Python实现批量向PDF文件添加中文水印
目录
- 前言
- 实现步骤
- 完整代码
前言
可以通过设置批量PDF文件所在的路径及需要添加的水印名称可以实现批量添加PDF水印的效果。
实现思路是这样的,通过在批量PDF文件路径下面生成一个带有水印的PDF模板。最后,将批量文件的每个PDF页面和水印模板进行合并完成批量添加水印的效果。
需要注意的是批量PDF文件必须和PDF模板水印文件的大小尺寸保持一致,这个可以在代码里面调节一下就成了。
实现步骤
首先将需要添加水印的PDF文件准备好放在一个文件夹下面。

在代码中设置好PDF批量文件的路径及水印名称。
if __name__ == '__main__':
main('C:/pdf', '我是一个水印')
内部实现过程都封装在main()函数里面了,这里改一下水印名称和批量PDF文件路径直接执行就好了。
启动以后,出现如下面的结果说明已经执行完成了。
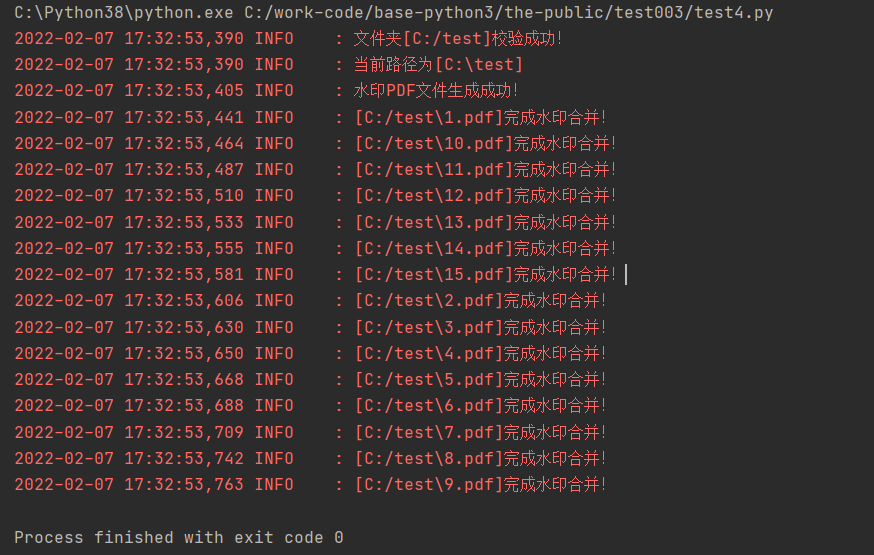
为了不覆盖原来的PDF文件,合并后的文件都是添加了"已合并"字样的PDF文件。

说完了怎么操作,看一下主要的代码块部分有哪些吧。
其中用到的第三方库有下面这些,里面我写了相关的注释。
import os # 应用文件操作
# reportlab是Python的一个标准库,可以画图、画表格、编辑文字,最后可以输出PDF格式。
from reportlab.pdfgen import canvas
from reportlab.lib.units import cm
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
pdfmetrics.registerFont(TTFont('songti', 'C:/Windows/Fonts/simsun.ttc')) # 加载宋体
# PyPDF2模块主要的功能是分割或合并PDF文件,裁剪或转换PDF文件中的页面。
from PyPDF2 import PdfFileWriter, PdfFileReader
import logging # 日志打印库
日志模块的初始化也比较简单,前面的文章中都有过相关的调用。
# 初始化日志设置
logger = logging.getLogger('批量添加水印')
logging.basicConfig(format='%(asctime)s %(levelname)-8s: %(message)s')
logger.setLevel(logging.DEBUG)
日志初始化完成后在后面需要打印日志的地方调用就可以了。
实现过程主要有三个函数来实现的,一个是为了生成水印模板、另一个是使水印模板和批量PDF文件执行合并从而实现添加水印的功能、还有一个就是逐个遍历批量PDF文件使其能够逐个实现水印合并。
水印模板生成函数。
def generate_water_pdf(content):
'''
生成带有水印的PDF
:param content: 水印名称
:return:
'''
cans = canvas.Canvas('water_back.pdf', pagesize=(21 * cm, 29.7 * cm))
cans.translate(10 * cm,
12 * cm) # 移动原点坐标
cans.setFont('songti', 23) # 设置字体为宋体、大小为23号
cans.setFillColorRGB(0.5, 0.5,
0.5) # 设置字体背景颜色
cans.rotate(45) # 设置字体倾斜45度
cans.drawString(-7 * cm, 0 * cm, content)
