pytorch visdom安装开启及使用方法
安装
conda activate ps pip install visdom
激活ps的环境,在指定的ps环境中安装visdom
开启
python -m visdom.server
浏览器输入红框内的网址
使用
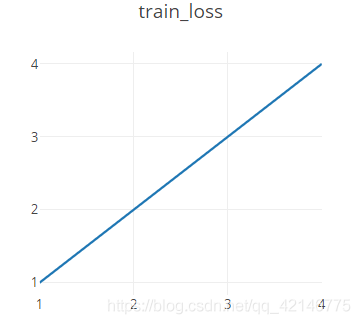
1. 简单示例:一条线
from visdom import Visdom # 创建一个实例 viz=Visdom() # 创建一个直线,再把最新数据添加到直线上 # y x二维两个轴,win 创建一个小窗口,不指定就默认为大窗口,opts其他信息比如名称 viz.line([1,2,3,4],[1,2,3,4],win="train_loss",opts=dict(title='train_loss')) # 更一般的情况,因为下面y x数据不存在,只是示例 # append 添加到原来的后面,不然全部覆盖掉 # viz.line([loss.item()],[global_step],win="train_loss",update='append')
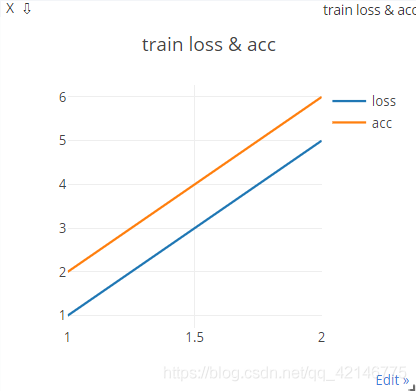
2. 简单示例:2条线
下面主要是[[y1],[y2]],[x] 两条映射,legend就是线条名称
from visdom import Visdom viz=Visdom() viz.line([[1,2],[5,6]],[1,2],win="loss_acc",opts=dict(title='train loss & acc',legend=['loss','acc']))
3. 显示图片
from visdom import Visdom viz=Visdom() # data 是一个batch viz.image(data.view(-1,1,28,28),win='x') viz.text(str(pred.datach().cpu().numpy()),win='pred',opts=dict(title='pred'))
4. 手写数字示例
动画效果图如下

import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from visdom import Visdom
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
viz = Visdom()
viz.line([0.], [0.], win='train_loss', opts=dict(title='train loss'))
viz.line([[0.0, 0.0]], [0.], win='test', opts=dict(title='test loss&acc.',
legend=['loss', 'acc.']))
global_step = 0
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
global_step += 1
viz.line([loss.item()], [global_step], win='train_loss', update='append')
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.argmax(dim=1)
correct += pred.eq(target).float().sum().item()
viz.line([[test_loss, correct / len(test_loader.dataset)]],
[global_step], win='test', update='append')
viz.images(data.view(-1, 1, 28, 28), win='x')
viz.text(str(pred.detach().cpu().numpy()), win='pred',
opts=dict(title='pred'))
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
到此这篇关于pytorch visdom安装开启及使用方法的文章就介绍到这了,更多相关pytorch visdom使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pytorch显存一直变大的解决方案
在代码中添加以下两行可以解决: torch.backends.cudnn.enabled = True torch.backends.cudnn.benchmark = True 补充:pytorch训练过程显存一直增加的问题 之前遇到了爆显存的问题,卡了很久,试了很多方法,总算解决了. 总结下自己试过的几种方法: **1. 使用torch.cuda.empty_cache() 在每一个训练epoch后都添加这一行代码,可以让训练从较低显存的地方开始,但并不适用爆显存的问题,随着epoch的增加
-

使用pytorch实现线性回归
本文实例为大家分享了pytorch实现线性回归的具体代码,供大家参考,具体内容如下 线性回归都是包括以下几个步骤:定义模型.选择损失函数.选择优化函数. 训练数据.测试 import torch import matplotlib.pyplot as plt # 构建数据集 x_data= torch.Tensor([[1.0],[2.0],[3.0],[4.0],[5.0],[6.0]]) y_data= torch.Tensor([[2.0],[4.0],[6.0],[8.0],[10.0]
-
浅谈pytorch中的nn.Sequential(*net[3: 5])是啥意思
