Java使用selenium爬取b站动态的实现方式
目录
- selenium
- mac安装chromedriver
- 完整代码
- maven依赖
- 完整代码
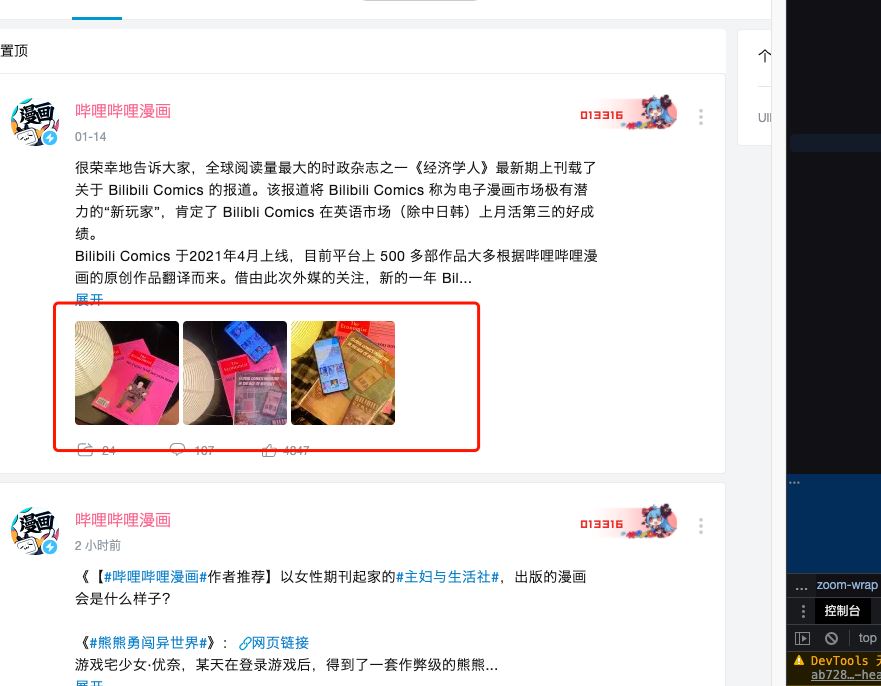
目标:爬取b站用户的动态里面的图片,示例动态
如下所示,我们需要获取这些图片
如图所示,哔哩哔哩漫画的数据是动态请求获取的
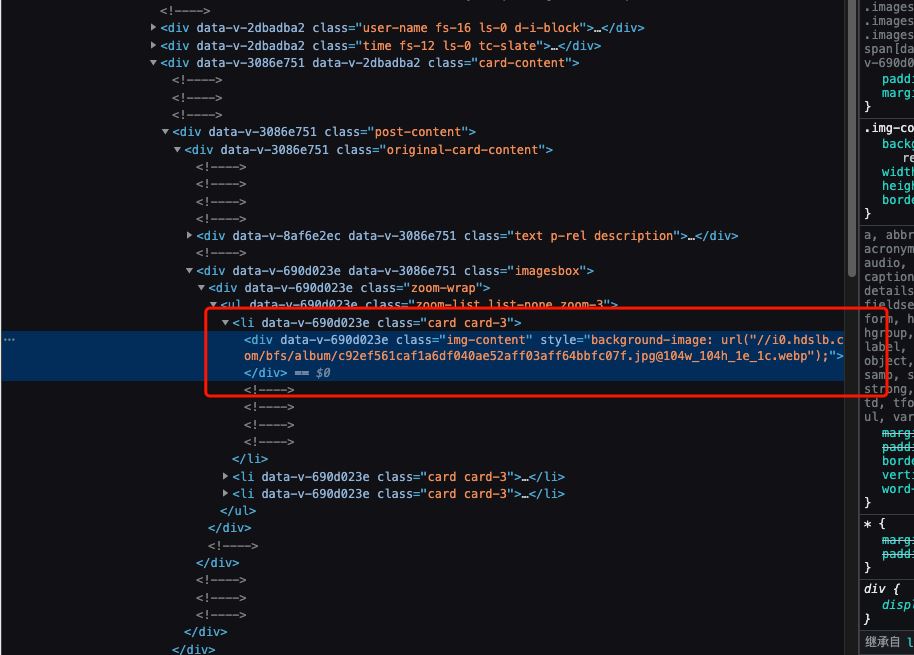
这里我们使用selenium来爬取数据
selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。
这里我使用chrome浏览器,所以驱动就选用chromedriver
mac安装chromedriver
使用brew安装
brew install chromedriver
手动安装
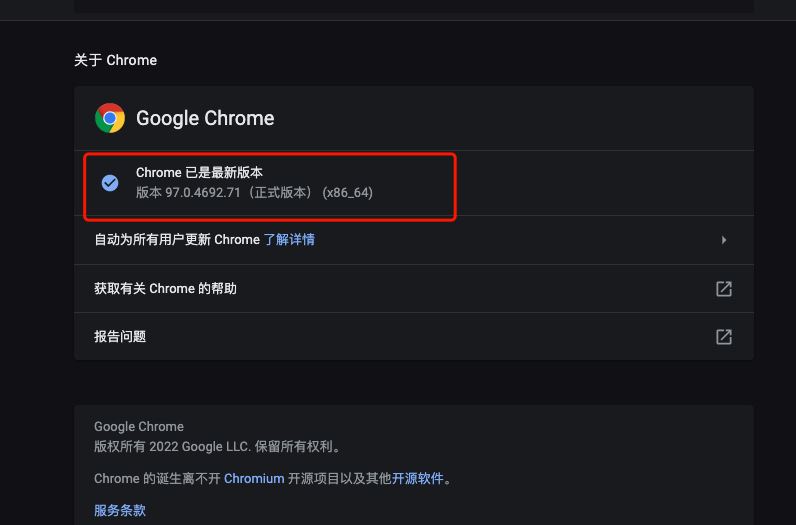
查看电脑上chrome游览器的版本
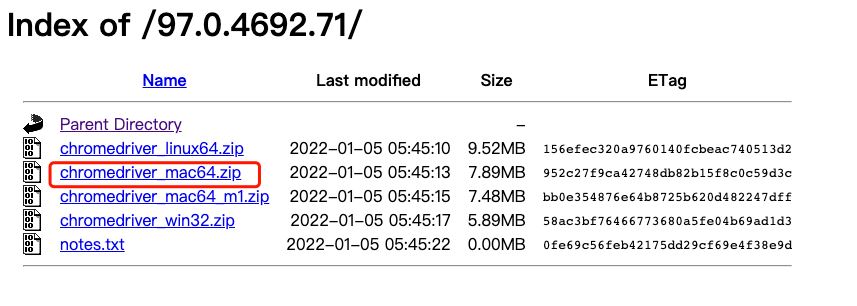
下载对应驱动
选择对应浏览器版本的驱动下载

解压zip文件,放置到对应文件夹
完整代码
这里使用springboot框架
maven依赖
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>
<dependency>
<groupId>com.github.kevinsawicki</groupId>
<artifactId>http-request</artifactId>
<version>6.0</version>
</dependency>
selenium用于解析网页
http-request用于下载图片
完整代码
package com.sun.web_crawler;
import com.github.kevinsawicki.http.HttpRequest;
import org.openqa.selenium.By;
import org.openqa.selenium.JavascriptExecutor;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import java.io.File;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class getPictures3Test {
// https://space.bilibili.com/4099287/dynamic
public static WebDriver getWebDriver(int moudle, String driverPath) {
System.setProperty("webdriver.chrome.driver", driverPath);
HashMap<String, Object> chromePrefs = new HashMap<String, Object>();
chromePrefs.put("profile.managed_default_content_settings.images", 2);
WebDriver driver;
if (moudle == 1)
driver = new ChromeDriver(new ChromeOptions().setHeadless(true).setExperimentalOption("prefs", chromePrefs));
else
driver = new ChromeDriver();
return driver;
}
//将所有链接对应的图片下载到path中,并按照从number开始的顺序编号
public static void downLoad(String path, ArrayList<String> links, int number) throws Exception {
for (String s : links) {
System.out.println("图片:" + s);
HttpRequest hr = HttpRequest.get("https:" + s);