cans.drawString(7 * cm, 0 * cm, content)
cans.drawString(0 * cm, 7 * cm, content)
cans.drawString(0 * cm, -7 * cm, content)
cans.save() # 保存水印的PDF文件
水印合成实现函数。
def insert_water_to_pdf(input_pdf, output_pdf, water_pdf): ''' 合并水印到PDF文件中 :param input_pdf: 输入文件路径 :param output_pdf: 输出文件路径 :param water_pdf: 水印文件路径 :return: ''' water = PdfFileReader(water_pdf) # 读取水印PDF water_page = water.getPage(0) # 获取水印PDF的第一页 pdf = PdfFileReader(input_pdf, strict=False) # 读取需要添加水印的文件 pdf_writer = PdfFileWriter() # 创建PDF文件写入对象 for page in range(pdf.getNumPages()): # 遍历每一页PDF对象 pdf_page = pdf.getPage(page) # 获取PDF的当前页对象 pdf_page.mergePage(water_page) # 将水印页合并到当前页中 pdf_writer.addPage(pdf_page) # 将合并后的PDF对象页添加到PDF写入对象中 output_file = open(output_pdf, 'wb') # 打开PDF输出文件 pdf_writer.write(output_file) # 将文件写入到输出文件 output_file.close() # 关闭写入流
批量PDF文件遍历调用合成函数。
def main(diretory, current):
if os.path.isdir(diretory):
logger.info('文件夹[' + diretory + ']校验成功!')
os.chdir(diretory)
logger.info('当前路径为[' + os.getcwd() + ']')
generate_water_pdf(current)
logger.info('水印PDF文件生成成功!')
for file_path, dir_names, file_names in os.walk(r'' + os.getcwd()):
for file_name in file_names:
try:
name = file_name.split('.')[0]
if name == 'water_back':
continue
else:
file_name_path = os.path.join(file_path, file_name)
output_file_path = file_name_path.split('.')[0] + '_已添加水印.pdf'
insert_water_to_pdf(file_name_path, output_file_path, 'water_back.pdf')
logger.info('[' + file_name_path + ']完成水印合并!')
except Exception as e:
logger.error('[' + file_name_path + ']发生异常,执行下一个!')
logger.error('异常信息:' + repr(e))
else:
logger.info('文件夹[' + diretory + ']校验失败!')
