pytorch实现线性回归以及多元回归
本文实例为大家分享了pytorch实现线性回归以及多元回归的具体代码,供大家参考,具体内容如下
最近在学习pytorch,现在把学习的代码放在这里,下面是github链接
直接附上github代码
# 实现一个线性回归
# 所有的层结构和损失函数都来自于 torch.nn
# torch.optim 是一个实现各种优化算法的包,调用的时候必须是需要优化的参数传入,这些参数都必须是Variable
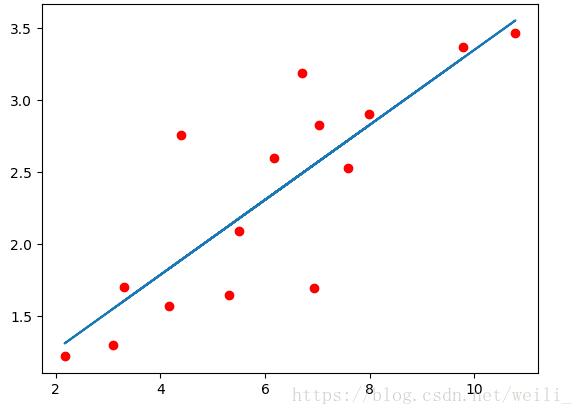
x_train = np.array([[3.3],[4.4],[5.5],[6.71],[6.93],[4.168],[9.779],[6.182],[7.59],[2.167],[7.042],[10.791],[5.313],[7.997],[3.1]],dtype=np.float32)
y_train = np.array([[1.7],[2.76],[2.09],[3.19],[1.694],[1.573],[3.366],[2.596],[2.53],[1.221],[2.827],[3.465],[1.65],[2.904],[1.3]],dtype=np.float32)
# 首先我们需要将array转化成tensor,因为pytorch处理的单元是Tensor
x_train = torch.from_numpy(x_train)
y_train = torch.from_numpy(y_train)
# def a simple network
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression,self).__init__()
self.linear = nn.Linear(1, 1) # input and output is 2_dimension
def forward(self, x):
out = self.linear(x)
return out
if torch.cuda.is_available():
model = LinearRegression().cuda()
#model = model.cuda()
else:
model = LinearRegression()
#model = model.cuda()
# 定义loss function 和 optimize func
criterion = nn.MSELoss() # 均方误差作为优化函数
optimizer = torch.optim.SGD(model.parameters(),lr=1e-3)
num_epochs = 30000
for epoch in range(num_epochs):
if torch.cuda.is_available():
inputs = Variable(x_train).cuda()
outputs = Variable(y_train).cuda()
else:
inputs = Variable(x_train)
outputs = Variable(y_train)
# forward
out = model(inputs)
loss = criterion(out,outputs)
# backword
optimizer.zero_grad() # 每次做反向传播之前都要进行归零梯度。不然梯度会累加在一起,造成不收敛的结果
loss.backward()
optimizer.step()
if (epoch +1)%20==0:
print('Epoch[{}/{}], loss: {:.6f}'.format(epoch+1,num_epochs,loss.data))
model.eval() # 将模型变成测试模式
predict = model(Variable(x_train).cuda())
predict = predict.data.cpu().numpy()
plt.plot(x_train.numpy(),y_train.numpy(),'ro',label = 'original data')
plt.plot(x_train.numpy(),predict,label = 'Fitting line')
plt.show()
结果如图所示:
多元回归:
# _*_encoding=utf-8_*_
# pytorch 里面最基本的操作对象是Tensor,pytorch 的tensor可以和numpy的ndarray相互转化。
# 实现一个线性回归
# 所有的层结构和损失函数都来自于 torch.nn
# torch.optim 是一个实现各种优化算法的包,调用的时候必须是需要优化的参数传入,这些参数都必须是Variable
# 实现 y = b + w1 *x + w2 *x**2 +w3*x**3
import os
os.environ['CUDA_DEVICE_ORDER']="PCI_BUS_ID"
os.environ['CUDA_VISIBLE_DEVICES']='0'
import torch
import numpy as np
from torch.autograd import Variable
