Python爬虫之必备chardet库
一、chardet库的安装与介绍
玩儿过爬虫的朋友应该知道,在爬取不同的网页时,返回结果会出现乱码的情况。比如,在爬取某个中文网页的时候,有的页面使用GBK/GB2312,有的使用UTF8,如果你需要去爬一些页面,知道网页编码很重要的。
虽然HTML页面有charset标签,但是有些时候是不对的,那么chardet就能帮我们大忙了。使用 chardet 可以很方便的实现字符串/文件的编码检测。
如果你安装过Anaconda,那么可以直接使用chardet库。如果你只是安装了Python的话,就需要使用下面几行代码,完成chardet库的安装。
pip install chardet
接着,使用下面这行代码,导入chardet库。
import chardet
二、chardet库的使用
这个小节,我们分3部分讲解。
2.1 chardet.detect()函数
detect()函数接受一个参数,一个非unicode字符串。它返回一个字典,其中包含自动检测到的字符编码和从0到1的可信度级别。
- encoding:表示字符编码方式。
- confidence:表示可信度。
- language:语言。
光看这个解释,大多数朋友可能看不懂,下面我们就用例子来讲述这个函数。
2.2 使用该函数分别检测gbk、utf-8和日语
检测gbk编码的中文:
str1 = '大家好,我是黄同学'.encode('gbk')
chardet.detect(str1)
chardet.detect(str1)["encoding"]
结果如下:

检测的编码是GB2312,注意到GBK是GB2312的父集,两者是同一种编码,检测正确的概率是99%,language字段指出的语言是'Chinese'。
检测utf-8编码的中文:
str2 = '我有一个梦想'.encode('utf-8')
chardet.detect(str2)
chardet.detect(str2)["encoding"]
结果如下:

检测一段日文:
str3 = 'ありがとう'.encode('euc-jp')
chardet.detect(str3)
chardet.detect(str3)
结果如下:

2.3 如何在“爬虫”中使用chardet库呢?
我们以百度网页为例子,进行讲述。

这个网页的源代码,使用的是什么编码呢?我们看看源代码:

从图中可以看到,是utf-8字符编码。
如果不使用chardet库,获取网页源代码的时候,怎么指定字符编码呢?
import chardet
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
response = requests.get('https://www.baidu.com',headers=headers)
response.encoding = "utf-8"
response.text
结果如下:

你会发现:正确指定编码后,没有乱码。如果你将编码改为gbk,再看看结果。此时已经乱码。
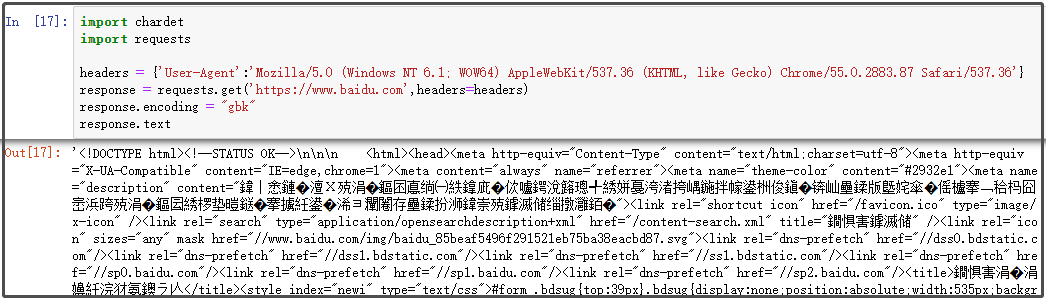
如果使用chardet库,获取网页源代码的时候,可以轻松指定字符编码!
import chardet
import requests
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36'}
response = requests.get('https://www.baidu.com',headers=headers)
# 注意下面这行代码,是怎么写的?
response.encoding = chardet.detect(response.content)['encoding']
response.text
结果如下:

编码不用我们自己查找,也不用猜,直接交给chardet库去猜测,正确率还高。
到此这篇关于Python爬虫之必备chardet库的文章就介绍到这了,更多相关Python chardet库内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python爬虫开发之使用Python爬虫库requests多线程抓取猫眼电影TOP100实例
使用Python爬虫库requests多线程抓取猫眼电影TOP100思路: 查看网页源代码 抓取单页内容 正则表达式提取信息 猫眼TOP100所有信息写入文件 多线程抓取 运行平台:windows Python版本:Python 3.7. IDE:Sublime Text 浏览器:Chrome浏览器 1.查看猫眼电影TOP100网页原代码 按F12查看网页源代码发现每一个电影的信息都在"<dd></dd>"标签之中. 点开之后,信息如下: 2.抓取单页内容 在浏
-