if (hr.ok()) {
File file = new File(path + number + s.substring(s.length() - 4));
hr.receive(file);
number++;
}
}
}
public static void main(String[] args) throws Exception {
//用户uid
String uid = "4099287";
//图片存储位置
String dir = "/Volumes/data/data/b/tako" + File.separator;
//driver位置
String driverPath = "/Volumes/data/env/chromedriver/chromedriver";
//没有图片可以加载时会显示这个
String bottomFlag = "你已经到达了世界的尽头";
//pt2用来匹配一个动态里的图片链接
Pattern pt2 = Pattern.compile("//i0[^@]{50,100}(png|jpg)");
//初始化
WebDriver driver = getWebDriver(1, driverPath);
JavascriptExecutor jse = (JavascriptExecutor) driver;
ArrayList<WebElement> wes = null;
//图片链接links
ArrayList<String> links = new ArrayList<String>();
driver.get("https://space.bilibili.com/" + uid + "/dynamic");
Thread.sleep(3000);
jse.executeScript("window.scrollBy(0," + 4000 + ");");
long time1 = System.currentTimeMillis();
System.out.println("开始爬取页面图片地址!");
int i=1;
int count=0;
while (true) {
System.out.println("向下滚动第"+(i++)+"次!");
//向下滚动
jse.executeScript("window.scrollBy(0," + 800 + 500 * Math.random() + ");");
//如果发现到底了,就退出循环
if (driver.findElement(By.className("div-load-more")).getAttribute("innerHTML").contains(bottomFlag))
break;
wes = (ArrayList<WebElement>) driver.findElements(By.className("original-card-content"));
wes.remove(wes.size() - 1);
//每20个动态获取一次,并删除对应的网页元素(否则会很慢)
if (wes.size() > 20) {
for (WebElement we : wes) {
String innerHtml = we.getAttribute("innerHTML");
Matcher matcher2 = pt2.matcher(innerHtml);
while (matcher2.find()) {
String link = matcher2.group();
if (link.contains("album"))
links.add(link);
System.out.println("记录图片地址数量为:"+ (++count));
}
jse.executeScript("document.getElementsByClassName(\"card\")[0].remove();");
}
}
Thread.sleep(50);
}
Collections.reverse(links);
long time2 = System.currentTimeMillis();
//下载
