下面根据上面介绍的旁路缓存模式,我们可以有以下几个疑问。
为什么写操作是删除缓存,而不是更新缓存
答:线程A先发起一个写操作,第一步先更新数据库。线程B再发起一个写操作,第二步更新了数据库,由于网络等原因,线程B先更新了缓存,线程A更新缓存。
这时候,缓存保存的是A的数据(老数据),数据库保存的是B的数据(新数据),数据不一致了,脏数据出现啦。如果是删除缓存取代更新缓存则不会出现这个脏数据问题。
实际上要写操作的时候更新缓存也是可以的,不过我们需要加一个锁/分布式锁来保证更新cache的时候不存在线程安全问题。
在写数据的过程中,为什么要先更新DB在删除缓存
答:比如说请求1 是写操作,要是先删除缓存A,请求2是读操作,先读缓存A,发现缓存被删除了(被请求1删除了),然后去读数据库,但是此时请求1还没来得及把数据及时更新,那么请求2读的就是旧数据,并且请求2还会把读到的旧数据放到缓存中,造成了数据的不一致。
其实要先删缓存,再更新数据库也是可以,如采用延时双删策略
休眠1秒,再次淘汰缓存 这么做,可以将1秒内所造成的缓存脏数据,再次删除。不一定是1秒,看你业务决定的,不过不推荐这种做法,因为在这1秒内可能发生因素很多,它的不确定性太大。
在写数据的过程中,先更新DB,后删除cache就没有问题了么?
答: 理论上来说还是可能会出现数据不一致性的问题,不过概率非常小。
假设这会有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生
(1)缓存刚好失效
(2)请求A查询数据库,得一个旧值
(3)请求B将新值写入数据库
(4)请求B删除缓存
(5)请求A将查到的旧值写入缓存 ok,如果发生上述情况,确实是会发生脏数据。
然而,发生这种情况的概率并不高
发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。
可是,仔细想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少),因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。
还有其他造成不一致的原因么?
答: 如果删除缓存过程中失败了就会造成不一致问题
如何解决?
使用Canal去订阅数据库的binlog,获得需要操作的数据。另起一个程序,获得这个订阅程序传来的信息,进行删除缓存操作。
Cache Aside Pattern 的缺陷
缺陷1:首次请求数据一定不在 cache 的问题
解决办法:可以将热点数据提前放入cache 中。
缺陷2:写操作比较频繁的话导致cache中的数据会被频繁被删除,这样会影响缓存命中率 。
数据库和缓存数据强一致场景 :更新DB的时候同样更新cache,不过我们需要加一个锁/分布式锁来保证更新cache的时候不存在线程安全问题。可以短暂地允许数据库和缓存数据不一致的场景 :更新DB的时候同样更新cache,但是给缓存加一个比较短的过期时间,这样的话就可以保证即使数据不一致的话影响也比较小。
到此这篇关于浅谈Redis跟MySQL的双写问题解决方案的文章就介绍到这了,更多相关Redis MySQL双写内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

聊一聊Redis与MySQL双写一致性如何保证
1 什么是一致性? 一致性就是数据保持一致,在分布式系统中,可以理解为多个节点中数据的值是一致的. 强一致性: 这种一致性级别是最符合用户直觉的,它要求系统写入什么,读出来的也会是什么,用户体验性好,但实现起来往往对系统的性能影响大: 弱一致性: 这种一致性级别约束了系统在写入成功后,不承诺立即可以读到写入的值,也不承诺多久之后数据能够达到一致,但会尽可能地保证到某个时间级别(比如秒级别)后,数据能够达到一致状态: 最终一致性: 最终一致性是弱一致性的一个特例,系统会保证在一定时间内,能够达到一
-
浅谈Redis跟MySQL的双写问题解决方案
目录 写在前面 三种读写缓存策略 Cache-AsidePattern(旁路缓存模式) Read-Through/Write-Through(读写穿透) WriteBehindPattern(异步缓存写入) 旁路缓存模式解析 CacheAsidePattern的一些疑问 CacheAsidePattern的缺陷 项目中有遇到这个问题,跟MySQL中的数据不一致,研究一番发现这里面细节并不简单,特此记录一下. 写在前面 严格意义上任何非原子操作都不可能保证一致性,除非用阻塞读写实现强一致性,所以缓
-
Redis与MySQL的双写一致性问题
目录 更新缓存? 删除缓存? 先更新缓存再更新数据库 先更新数据库,再更新缓存 先删除缓存再更新数据库 先更新数据库,再删除缓存 解决方案 1. 重试 2. 异步重试 2.1 使用消息队列实现重试 2.2 Binlog实现异步重试删除 3. 延时双删 总结 Redis与MySQL双写一致性是指在使用缓存和数据库同时存储数据的场景下( 主要是存在高并发的情况),如何保证两者的数据一致性(内容相同或者尽可能接近). 正常业务流程: 读没什么问题,关键就在于写(更新)操作,这就会出现几个问题了,这里是
