Python机器学习之PCA降维算法详解
一、算法概述
- 主成分分析 (Principal ComponentAnalysis,PCA)是一种掌握事物主要矛盾的统计分析方法,它可以从多元事物中解析出主要影响因素,揭示事物的本质,简化复杂的问题。
- PCA 是最常用的一种降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中,并期望在所投影的维度上数据的方差最大,以此使用较少的维度,同时保留较多原数据的维度。
- PCA 算法目标是求出样本数据协方差矩阵的特征值和特征向量,而协方差矩阵的特征向量的方向就是PCA需要投影的方向。使样本数据向低维投影后,能尽可能表征原始的数据。
- PCA 可以把具有相关性的高维变量合成为线性无关的低维变量,称为主成分。主成分能够尽可能的保留原始数据的信息。
- PCA 通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等。
二、算法步骤
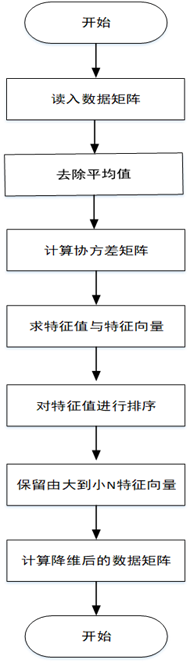
1.将原始数据按行组成m行n列的矩阵X
2.将X的每一列(代表一个属性字段)进行零均值化,即减去这一列的均值
3.求出协方差矩阵
4.求出协方差矩阵的特征值及对应的特征向量r
5.将特征向量按对应特征值大小从左到右按列排列成矩阵,取前k列组成矩阵P
6.计算降维到k维的数据
三、相关概念
方差:描述一个数据的离散程度
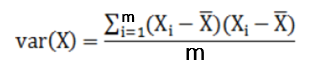
协方差:描述两个数据的相关性,接近1就是正相关,接近-1就是负相关,接近0就是不相关
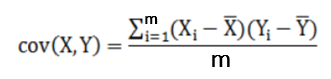
协方差矩阵:协方差矩阵是一个对称的矩阵,而且对角线是各个维度的方差
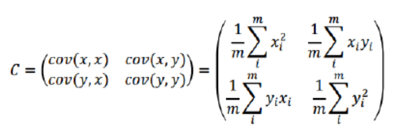
特征值:用于选取降维的K个特征值特征向量:用于选取降维的K个特征向量
四、算法优缺点
优点
- 仅仅需要以方差衡量信息量,不受数据集以外的因素影响。
- 各主成分之间正交,可消除原始数据成分间的相互影响的因素。
- 计算方法简单,主要运算是特征值分解,易于实现。
缺点
- 主成分各个特征维度的含义具有一定的模糊性,不如原始样本特征的解释性强。
- 方差小的非主成分也可能含有对样本差异的重要信息,降维丢弃的数据可能对后续数据处理有影响。
五、算法实现
自定义实现
import numpy as np
# 对初始数据进行零均值化处理
def zeroMean(dataMat):
# 求列均值
meanVal = np.mean(dataMat, axis=0)
# 求列差值
newData = dataMat - meanVal
return newData, meanVal
# 对初始数据进行降维处理
def pca(dataMat, percent=0.19):
newData, meanVal = zeroMean(dataMat)
# 求协方差矩阵
covMat = np.cov(newData, rowvar=0)
# 求特征值和特征向量
eigVals, eigVects = np.linalg.eig(np.mat(covMat))
# 抽取前n个特征向量
n = percentage2n(eigVals, percent)
print("数据降低到:" + str(n) + '维')
# 将特征值按从小到大排序
eigValIndice = np.argsort(eigVals)
# 取最大的n个特征值的下标
n_eigValIndice = eigValIndice[-1:-(n + 1):-1]
# 取最大的n个特征值的特征向量
n_eigVect = eigVects[:, n_eigValIndice]
# 取得降低到n维的数据
lowDataMat = newData * n_eigVect
reconMat = (lowDataMat * n_eigVect.T) + meanVal
return reconMat, lowDataMat, n
# 通过方差百分比确定抽取的特征向量的个数
def percentage2n(eigVals, percentage):
# 按降序排序
sortArray = np.sort(eigVals)[-1::-1]
# 求和
arraySum = sum(sortArray)
tempSum = 0
num = 0
for i in sortArray:
tempSum += i
num += 1