主要实现过程就是通过上面三个函数来完成的,最后调用后台入口函数将mian()函数调用执行就可以了。
完整代码
# -*- coding:utf-8 -*-
# @author Python 集中营
# @date 2022/1/27
# @file test4.py
# done
# 批量向PDF文件添加中文水印
import os # 应用文件操作
# reportlab是Python的一个标准库,可以画图、画表格、编辑文字,最后可以输出PDF格式。
from reportlab.pdfgen import canvas
from reportlab.lib.units import cm
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
pdfmetrics.registerFont(TTFont('songti', 'C:/Windows/Fonts/simsun.ttc')) # 加载宋体
# PyPDF2模块主要的功能是分割或合并PDF文件,裁剪或转换PDF文件中的页面。
from PyPDF2 import PdfFileWriter, PdfFileReader
import logging # 日志打印库
# 初始化日志设置
logger = logging.getLogger('批量添加水印')
logging.basicConfig(format='%(asctime)s %(levelname)-8s: %(message)s')
logger.setLevel(logging.DEBUG)
def generate_water_pdf(content):
'''
生成带有水印的PDF
:param content: 水印名称
:return:
'''
cans = canvas.Canvas('water_back.pdf', pagesize=(21 * cm, 29.7 * cm))
cans.translate(10 * cm,
12 * cm) # 移动原点坐标
cans.setFont('songti', 23) # 设置字体为宋体、大小为23号
cans.setFillColorRGB(0.5, 0.5,
0.5) # 设置字体背景颜色
cans.rotate(45) # 设置字体倾斜45度
cans.drawString(-7 * cm, 0 * cm, content)
cans.drawString(7 * cm, 0 * cm, content)
cans.drawString(0 * cm, 7 * cm, content)
cans.drawString(0 * cm, -7 * cm, content)
cans.save() # 保存水印的PDF文件
def insert_water_to_pdf(input_pdf, output_pdf, water_pdf):
'''
合并水印到PDF文件中
:param input_pdf: 输入文件路径
:param output_pdf: 输出文件路径
:param water_pdf: 水印文件路径
:return:
'''
water = PdfFileReader(water_pdf) # 读取水印PDF
water_page = water.getPage(0) # 获取水印PDF的第一页
pdf = PdfFileReader(input_pdf, strict=False) # 读取需要添加水印的文件
pdf_writer = PdfFileWriter() # 创建PDF文件写入对象
for page in range(pdf.getNumPages()): # 遍历每一页PDF对象
pdf_page = pdf.getPage(page) # 获取PDF的当前页对象
pdf_page.mergePage(water_page) # 将水印页合并到当前页中
pdf_writer.addPage(pdf_page) # 将合并后的PDF对象页添加到PDF写入对象中
output_file = open(output_pdf, 'wb') # 打开PDF输出文件
pdf_writer.write(output_file) # 将文件写入到输出文件
output_file.close() # 关闭写入流
def main(diretory, current):
if os.path.isdir(diretory):
logger.info('文件夹[' + diretory + ']校验成功!')
os.chdir(diretory)
logger.info('当前路径为[' + os.getcwd() + ']')
generate_water_pdf(current)
logger.info('水印PDF文件生成成功!')
for file_path, dir_names, file_names in os.walk(r'' + os.getcwd()):
for file_name in file_names:
try:
name = file_name.split('.')[0]
if name == 'water_back':
continue
else:
file_name_path = os.path.join(file_path, file_name)
output_file_path = file_name_path.split('.')[0] + '_已添加水印.pdf'
insert_water_to_pdf(file_name_path, output_file_path, 'water_back.pdf')
logger.info('[' + file_name_path + ']完成水印合并!')
except Exception as e:
logger.error('[' + file_name_path + ']发生异常,执行下一个!')
logger.error('异常信息:' + repr(e))
else:
logger.info('文件夹[' + diretory + ']校验失败!')