System.out.println("开始下载图片!");
downLoad(dir, links, 0);
long totalMilliSeconds = time2 - time1;
System.out.println();
long totalSeconds = totalMilliSeconds / 1000;
//求出现在的秒
long currentSecond = totalSeconds % 60;
//求出现在的分
long totalMinutes = totalSeconds / 60;
long currentMinute = totalMinutes % 60;
//求出现在的小时
long totalHour = totalMinutes / 60;
long currentHour = totalHour % 24;
//显示时间
System.out.println("总毫秒为: " + totalMilliSeconds);
System.out.println(currentHour + ":" + currentMinute + ":" + currentSecond + " GMT");
driver.quit();
}
}
开始下载代码时如下:

下载完成后:
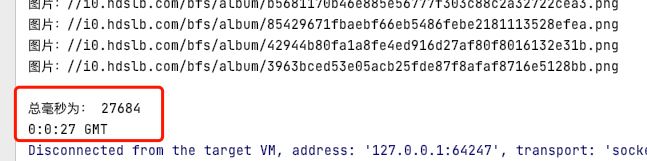
完成后如下:
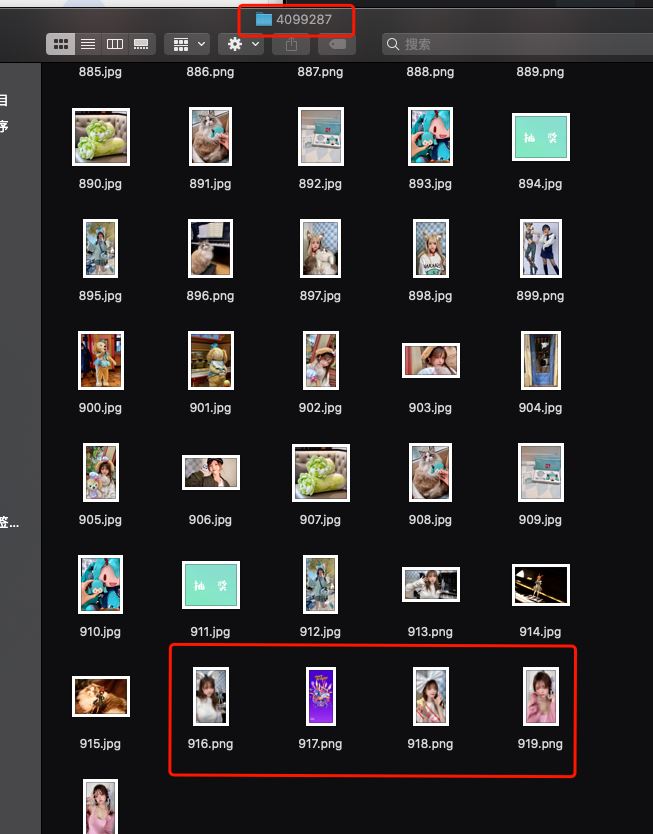
到此这篇关于Java使用selenium爬取b站动态的实现方式的文章就介绍到这了,更多相关Java selenium爬取b站动态内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
java+selenium爬取图片签名的方法
本文实例为大家分享了java+selenium爬取图片签名的具体实现方法,供大家参考,具体内容如下 学习记录: 1.注意 对应的版本非常重要,使用selenium得下载与游览器版本相对应的插件,有火狐和谷歌我用的谷歌,贴下谷歌driver的插件 查看谷歌版本: 2.插件存放路径 3.获取签名图片存放路径 4.Controller代码如下 @ResponseBody @RequestMapping(value = "signatureGenerationv") public String
-

Java使用selenium爬取b站动态的实现方式
目录 selenium mac安装chromedriver 完整代码 maven依赖 完整代码 目标:爬取b站用户的动态里面的图片,示例动态 如下所示,我们需要获取这些图片 如图所示,哔哩哔哩漫画的数据是动态请求获取的 这里我们使用selenium来爬取数据 selenium Selenium是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操作一样. 官网地址 这里我使用chrome浏览器,所以驱动就选用chromedriver mac安装chrome
-
Selenium爬取b站主播头像并以昵称命名保存到本地
申明:资料来源于网络及书本,通过理解.实践.整理成学习笔记. Pythion的Selenium自动化测试之获取哔哩哔哩主播的头像以昵称命名保存到本地文件 效果图 方法1 通过接口获取 首先使用pip下载requests包 pip install requests import requests # 通过接口获取请求的接口:想要获取网页的url url = 'https://api.live.bilibili.com/xlive/web-interface/v1/second/getList?pl
-
Java爬虫实现爬取京东上的手机搜索页面 HttpCliient+Jsoup
1.需求及配置 需求:爬取京东手机搜索页面的信息,记录各手机的名称,价格,评论数等,形成一个可用于实际分析的数据表格. 使用Maven项目,log4j记录日志,日志仅导出到控制台. Maven依赖如下(pom.xml) <dependencies> <dependency> <groupId>org.apache.httpcomponents</groupId> <artifactId>httpclient</artifactId>
