教你如何利用python3爬虫爬取漫画岛-非人哉漫画
最近学了一点点python爬虫的知识,面向百度编程爬了一本小说之后感觉有点不满足,于是突发奇想尝试爬一本漫画下来看看。
一、效果展示
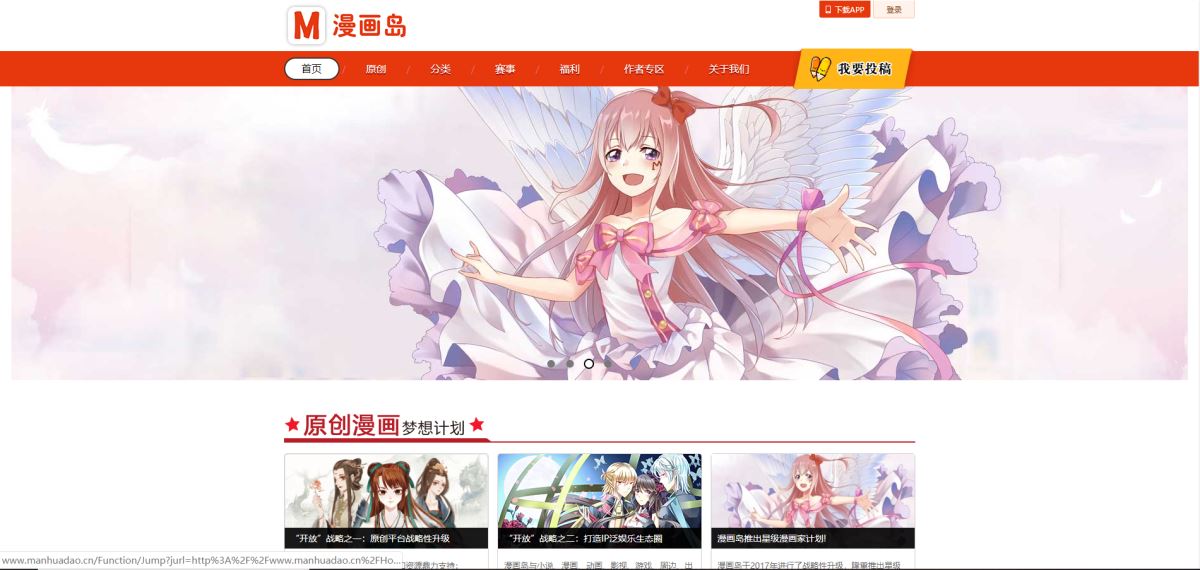
首先是我们想要爬取的漫画网页:http://www.manhuadao.cn/
网页截图:
其次是爬取下来的效果:

每一回的文件夹里面是这样的: (因为网站图片的问题...所以就成了这个鬼样子)

二、分析原理
1、准备:需要vscode或者其他能够编译运行python的软件,推荐python版本3.X ,否则有可能出现编译问题。
下载所需模块:win+R进入命令行,输入pipinstall <模块名>即可下载。例如:
pip install beautifulsoup4
2、原理: 模拟浏览器点击->打开漫画网页链接->获取网页源码->定位每一章漫画的链接->模拟点击->获取图片页面源码->定位图片链接->下载图片
三、实际操作(代码附在最后)
1、引入模块 (这里不再详述)

2、模拟浏览器访问网页

(1)、这里我们打开漫画的目录页,如下: url = ”http://www.manhuadao.cn/Home/ComicDetail?id=58ddb07827a7c1392c234628“ ,此链接就是目录页链接。