-
浅谈如何保证Mysql主从一致
目录 binlog的三种格式对比 为什么会有mixed格式的binlog? 循环复制问题 小结 为什么备库执行了 binlog 就可以跟主库保持一致了呢?今天正式地和你介绍一下它. 在最开始,MySQL 是以容易学习和方便的高可用架构,被开发人员青睐的.而它的几乎所有的高可用架构,都直接依赖于 binlog.虽然这些高可用架构已经呈现出越来越复杂的趋势,但都是从最基本的一主一备演化过来的. MySQL 主备的基本原理 图 1 MySQL 主备切换流程 在状态 1 中,客户端的读写都直接访问节点
-
浅谈Redis高并发缓存架构性能优化实战
目录 场景1: 中小型公司Redis缓存架构以及线上问题实战 场景2: 大厂线上大规模商品缓存数据冷热分离实战 场景3: 基于DCL机制解决热点缓存并发重建问题实战 场景4: 突发性热点缓存重建导致系统压力暴增 场景5: 解决大规模缓存击穿导致线上数据库压力暴增 场景6: 黑客工资导致缓存穿透线上数据库宕机 场景7: 大V直播带货导致线上商品系统崩溃原因分析 场景8: Redis分布式锁解决缓存与数据库双写不一致问题实战 场景9: 大促压力暴增导致分布式锁串行争用问题优化 场景10: 利用多级缓
-
浅谈PHP值mysql操作类
浅谈PHP值mysql操作类 <?php /** * Created by PhpStorm. * User: Administrator * Date: 2016/6/27 * Time: 18:55 */ Class Mysqls{ private $table; //表 private $opt; public function __construct($host,$user,$pwd,$name,$table_names) { $this->db=new mysqli($host,$u
-
浅谈redis五大数据结构和使用场景
老规矩,先抛结论后验证 string:有点像java的hashMap,存的时候什么key,取的时候也什么key,常用于做缓存,保存用户信息.查询列表等: hash:这个有点像hashMap的value又套了个hashMap,下文有举例,一看就明白了: list:有序列表,类似Java的linkedList,可以在左边右边插入数据: set:去重集合,类似Java的hashset,可用于求交集,比如共同好友: zset:带权重的set集合,可用于做排行榜: 为了方便理解,我们基于这个dog类来做测
-
浅谈Redis主从复制以及主从复制原理
面临问题 1. 机器故障.我们部署到一台 Redis 服务器,当发生机器故障时,需要迁移到另外一台服务器并且要保证数据是同步的.而数据是最重要的,如果你不在乎,基本上也就不会使用 Redis 了. 2. 容量瓶颈.当我们有需求需要扩容 Redis 内存时,从 16G 的内存升到 64G,单机肯定是满足不了.当然,你可以重新买个 128G 的新机器. 解决办法 要实现分布式数据库的更大的存储容量和承受高并发访问量,我们会将原来集中式数据库的数据分别存储到其他多个网络节点上.Redis 为了解决这个
-
浅谈Redis中的RDB快照
一.概述 所谓的快照,就是记录某一个瞬间东西,比如当我们给风景拍照时,那一个瞬间的画面和信息就记录到了一张照片. 所以,RDB 快照就是记录某一个瞬间的内存数据,记录的是实际数据,而 AOF 文件记录的是命令操作的日志,而不是实际的数据. 因此在 Redis 恢复数据时, RDB 恢复数据的效率会比 AOF 快些,因为直接将 RDB 文件读入内存就可以了,不需要像 AOF 那样还需要额外执行操作命令的步骤才能恢复数据. 接下来,就来具体聊聊 RDB 快照 . 二.快照怎么用? 要熟悉一个东西,先
-
浅谈Redis缓存有哪些淘汰策略
目录 Redis过期策略 定时删除 惰性删除 定期删除 Redis的内存淘汰机制 LRU和LFU的区别 LRU LFU Redis重启如何恢复数据呢? 总结 Redis过期策略 我们首先来了解一下Redis的内存淘汰机制. 定时删除 概述 redis默认是每隔 100ms 就随机抽取一些设置了过期时间的key,检查其是否过期,如果过期就删除.注意这里是随机抽取的.为什么要随机呢?你想一想假如 redis 存了几十万个 key ,每隔100ms就遍历所有的设置过期时间的 key 的话,就会
-
浅谈Redis对于过期键的三种清除策略
目录 Pre Redis Key的超时设置处理 被动删除 主动删除 当前已用内存超过maxmemory限定时,触发主动清理策略 对于过期键一般有三种删除策略 定时删除:在设置键的过期时间的同时,创建一个定时器(timer),让定时器在键的过期时间来临时,立即执行对键的删除操作: 惰性删除:放任键过期不管,但是每次从键空间中获取键时,都检查取得的键是否过期,如果过期的话,就删除该键:如果没有过期,那就返回该键: 定期删除:每隔一段时间,程序就对数据库进行一次检查,删除里面的过期键.至于删除多少过期