if __name__ == '__main__':
main('C:/pdf', '我是一个水印')
到此这篇关于Python实现批量向PDF文件添加中文水印的文章就介绍到这了,更多相关Python PDF添加水印内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现PDF转换文本详解
目录 一.前言 1.1.为什么不使用传统的pdf 转文本工具呢? 二.实现过程 2.1.基于深度学习的 OCR 将 pdf 为文本 2.1.1.将 pdf 转换为图像 2.1.2.检测和识别图像中的文本 2.1.3.示例输出 总结 一.前言 对很多人来说,将PDF转换为可编辑的文本是个刚需,却苦于没有简单的方法.发现 pdf 幻灯片,效果还不错. 传统的讲座通常伴随有很多pdf幻灯片.一般来说,想要对自己的讲座做笔记,需要从pdf复制.补充大量内容. 最近,来自 K1 Digital 的高级机器
-
Python去除PDF水印的实现示例
今天介绍下用 Python 去除 PDF (图片)的水印.思路很简单,代码也很简洁. 首先来考虑 Python 如何去除图片的水印,然后再将思路复用到 PDF 上面. 这张图片是前几天整理<数据结构和算法>PDF里的一个截图,带着公众号的水印. 从上图可以明显看到,为了不影响阅读正文,水印颜色一般比较浅.因此,我们可以利用颜色差这个特征来去掉水印.即:用 Python 读取图片的颜色,并将浅颜色部分变白. Python 标准库 PIL 可以获取图片的颜色,Python2 是系统自带的,Pyth
-
python为图片和PDF去水印详解
目录 安装模块 获取图片的 RGB 图片去水印 PDF 去水印 图片转为 pdf 总结 网上下载的 pdf 学习资料有一些会带有水印,非常影响阅读.比如下面的图片就是在 pdf 文件上截取出来的. 安装模块 PIL:Python Imaging Library 是 python 上非常强大的图像处理标准库,但是只能支持 python 2.7,于是就有志愿者在 PIL 的基础上创建了支持 python 3的 pillow,并加入了一些新的特性. pip install pillow pymupdf
-
Python合并pdf文件的工具
如果你需要一个PDF文件合并工具,那么本文章完全可以满足您的要求.哈喽,大家好呀,这里是滑稽研究所.不多废话,本期我们利用Python合并把多个pdf文件合并为一个.我们提前准备了5个pdf文件,来验证代码. 源代码: import os from PyPDF2 import PdfFileReader, PdfFileWriter # 使用os模块的walk函数,搜索出指定目录下的全部PDF文件 # 获取同一目录下的所有PDF文件的绝对路径 def getFileName(filedi
-
Python实现给PDF添加水印的方法
前言 利用 PyPDF2 处理 PDF 文件,相关文档:https://pythonhosted.org/PyPDF2/ 本文针对 仅有 PDF 文件,而无相关 PDF 编辑器的情况下,给 PDF 添加水印. 一.前期准备 安装 PyPDF2 ,命令提示框输入: pip install PyPDF2 新建 watermark.pdf 文件 实际的水印,可以在此文件里修改水印文字的字体和位置. 实现步骤: 新建 watermark.word ,[设计] → \to → [水印][自定义水印] →
-
Python实现批量向PDF文件添加中文水印
目录 前言 实现步骤 完整代码 前言 可以通过设置批量PDF文件所在的路径及需要添加的水印名称可以实现批量添加PDF水印的效果. 实现思路是这样的,通过在批量PDF文件路径下面生成一个带有水印的PDF模板.最后,将批量文件的每个PDF页面和水印模板进行合并完成批量添加水印的效果. 需要注意的是批量PDF文件必须和PDF模板水印文件的大小尺寸保持一致,这个可以在代码里面调节一下就成了. 实现步骤 首先将需要添加水印的PDF文件准备好放在一个文件夹下面. 在代码中设置好PDF批量文件的路径及水印名称
-
Python批量提取PDF文件中文本的脚本
本文实例为大家分享了Python批量提取PDF文件中文本的具体代码,供大家参考,具体内容如下 首先需要执行命令pip install pdfminer3k来安装处理PDF文件的扩展库. import os import sys import time pdfs = (pdfs for pdfs in os.listdir('.') if pdfs.endswith('.pdf')) for pdf1 in pdfs: pdf = pdf1.replace(' ', '_').replace('-
-
2行Python代码实现给pdf文件添加水印