if tempSum >= arraySum * percentage:
return num
if __name__ == '__main__':
# 初始化原始数据(行代表样本,列代表维度)
data = np.random.randint(1, 20, size=(6, 8))
print(data)
# 对数据降维处理
fin = pca(data, 0.9)
mat = fin[1]
print(mat)
利用Sklearn库实现
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.datasets import load_iris
# 加载数据
data = load_iris()
x = data.data
y = data.target
# 设置数据集要降低的维度
pca = PCA(n_components=2)
# 进行数据降维
reduced_x = pca.fit_transform(x)
red_x, red_y = [], []
green_x, green_y = [], []
blue_x, blue_y = [], []
# 对数据集进行分类
for i in range(len(reduced_x)):
if y[i] == 0:
red_x.append(reduced_x[i][0])
red_y.append(reduced_x[i][1])
elif y[i] == 1:
green_x.append(reduced_x[i][0])
green_y.append(reduced_x[i][1])
else:
blue_x.append(reduced_x[i][0])
blue_y.append(reduced_x[i][1])
plt.scatter(red_x, red_y, c='r', marker='x')
plt.scatter(green_x, green_y, c='g', marker='D')
plt.scatter(blue_x, blue_y, c='b', marker='.')
plt.show()
六、算法优化
PCA是一种线性特征提取算法,通过计算将一组特征按重要性从小到大重新排列得到一组互不相关的新特征,但该算法在构造子集的过程中采用等权重的方式,忽略了不同属性对分类的贡献是不同的。
KPCA算法
KPCA是一种改进的PCA非线性降维算法,它利用核函数的思想,把样本数据进行非线性变换,然后在变换空间进行PCA,这样就实现了非线性PCA。
局部PCA算法
局部PCA是一种改进的PCA局部降维算法,它在寻找主成分时加入一项具有局部光滑性的正则项,从而使主成分保留更多的局部性信息。
到此这篇关于Python机器学习之PCA降维算法详解的文章就介绍到这了,更多相关Python PCA降维算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python实现PCA降维的示例详解
概述 本文主要介绍一种降维方法,PCA(Principal Component Analysis,主成分分析).降维致力于解决三类问题. 1. 降维可以缓解维度灾难问题: 2. 降维可以在压缩数据的同时让信息损失最小化: 3. 理解几百个维度的数据结构很困难,两三个维度的数据通过可视化更容易理解. PCA简介 在理解特征提取与处理时,涉及高维特征向量的问题往往容易陷入维度灾难.随着数据集维度的增加,算法学习需要的样本数量呈指数级增加.有些应用中,遇到这样的大数据是非常不利的,而且从大数据集中学习
-
利用Python库Scapy解析pcap文件的方法
每次写博客都是源于纳闷,python解析pcap这么常用的例子网上竟然没有,全是一堆命令行执行的python,能用吗?玩呢? pip安装scapy,然后解析pcap: import scapy from scapy.all import * from scapy.utils import PcapReader packets=rdpcap("./test.pcap") for data in packets: if 'UDP' in data: s = repr(data) print
-
使用PYTHON解析Wireshark的PCAP文件方法
PYTHON首先要安装scapy模块 PY3的安装scapy-python3,使用PIP安装就好了,注意,PY3无法使用pyinstaller打包文件,PY2正常 PY2的安装scapy,比较麻烦 from scapy.all import * pcaps = rdpcap("file.pcap") pcaps便是解析后的类似结构体的东西了 <pre name="code" class="python">packet=pcaps[0]