import matplotlib.pyplot as plt
from torch import nn
# pre_processing
def make_feature(x):
x = x.unsqueeze(1) # unsquenze 是为了添加维度1的,0表示第一维度,1表示第二维度,将tensor大小由3变为(3,1)
return torch.cat([x ** i for i in range(1, 4)], 1)
# 定义好真实的数据
def f(x):
W_output = torch.Tensor([0.5, 3, 2.4]).unsqueeze(1)
b_output = torch.Tensor([0.9])
return x.mm(W_output)+b_output[0] # 外积,矩阵乘法
# 批量处理数据
def get_batch(batch_size =32):
random = torch.randn(batch_size)
x = make_feature(random)
y = f(x)
if torch.cuda.is_available():
return Variable(x).cuda(),Variable(y).cuda()
else:
return Variable(x),Variable(y)
# def model
class poly_model(nn.Module):
def __init__(self):
super(poly_model,self).__init__()
self.poly = nn.Linear(3,1)
def forward(self,input):
output = self.poly(input)
return output
if torch.cuda.is_available():
print("sdf")
model = poly_model().cuda()
else:
model = poly_model()
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3)
epoch = 0
while True:
batch_x, batch_y = get_batch()
#print(batch_x)
output = model(batch_x)
loss = criterion(output,batch_y)
print_loss = loss.data
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch = epoch +1
if print_loss < 1e-3:
print(print_loss)
break
model.eval()
print("Epoch = {}".format(epoch))
batch_x, batch_y = get_batch()
predict = model(batch_x)
a = predict - batch_y
y = torch.sum(a)
print('y = ',y)
predict = predict.data.cpu().numpy()
plt.plot(batch_x.cpu().numpy(),batch_y.cpu().numpy(),'ro',label = 'Original data')
plt.plot(batch_x.cpu().numpy(),predict,'b', ls='--',label = 'Fitting line')
plt.show()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
pytorch使用Variable实现线性回归
本文实例为大家分享了pytorch使用Variable实现线性回归的具体代码,供大家参考,具体内容如下 一.手动计算梯度实现线性回归 #导入相关包 import torch as t import matplotlib.pyplot as plt #构造数据 def get_fake_data(batch_size = 8): #设置随机种子数,这样每次生成的随机数都是一样的 t.manual_seed(10) #产生随机数据:y = 2*x+3,加上了一些噪声 x = t.rand(batch
-

使用pytorch实现线性回归
本文实例为大家分享了pytorch实现线性回归的具体代码,供大家参考,具体内容如下 线性回归都是包括以下几个步骤:定义模型.选择损失函数.选择优化函数. 训练数据.测试 import torch import matplotlib.pyplot as plt # 构建数据集 x_data= torch.Tensor([[1.0],[2.0],[3.0],[4.0],[5.0],[6.0]]) y_data= torch.Tensor([[2.0],[4.0],[6.0],[8.0],[10.0]
-
PyTorch线性回归和逻辑回归实战示例