看到代码里面有这个 1 class ResNeXt101(nn.Module): 2 def __init__(self): 3 super(ResNeXt101, self).__init__() 4 net = resnext101() # print(os.getcwd(), net) 5 net = list(net.children()) # net.children()得到resneXt 的表层网络 # for i, value in enumerate(net): # print(
-
PyTorch的Debug指南
一.ipdb 介绍 很多初学 python 的同学会使用 print 或 log 调试程序,但是这只在小规模的程序下调试很方便,更好的调试应该是在一边运行的时候一边检查里面的变量和方法. 感兴趣的可以去了解 pycharm 的 debug 模式,功能也很强大,能够满足一般的需求,这里不多做赘述,我们这里介绍一个更适用于 pytorch 的一个灵活的 pdb 交互式调试工具. Pdb 是一个交互式的调试工具,集成与 Python 标准库中,它能让你根据需求跳转到任意的 Python 代码断点.查看
-
Python深度学习之使用Pytorch搭建ShuffleNetv2
一.model.py 1.1 Channel Shuffle def channel_shuffle(x: Tensor, groups: int) -> Tensor: batch_size, num_channels, height, width = x.size() channels_per_group = num_channels // groups # reshape # [batch_size, num_channels, height, width] -> [batch_size
-
win10系统配置GPU版本Pytorch的详细教程
一.安装cuda 1.在英伟达官网下载最新版的cuda驱动 https://developer.nvidia.com/zh-cn/cuda-downloads 都选上就行了,然后一路默认安装 输入nvcc -V查看是否安装成功 二.安装pycuda 1.在控制台中输入pip install pycuda 安装pycuda 2.在环境变量中添加cl.exe 3.测试pycuda是否正常运行 import pycuda.driver as drv import pycuda.tools,pycuda
-
PyTorch两种安装方法
本文安装的是pytorch1.4版本(cpu版本) 首先需要安装Anaconda 是否需要安装基于cuda的PyTorch版本呢? 对于普通笔记本来说即使有显卡性能也不高,跑不动层数较深的深度学习网络,所以就不用装cuda啦.实际应用时深度学习肯定离不开基于高性能GPU的cuda,作为一般的笔记本,基本都跑不动数据量较大的模型,所以安装CPU版的PyTorch即可.以后如果继续进行深度学习的研究或开发,都会基于高性能服务器,此时安装PyTorch版本肯定是选择有cuda的版本了. 然后进入PyT
-
在Windows下安装配置CPU版的PyTorch的方法
由于我已经安装了anaconda,所以不在赘述,下载可以上清华镜像版下载 https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/ 我下的版本为Anaconda3-5.2.0-Windows-x86_64 对应python版本为3.6.5 版本根据个人需求下载即可.下面开始具体的PyTorch的cpu版本安装. 1.添加镜像源 还是使用清华源下载,打开cmd或者 anaconda prompt,输入以下代码: conda config --ad
-
pytorch中的nn.ZeroPad2d()零填充函数实例详解
在卷积神经网络中,有使用设置padding的参数,配合卷积步长,可以使得卷积后的特征图尺寸大小不发生改变,那么在手动实现图片或特征图的边界零填充时,常用的函数是nn.ZeroPad2d(),可以指定tensor的四个方向上的填充,比如左边添加1dim.右边添加2dim.上边添加3dim.下边添加4dim,即指定paddin参数为(1,2,3,4),本文中代码设置的是(3,4,5,6)如下: import torch.nn as nn import cv2 import torchvision f
-
pytorch实现线性回归以及多元回归
本文实例为大家分享了pytorch实现线性回归以及多元回归的具体代码,供大家参考,具体内容如下 最近在学习pytorch,现在把学习的代码放在这里,下面是github链接 直接附上github代码 # 实现一个线性回归 # 所有的层结构和损失函数都来自于 torch.nn # torch.optim 是一个实现各种优化算法的包,调用的时候必须是需要优化的参数传入,这些参数都必须是Variable x_train = np.array([[3.3],[4.4],[5.5],[6.71],[6.93
-
Pytorch 使用tensor特定条件判断索引
torch.where() 用于将两个broadcastable的tensor组合成新的tensor,类似于c++中的三元操作符"?:" 区别于python numpy中的where()直接可以找到特定条件元素的index 想要实现numpy中where()的功能,可以借助nonzero() 对应numpy中的where()操作效果: 补充:Pytorch torch.Tensor.detach()方法的用法及修改指定模块权重的方法 detach detach的中文意思是分离,官方解释
-
PyTorch CUDA环境配置及安装的步骤(图文教程)
Pytorch版本介绍 torch:1.6 CUDA:10.2 cuDNN:8.1.0 ✨安装 NVIDIA 显卡驱动程序 一般 电脑出厂/装完系统 会自动安装显卡驱动 如果有 可直接进行下一步 下载链接 http://www.nvidia.cn/Download/index.aspx?lang=cn 选择和自己显卡相匹配的显卡驱动 下载安装 ✨确认项目所需torch版本 # pip install -r requirements.txt # base ---------------------