-
使用python爬取B站千万级数据
Python(发音:英[?pa?θ?n],美[?pa?θɑ:n]),是一种面向对象.直译式电脑编程语言,也是一种功能强大的通用型语言,已经具有近二十年的发展历史,成熟且稳定.它包含了一组完善而且容易理解的标准库,能够轻松完成很多常见的任务.它的语法非常简捷和清晰,与其它大多数程序设计语言不一样,它使用缩进来定义语句. Python支持命令式程序设计.面向对象程序设计.函数式编程.面向切面编程.泛型编程多种编程范式.与Scheme.Ruby.Perl.Tcl等动态语言一样,Python具备垃圾回收
-
scrapy利用selenium爬取豆瓣阅读的全步骤
首先创建scrapy项目 命令:scrapy startproject douban_read 创建spider 命令:scrapy genspider douban_spider url 网址:https://read.douban.com/charts 关键注释代码中有,若有不足,请多指教 scrapy项目目录结构如下 douban_spider.py文件代码 爬虫文件 import scrapy import re, json from ..items import DoubanReadI
-
python Selenium爬取内容并存储至MySQL数据库的实现代码
前面我通过一篇文章讲述了如何爬取CSDN的博客摘要等信息.通常,在使用Selenium爬虫爬取数据后,需要存储在TXT文本中,但是这是很难进行数据处理和数据分析的.这篇文章主要讲述通过Selenium爬取我的个人博客信息,然后存储在数据库MySQL中,以便对数据进行分析,比如分析哪个时间段发表的博客多.结合WordCloud分析文章的主题.文章阅读量排名等. 这是一篇基础性的文章,希望对您有所帮助,如果文章中出现错误或不足之处,还请海涵.下一篇文章会简单讲解数据分析的过程. 一. 爬取的结果 爬
-
Python进阶之使用selenium爬取淘宝商品信息功能示例
本文实例讲述了Python进阶之使用selenium爬取淘宝商品信息功能.分享给大家供大家参考,具体如下: # encoding=utf-8 __author__ = 'Jonny' __location__ = '西安' __date__ = '2018-05-14' ''' 需要的基本开发库文件: requests,pymongo,pyquery,selenium 开发流程: 搜索关键字:利用selenium驱动浏览器搜索关键字,得到查询后的商品列表 分析页码并翻页:得到商品页码数,模拟翻页
-
java通过Jsoup爬取网页过程详解
这篇文章主要介绍了java通过Jsoup爬取网页过程详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一,导入依赖 <!--java爬虫--> <dependency> <groupId>org.jsoup</groupId> <artifactId>jsoup</artifactId> <version>1.10.3</version> </depe
-
Python使用Selenium爬取淘宝异步加载的数据方法
淘宝的页面很复杂,如果使用分析ajax或者js的方式,很麻烦 抓取淘宝'美食'上面的所有食品信息 spider.py #encoding:utf8 import re from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.common.by import By from selenium.webdriver.support.ui
-
java代理实现爬取代理IP的示例
仅仅使用了一个java文件,运行main方法即可,需要依赖的jar包是com.alibaba.fastjson(版本1.2.28)和Jsoup(版本1.10.2) 如果用了pom,那么就是以下两个: <dependency> <groupId>com.alibaba</groupId> <artifactId>fastjson</artifactId> <version>1.2.28</version> </depe