线性回归实战 使用PyTorch定义线性回归模型一般分以下几步: 1.设计网络架构 2.构建损失函数(loss)和优化器(optimizer) 3.训练(包括前馈(forward).反向传播(backward).更新模型参数(update)) #author:yuquanle #data:2018.2.5 #Study of LinearRegression use PyTorch import torch from torch.autograd import Variable # train
-
pytorch实现线性回归
pytorch实现线性回归代码练习实例,供大家参考,具体内容如下 欢迎大家指正,希望可以通过小的练习提升对于pytorch的掌握 # 随机初始化一个二维数据集,使用朋友torch训练一个回归模型 import numpy as np import random import matplotlib.pyplot as plt x = np.arange(20) y = np.array([5*x[i] + random.randint(1,20) for i in range(len(x))])
-
PyTorch搭建一维线性回归模型(二)
PyTorch基础入门二:PyTorch搭建一维线性回归模型 1)一维线性回归模型的理论基础 给定数据集,线性回归希望能够优化出一个好的函数,使得能够和尽可能接近. 如何才能学习到参数和呢?很简单,只需要确定如何衡量与之间的差别,我们一般通过损失函数(Loss Funciton)来衡量:.取平方是因为距离有正有负,我们于是将它们变为全是正的.这就是著名的均方误差.我们要做的事情就是希望能够找到和,使得: 均方差误差非常直观,也有着很好的几何意义,对应了常用的欧式距离.现在要求解这个连续函数的最小
-
利用Pytorch实现简单的线性回归算法
最近听了张江老师的深度学习课程,用Pytorch实现神经网络预测,之前做Titanic生存率预测的时候稍微了解过Tensorflow,听说Tensorflow能做的Pyorch都可以做,而且更方便快捷,自己尝试了一下代码的逻辑确实比较简单. Pytorch涉及的基本数据类型是tensor(张量)和Autograd(自动微分变量),对于这些概念我也是一知半解,tensor和向量,矩阵等概念都有交叉的部分,下次有时间好好补一下数学的基础知识,不过现阶段的任务主要是应用,学习掌握思维和方法即可,就不再
-
pytorch实现线性回归以及多元回归
本文实例为大家分享了pytorch实现线性回归以及多元回归的具体代码,供大家参考,具体内容如下 最近在学习pytorch,现在把学习的代码放在这里,下面是github链接 直接附上github代码 # 实现一个线性回归 # 所有的层结构和损失函数都来自于 torch.nn # torch.optim 是一个实现各种优化算法的包,调用的时候必须是需要优化的参数传入,这些参数都必须是Variable x_train = np.array([[3.3],[4.4],[5.5],[6.71],[6.93
-
PyTorch实现线性回归详细过程
目录 一.实现步骤 1.准备数据 2.设计模型 3.构造损失函数和优化器 4.训练过程 5.结果展示 二.参考文献 一.实现步骤 1.准备数据 x_data = torch.tensor([[1.0],[2.0],[3.0]]) y_data = torch.tensor([[2.0],[4.0],[6.0]]) 2.设计模型 class LinearModel(torch.nn.Module): def __init__(self): super(LinearModel
-
scikit-learn线性回归,多元回归,多项式回归的实现
匹萨的直径与价格的数据 %matplotlib inline import matplotlib.pyplot as plt def runplt(): plt.figure() plt.title(u'diameter-cost curver') plt.xlabel(u'diameter') plt.ylabel(u'cost') plt.axis([0, 25, 0, 25]) plt.grid(True) return plt plt = runplt() X = [[6], [8],
-
Pytorch反向传播中的细节-计算梯度时的默认累加操作
Pytorch反向传播计算梯度默认累加 今天学习pytorch实现简单的线性回归,发现了pytorch的反向传播时计算梯度采用的累加机制, 于是百度来一下,好多博客都说了累加机制,但是好多都没有说明这个累加机制到底会有啥影响, 所以我趁着自己练习的一个例子正好直观的看一下以及如何解决: pytorch实现线性回归 先附上试验代码来感受一下: torch.manual_seed(6) lr = 0.01 # 学习率 result = [] # 创建训练数据 x = torch.rand(20, 1
-
pytorch自定义loss损失函数
目录 步骤1:添加自定义的类 步骤2:修改使用的loss函数 自定义loss的方法有很多,但是在博主查资料的时候发现有挺多写法会有问题,靠谱一点的方法是把loss作为一个pytorch的模块, 比如: class CustomLoss(nn.Module): # 注意继承 nn.Module def __init__(self): super(CustomLoss, self).__init__() def forward(self, x, y):