Python爬虫之爬取某文库文档数据
一.基本开发环境 Python 3.6 Pycharm 二.相关模块的使用 import os import requests import time import re import json from docx import Document from docx.shared import Cm 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.目标网页分析 网站的文档内容,都是以图片形式存在的.它有自己的数据接口 接口链接: https://openapi.book11
-
Python爬虫爬取爱奇艺电影片库首页的实例代码
上篇文章给大家介绍了Python爬取爱奇艺电影信息代码实例 感兴趣的朋友点击查看下. 今天给大家介绍Python爬虫爬取爱奇艺电影片库首页,下面是实例代码,参考下: import time import traceback import requests from lxml import etree import re from bs4 import BeautifulSoup from lxml.html.diff import end_tag import json import pymys
-
python爬虫请求库httpx和parsel解析库的使用测评
Python网络爬虫领域两个最新的比较火的工具莫过于httpx和parsel了.httpx号称下一代的新一代的网络请求库,不仅支持requests库的所有操作,还能发送异步请求,为编写异步爬虫提供了便利.parsel最初集成在著名Python爬虫框架Scrapy中,后独立出来成立一个单独的模块,支持XPath选择器, CSS选择器和正则表达式等多种解析提取方式, 据说相比于BeautifulSoup,parsel的解析效率更高. 今天我们就以爬取链家网上的二手房在售房产信息为例,来测评下http
-
Python爬虫进阶之Beautiful Soup库详解
一.Beautiful Soup库简介 BeautifulSoup4 是一个 HTML/XML 的解析器,主要的功能是解析和提取 HTML/XML 的数据.和 lxml 库一样. lxml 只会局部遍历,而 BeautifulSoup4 是基于 HTML DOM 的,会加载整个文档,解析 整个 DOM 树,因此内存开销比较大,性能比较低. BeautifulSoup4 用来解析 HTML 比较简单,API 使用非常人性化,支持 CSS 选择器,是 Python 标准库中的 HTML 解析器,也支
-
小众实用的Python 爬虫库RoboBrowser
1. 前言 大家好,我是安果! 今天推荐一款小众轻量级的爬虫库:RoboBrowser RoboBrowser,Your friendly neighborhood web scraper!由纯 Python 编写,运行无需独立的浏览器,它不仅可以做爬虫,还可以实现 Web 端的自动化 项目地址: https://github.com/jmcarp/robobrowser 2. 安装及用法 在实战之前,我们先安装依赖库及解析器 PS:官方推荐的解析器是 「lxml」 # 安装依赖 pip3 i
-
Python基于httpx模块实现发送请求
一.httpx模块是什么? 一个用于http请求的模块,类似于requests.aiohttp: 既能发送同步请求(是指在单进程单线程的代码中,发起一次请求后,在收到返回结果之前,不能发起下一次请求),又能发送异步请求(是指在单进程单线程的代码中,发起一次请求后,在等待网站返回结果的时间里,可以继续发送更多请求). 二.httpx模块基础使用 2.1 httpx模块安装 pip install httpx 2.2 httpx模块基础使用 import httpx res = httpx.get(
-
详解Python之Scrapy爬虫教程NBA球员数据存放到Mysql数据库
获取要爬取的URL 爬虫前期工作 用Pycharm打开项目开始写爬虫文件 字段文件items # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class NbaprojectItem(scrapy.Item): # define the fields for yo
-
python爬虫利器之requests库的用法(超全面的爬取网页案例)
requests库 利用pip安装: pip install requests 基本请求 req = requests.get("https://www.baidu.com/") req = requests.post("https://www.baidu.com/") req = requests.put("https://www.baidu.com/") req = requests.delete("https://www.baid
-
Python爬虫爬取全球疫情数据并存储到mysql数据库的步骤
思路:使用Python爬虫对腾讯疫情网站世界疫情数据进行爬取,封装成一个函数返回一个 字典数据格式的对象,写另一个方法调用该函数接收返回值,和数据库取得连接后把 数据存储到mysql数据库. 一.mysql数据库建表 CREATE TABLE world( id INT(11) NOT NULL AUTO_INCREMENT, dt DATETIME NOT NULL COMMENT '日期', c_name VARCHAR(35) DEFAULT NULL COMMENT '国家'
-
python爬虫开发之使用python爬虫库requests,urllib与今日头条搜索功能爬取搜索内容实例
使用python爬虫库requests,urllib爬取今日头条街拍美图 代码均有注释 import re,json,requests,os from hashlib import md5 from urllib.parse import urlencode from requests.exceptions import RequestException from bs4 import BeautifulSoup from multiprocessing import Pool #请求索引页 d