(2)、按F12打开此网页的源码(谷歌浏览器),选中上方NetWork,Ctrl+R刷新。

(3)、找到加载网页的源码文件,点击Headers,如下图: StatusCode表示网页返回的代码,值为200时表示访问成功。

(4)、headers中的参数为下面红框User-Agent。
response = requests.get(url=url, headers=headers) # 模拟访问网页 print(response) # 此处应输出 <Response [200]> print(response.text) # 输出网页源码
两个输出分别输出:
 输出返回200表示访问成功。
输出返回200表示访问成功。
 (节选)
(节选)
(5)、将html代码存入 data 中,xpath定位每一章链接。点击上方Element,点击:
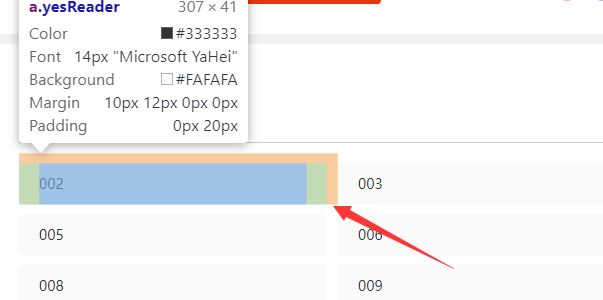
将鼠标移至目录处:
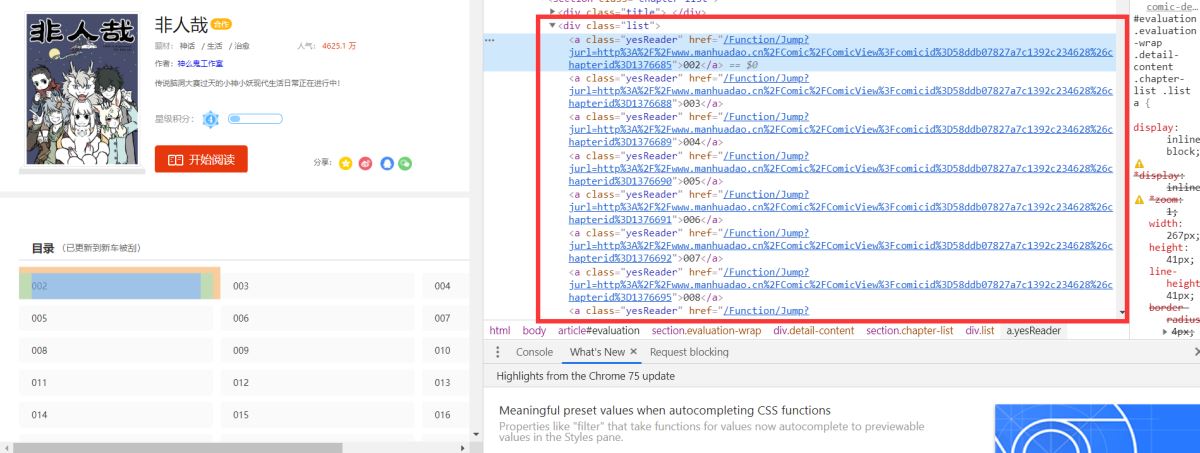
右边代码区域出现每一章链接:
data = etree.HTML(response.text)
# tp = data.xpath('//ul[@class="read-chapter"]/li/a[@class="active"]/@href')
tp = data.xpath('//*[@class="yesReader"]/@href')
zhang_list = tp # tp为链接列表
输出zhang_list,结果如下:

(6)、获取图片链接(获取方式同上一步)
点进第一章,同上一步,寻找到图片链接:

i=1
for next_zhang in zhang_list: # 在章节列表中循环
i=i+1
j=0
hui_url = r_url+next_zhang
name1 = "第"+str(i)+"回"
file = 'C:/Users/wangyueke/Desktop/'+keyword+'/{}/'.format(name1) # 创建文件夹
if not os.path.exists(file):
os.makedirs(file)
print('创建文件夹:', file)
response = requests.get(url=hui_url, headers=headers) # 模拟访问每一章链接
data = etree.HTML(response.text)
# tp = data.xpath('//div[@class="no-pic"]//img/@src')
tp = data.xpath('//div[@class="main-content"]//ul//li//div[@class="no-pic"]//img/@src') # 定位
ye_list = tp
(7)、下载图片
for k in ye_list: # 在每一章的图片链接列表中循环
download_url = tp[j]
print(download_url)
j=j+1
file_name="第"+str(j)+"页"
response = requests.get(url=download_url) # 模拟访问图片链接
with open(file+file_name+".jpg","wb") as f:
f.write(response.content)
五、代码
'''
用于爬取非人哉漫画
目标网址:http://www.manhuadao.cn/
开始时间:2019/8/14 20:01:26
完成时间:2019/8/15 11:04:56
作者:kong_gu
'''
import requests
import json
import time
import os
from lxml import etree
from bs4 import BeautifulSoup
def main():
keyword="非人哉"
file = 'E:/{}'.format(keyword)
if not os.path.exists(file):
os.mkdir(file)
print('创建文件夹:',file)
r_url="http://www.manhuadao.cn/"
url = "http://www.manhuadao.cn/Home/ComicDetail?id=58ddb07827a7c1392c234628"
headers = { # 模拟浏览器访问网页
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) \\Chrome/75.0.3770.142 Safari/537.36'}
response = requests.get(url=url, headers=headers)
# print(response.text) # 输出网页源码
data = etree.HTML(response.text)
# tp = data.xpath('//ul[@class="read-chapter"]/li/a[@class="active"]/@href')
tp = data.xpath('//*[@class="yesReader"]/@href')
zhang_list = tp
i=1
for next_zhang in zhang_list:
i=i+1
j=0
hui_url = r_url+next_zhang
name1 = "第"+str(i)+"回"
file = 'C:/Users/wangyueke/Desktop/'+keyword+'/{}/'.format(name1) # 这里需要自己设置路径
if not os.path.exists(file):
os.makedirs(file)
print('创建文件夹:', file)
response = requests.get(url=hui_url, headers=headers)
data = etree.HTML(response.text)
# tp = data.xpath('//div[@class="no-pic"]//img/@src')
tp = data.xpath('//div[@class="main-content"]//ul//li//div[@class="no-pic"]//img/@src')
ye_list = tp
for k in ye_list:
download_url = tp[j]
print(download_url)
j=j+1
file_name="第"+str(j)+"页"
response = requests.get(url=download_url)
with open(file+file_name+".jpg","wb") as f:
f.write(response.content)
if __name__ == '__main__':
main()
到此这篇关于利用python3爬虫爬取漫画岛-非人哉漫画的文章就介绍到这了,更多相关python3爬虫漫画岛内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python3 Scrapy爬虫框架ip代理配置的方法
什么是Scrapy? Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍.所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板.对于框架的学习,重点是要学习其框架的特性.各个功能的用法即可. 一.背景 在做爬虫项目的过程中遇到ip代理的问题,网上搜了一些,要么是用阿里云的ip代理,要么是搜一些网上现有的ip资源,然后配置在setting文件中.这两个方法都存在一些问题. 1.阿里云ip代理方法,网上大
-
python3.7简单的爬虫实例详解
python3.7简单的爬虫,具体代码如下所示: #https://www.runoob.com/w3cnote/python-spider-intro.html #Python 爬虫介绍 import urllib.parse import urllib.request from http import cookiejar url = "http://www.baidu.com" response1 = urllib.request.urlopen(url) print("
-
Python3网络爬虫中的requests高级用法详解
本节我们再来了解下 Requests 的一些高级用法,如文件上传,代理设置,Cookies 设置等等. 1. 文件上传 我们知道 Reqeuests 可以模拟提交一些数据,假如有的网站需要我们上传文件,我们同样可以利用它来上传,实现非常简单,实例如下: import requests files = {'file': open('favicon.ico', 'rb')} r = requests.post('http://httpbin.org/post', files=files) print