目录 1. 引言 2.指定水印内容输出到pdf文件 2.1 模块安装 2.2 思路 2.3 代码示例 3.水印内容批量输出到pdf文件 3.1 模块安装 3.2 思路 3.3 代码示例 4.总结 1. 引言 小屌丝:鱼哥,新年快乐! 小鱼:无事不登三宝殿,有啥事,你直说吧… 小屌丝:别说的这么直接,这大过年的… 小鱼:别整没用的,就你那点小心思,我还能不知道. 小屌丝:… 小屌丝:鄙视就鄙视,只要能帮我解决问题,我然你鄙视三连! 小鱼:…还可以这样,那你说吧,啥事? 小屌丝:就是…就是… 小鱼:
-
Python实现简单拆分PDF文件的方法
本文实例讲述了Python实现简单拆分PDF文件的方法.分享给大家供大家参考.具体如下: 依赖pyPdf处理PDF文件 切分pdf文件 使用方法: 1)将要切分的文件放在input_dir目录下 2)在configure.txt文件中设置要切分的份数(如要切分4份,则设置part_num=4) 3)执行程序 4)切分后的文件保存在output_dir目录下 5)运行日志写在pp_log.txt中 P.S. 本程序可以批量切割多个pdf文件 from pyPdf import PdfFileWri
-
python实现批量获取指定文件夹下的所有文件的厂商信息
本文实例讲述了python实现批量获取指定文件夹下的所有文件的厂商信息的方法.分享给大家供大家参考.具体如下: 功能代码如下: import os, string, shutil,re import pefile import codecs, sys import wx import struct #输出中打印Unicode字符 #sys.stdout = codecs.lookup('utf-8')[-1](sys.stdout) def addToDict(theDict,PEfile_Pa
-
Python解析并读取PDF文件内容的方法
本文实例讲述了Python解析并读取PDF文件内容的方法.分享给大家供大家参考,具体如下: 一.问题描述 利用python,去读取pdf文本内容. 二.效果 三.运行环境 python2.7 四.需要安装的库 pip install pdfminer 五.实现源代码 代码1(win64) # coding=utf-8 import sys reload(sys) sys.setdefaultencoding('utf-8') import time time1=time.time() impor
-
用python爬虫批量下载pdf的实现
今天遇到一个任务,给一个excel文件,里面有500多个pdf文件的下载链接,需要把这些文件全部下载下来.我知道用python爬虫可以批量下载,不过之前没有接触过.今天下午找了下资料,终于成功搞定,免去了手动下载的烦恼. 由于我搭建的python版本是3.5,我学习了上面列举的参考文献2中的代码,这里的版本为2.7,有些语法已经不适用了.我修正了部分语法,如下: # coding = UTF-8 # 爬取李东风PDF文档,网址:http://www.math.pku.edu.cn/teacher
-
python基于pyppeteer制作PDF文件
Pyppeteer 是什么 介绍 Pyppeteer 之前,有必要先介绍一下 Puppeteer,Puppeteer 是谷歌官方出的一个通过DevTools协议控制headless Chrome的Node库.通过Puppeteer可以直接控制Chrome浏览器模拟大部分用户操作. 所谓Headless Chrome 就是 Chrome 浏览器的无界面形态. 而 Pyppeteer 就是 Puppeteer 的 Python 版本非官方实现,它是一位来自于日本的工程师依据 Puppeteer 的一
-
Python实现批量自动整理文件
为了实现这样的小工具,我们先设想有下面这些功能. 1.可以自定义整理某一个路径下面的所有需要被整理的文件.2.默认情况下,使用文件后缀作为同一种类文件的文件夹名称,有其他想法的小伙伴可自行扩展. 将使用到的python模块导入到代码块中. import os # 文件/文件夹应用操作 import shutil # 移动文件 import logging # 使用日志logging来打印日志 选择好需要整理的原始文件目录. 下面是整理完成后的效果图,根据文件类型对各种文件进行整理. 在代码块中加
-
Python利用PyMuPDF实现PDF文件处理
目录 1.PyMuPDF简介 介绍 功能 2.安装 关于命名fitz的说明 3.使用方法 导入库,查看版本 打开文档 Document的方法和属性 获取元数据 获取目标大纲 页面(Page) PDF操作 1.PyMuPDF简介 介绍 在介绍PyMuPDF之前,先来了解一下MuPDF,从命名形式中就可以看出,PyMuPDF是MuPDF的Python接口形式. MuPDF MuPDF 是一个轻量级的 PDF.XPS和电子书查看器.MuPDF 由软件库.命令行工具和各种平台的查看器组成. MuPDF