-
在Python中使用K-Means聚类和PCA主成分分析进行图像压缩
在Python中使用K-Means聚类和PCA主成分分析进行图像压缩 各位读者好,在这片文章中我们尝试使用sklearn库比较k-means聚类算法和主成分分析(PCA)在图像压缩上的实现和结果. 压缩图像的效果通过占用的减少比例以及和原始图像的差异大小来评估. 图像压缩的目的是在保持与原始图像的相似性的同时,使图像占用的空间尽可能地减小,这由图像的差异百分比表示. 图像压缩需要几个Python库,如下所示: # image processing from PIL import Image fr
-
python 抓包保存为pcap文件并解析的实例
首先是抓包,使用scapy模块, sniff()函数 在其中参数为本地文件路径时,操作为打开本地文件 若参数为BPF过滤规则和回调函数,则进行Sniff,回调函数用于对Sniff到的数据包进行处理 import os from scapy.all import * pkts=[] count=0 pcapnum=0 filename='' def test_dump_file(dump_file): print "Testing the dump file..." if os.path
-
利用python-pypcap抓取带VLAN标签的数据包方法
1.背景介绍 在采用通常的socket抓包方式下,操作系统会自动将收到包的VLAN信息剥离,导致上层应用收到的包不会含有VLAN标签信息.而libpcap虽然是基于socket实现抓包,但在收到数据包后,会进一步恢复出剥离的VLAN信息,能够满足需要抓取带VLAN标签信息的数据包的需求场景. python-pypcap包是对libpcap库的python语言封装,本文主要介绍如果利用python-pypcap在网络接口抓取带VLAN标签的数据包. 2.环境准备 libpcap-0.9.4 pyt
-
python 读取修改pcap包的例子
思路 利用scapy库,在这个库的基础下能够做很多的事情,python读取pcap包网上一找一大把 将读取出来的pcap包改一个名字,然后写回,这不就OK了吗 写回的函数是:scapy.wrpcap('filename',list) 第一个参数是filename,第二个参数是一个list,保存报文的list 样例代码 #coding=utf8 import scapy.all as scapy from scapy.layers import http import random #p就是一堆数
-
Python sklearn库实现PCA教程(以鸢尾花分类为例)
PCA简介 主成分分析(Principal Component Analysis,PCA)是最常用的一种降维方法,通常用于高维数据集的探索与可视化,还可以用作数据压缩和预处理等.矩阵的主成分就是其协方差矩阵对应的特征向量,按照对应的特征值大小进行排序,最大的特征值就是第一主成分,其次是第二主成分,以此类推. 基本步骤: 具体实现 我们通过Python的sklearn库来实现鸢尾花数据进行降维,数据本身是4维的降维后变成2维,可以在平面中画出样本点的分布.样本数据结构如下图: 其中样本总数为150
-

Python使用三种方法实现PCA算法
主成分分析,即Principal Component Analysis(PCA),是多元统计中的重要内容,也广泛应用于机器学习和其它领域.它的主要作用是对高维数据进行降维.PCA把原先的n个特征用数目更少的k个特征取代,新特征是旧特征的线性组合,这些线性组合最大化样本方差,尽量使新的k个特征互不相关.关于PCA的更多介绍,请参考:https://en.wikipedia.org/wiki/Principal_component_analysis. 主成分分析(PCA) vs 多元判别式分析(MD
-
在Python中使用swapCase()方法转换大小写的教程
swapCase()方法返回所有可大小写,基于字符大小写交换字符串的一个副本. 语法 以下是swapCase()方法的语法: str.swapcase(); 参数 NA 返回值 此方法返回其中所有基于大小写字符交换字符串的一个副本. 例子 下面的例子显示的swapCase()方法的使用. #!/usr/bin/python str = "this is string example....wow!!!"; print str.swapcase(); str = "THIS I