-
Python3简单爬虫抓取网页图片代码实例
现在网上有很多python2写的爬虫抓取网页图片的实例,但不适用新手(新手都使用python3环境,不兼容python2), 所以我用Python3的语法写了一个简单抓取网页图片的实例,希望能够帮助到大家,并希望大家批评指正. import urllib.request import re import os import urllib #根据给定的网址来获取网页详细信息,得到的html就是网页的源代码 def getHtml(url): page = urllib.request.urlope
-
教你如何利用python3爬虫爬取漫画岛-非人哉漫画
最近学了一点点python爬虫的知识,面向百度编程爬了一本小说之后感觉有点不满足,于是突发奇想尝试爬一本漫画下来看看. 一.效果展示 首先是我们想要爬取的漫画网页:http://www.manhuadao.cn/ 网页截图: 其次是爬取下来的效果: 每一回的文件夹里面是这样的: (因为网站图片的问题...所以就成了这个鬼样子) 二.分析原理 1.准备:需要vscode或者其他能够编译运行python的软件,推荐python版本3.X ,否则有可能出现编译问题. 下载所需模块:win+R进入命令行
-
利用Python爬虫爬取金融期货数据的案例分析
目录 任务简介 解决步骤 代码实现 总结 大家好 我是政胤今天教大家爬取金融期货数据 任务简介 首先,客户原需求是获取https://hq.smm.cn/copper网站上的价格数据(注:获取的是网站上的公开数据),如下图所示: 如果以该网站为目标,则需要解决的问题是“登录”用户,再将价格解析为表格进行输出即可.但是,实际上客户核心目标是获取“沪铜CU2206”的历史价格,虽然该网站也有提供数据,但是需要“会员”才可以访问,而会员需要氪金...... 数据的价值!!! 鉴于,客户需求仅仅是“沪铜
-
Python3爬虫爬取百姓网列表并保存为json功能示例【基于request、lxml和json模块】
本文实例讲述了Python3爬虫爬取百姓网列表并保存为json功能.分享给大家供大家参考,具体如下: python3爬虫之爬取百姓网列表并保存为json文件.这几天一直在学习使用python3爬取数据,今天记录一下,代码很简单很容易上手. 首先需要安装python3.如果还没有安装,可参考本站python3安装与配置相关文章. 首先需要安装requests和lxml和json三个模块 需要手动创建d.json文件 代码 import requests from lxml import etree
-
Python3爬虫爬取英雄联盟高清桌面壁纸功能示例【基于Scrapy框架】
本文实例讲述了Python3爬虫爬取英雄联盟高清桌面壁纸功能.分享给大家供大家参考,具体如下: 使用Scrapy爬虫抓取英雄联盟高清桌面壁纸 源码地址:https://github.com/snowyme/loldesk 开始项目前需要安装python3和Scrapy,不会的自行百度,这里就不具体介绍了 首先,创建项目 scrapy startproject loldesk 生成项目的目录结构 首先需要定义抓取元素,在item.py中,我们这个项目用到了图片名和链接 import scrapy
-
手把手教你用Node.js爬虫爬取网站数据的方法
开始之前请先确保自己安装了Node.js环境,还没有安装的的童鞋请看一下安装教程...... https://www.jb51.net/article/113677.htm https://www.jb51.net/article/57687.htm 直接开始吧 1.在项目文件夹安装两个必须的依赖包 npm install superagent --save-dev SuperAgent(官网是这样解释的) -----SuperAgent is light-weight progressive
-
python利用urllib实现爬取京东网站商品图片的爬虫实例
本例程使用urlib实现的,基于python2.7版本,采用beautifulsoup进行网页分析,没有第三方库的应该安装上之后才能运行,我用的IDE是pycharm,闲话少说,直接上代码! # -*- coding: utf-8 -* import re import os import urllib import urllib2 from bs4 import BeautifulSoup def craw(url,page): html1=urllib2.urlopen(url).read(
-
Python3实现爬虫爬取赶集网列表功能【基于request和BeautifulSoup模块】
本文实例讲述了Python3实现爬虫爬取赶集网列表功能.分享给大家供大家参考,具体如下: python3爬虫之爬取赶集网列表.这几天一直在学习使用python3爬取数据,今天记录一下,代码很简单很容易上手. 首先需要安装python3.如果还没有安装,可参考本站前面关于python3安装与配置相关文章. 首先需要安装request和BeautifulSoup两个模块 request是Python的HTTP网络请求模块,使用Requests可以轻而易举的完成浏览器可有的任何操作 pip insta
-
Python3实现的爬虫爬取数据并存入mysql数据库操作示例
本文实例讲述了Python3实现的爬虫爬取数据并存入mysql数据库操作.分享给大家供大家参考,具体如下: 爬一个电脑客户端的订单.罗总推荐,抓包工具用的是HttpAnalyzerStdV7,与chrome自带的F12类似.客户端有接单大厅,罗列所有订单的简要信息.当单子被接了,就不存在了.我要做的是新出订单就爬取记录到我的数据库zyc里. 设置每10s爬一次. 抓包工具页面如图: 首先是爬虫,先找到数据存储的页面,再用正则爬出. # -*- coding:utf-8 -*- import re
-
python爬虫之利用Selenium+Requests爬取拉勾网
一.前言 利用selenium+requests访问页面爬取拉勾网招聘信息 二.分析url 观察页面可知,页面数据属于动态加载 所以现在我们通过抓包工具,获取数据包 观察其url和参数 url="https://www.lagou.com/jobs/positionAjax.json?px=default&needAddtionalResult=false" 参数: city=%E5%8C%97%E4%BA%AC ==>城市 first=true ==>无用 pn=
-
利用Python网络爬虫爬取各大音乐评论的代码
python爬虫--爬取网易云音乐评论 方1:使用selenium模块,简单粗暴.但是虽然方便但是缺点也是很明显,运行慢等等等. 方2:常规思路:直接去请求服务器 1.简易看出评论是动态加载的,一定是ajax方式. 2.通过网络抓包,可以找出评论请求的的URL 得到请求的URL 3.去查看post请求所上传的数据 显然是经过加密的,现在就需要按着网易的思路去解读加密过程,然后进行模拟加密. 4.首先去查看请求是经过那些js到达服务器的 5.设置断点:依次对所发送的内容进行观察,找到评论对应的UR