Python爬虫之线程池的使用
一、前言
学到现在,我们可以说已经学习了爬虫的基础知识,如果没有那些奇奇怪怪的反爬虫机制,基本上只要有时间分析,一般的数据都是可以爬取的,那么到了这个时候我们需要考虑的就是爬取的效率了,关于提高爬虫效率,也就是实现异步爬虫,我们可以考虑以下两种方式:一是线程池的使用(也就是实现单进程下的多线程),一是协程的使用(如果没有记错,我所使用的协程模块是从python3.4以后引入的,我写博客时使用的python版本是3.9)。
今天我们先来讲讲线程池。
二、同步代码演示
我们先用普通的同步的形式写一段代码
import time
def func(url):
print("正在下载:", url)
time.sleep(2)
print("下载完成:", url)
if __name__ == '__main__':
start = time.time() # 开始时间
url_list = [
"a", "b", "c"
]
for url in url_list:
func(url)
end = time.time() # 结束时间
print(end - start)
对于代码运行的结果我们心里都有数,但还是让我们来看一下吧

不出所料。运行时间果然是六秒
三、异步,线程池代码
那么如果我们使用线程池运行上述代码又会怎样呢?
import time
from multiprocessing import Pool
def func(url):
print("正在下载:", url)
time.sleep(2)
print("下载完成:", url)
if __name__ == '__main__':
start = time.time() # 开始时间
url_list = [
"a", "b", "c"
]
pool = Pool(len(url_list)) # 实例化一个线程池对象,并且设定线程池的上限数量为列表长度。不设置上限也可以。
pool.map(func, url_list)
end = time.time() # 结束时间
print(end - start)
下面就是见证奇迹的时候了,让我们运行程序
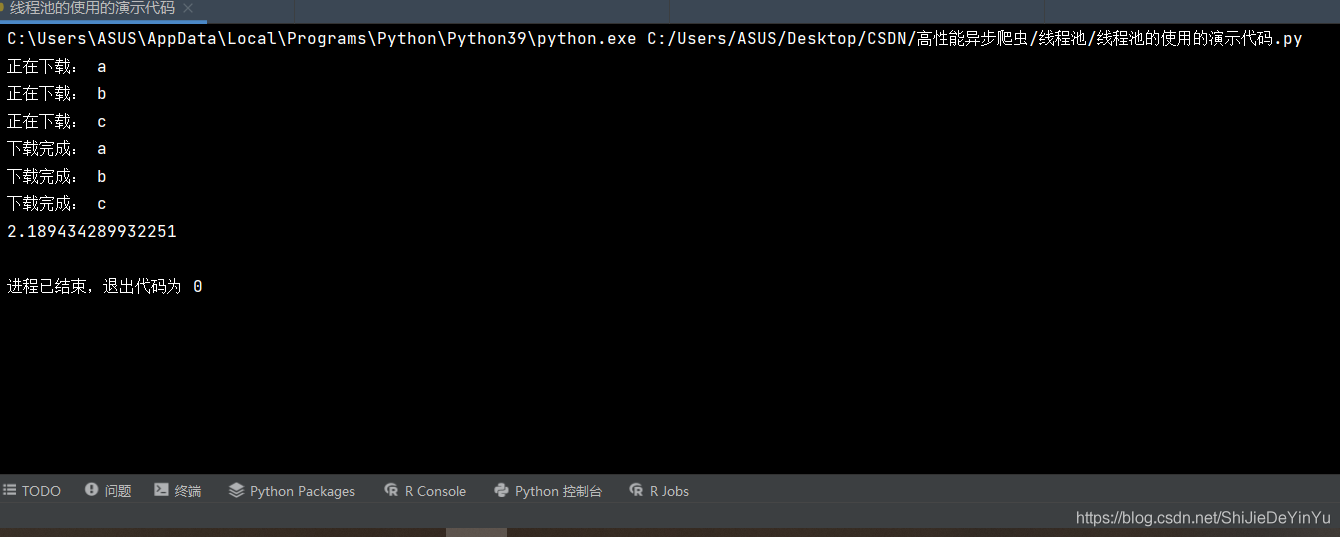
我们发现这次我们的运行时间只用2~3秒。其实我们可以将线程池简单的理解为将多个任务同时进行。
注意:
1.我使用的是 pycharm,如果使用的是 VS 或者说是 python 自带的 idle,在运行时我们只能看到最后时间的输出。
2.我们输出结果可能并不是按 abc 的顺序输出的。
四、同步爬虫爬取图片
因为我们的重点是线程池的爬取效率提高,我们就简单的爬取一页的图片。
import requests
import time
import os
from lxml import etree
def save_photo(url, title):
# UA伪装
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
# 发送请求
photo = requests.get(url=url, headers=header).content
# 创建路径,避免重复下载
if not os.path.exists("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能异步爬虫\\线程池\\同步爬虫爬取4K美女图片\\" + title + ".jpg"):
with open("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能异步爬虫\\线程池\\同步爬虫爬取4K美女图片\\" + title + ".jpg", "wb") as fp:
print(title, "开始下载!!!")
fp.write(photo)
print(title, "下载完成!!!")
if __name__ == '__main__':
start = time.time()
# 创建文件夹
if not os.path.exists("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能异步爬虫\\线程池\\同步爬虫爬取4K美女图片"):
os.mkdir("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能异步爬虫\\线程池\\同步爬虫爬取4K美女图片")
# UA伪装
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
# 指定url
url = "https://pic.netbian.com/4kmeinv/"
# 发送请求,获取源码
page = requests.get(url = url, headers = header).text
# xpath 解析,获取图片的下载地址的列表
tree = etree.HTML(page)
url_list = tree.xpath('//*[@id="main"]/div[3]/ul/li/a/@href')
# 通过下载地址获取高清图片的地址和图片名称
for href in url_list:
new_url = "https://pic.netbian.com" + href
# 再一次发送请求
page = requests.get(url = new_url, headers = header).text
# 再一次 xpath 解析
new_tree = etree.HTML(page)
src = "https://pic.netbian.com" + new_tree.xpath('//*[@id="img"]/img/@src')[0]
title = new_tree.xpath('//*[@id="img"]/img/@title')[0].split(" ")[0]
# 编译文字
title = title.encode("iso-8859-1").decode("gbk")
# 下载,保存
save_photo(src, title)
end = time.time()
print(end - start)
让我们看看同步爬虫需要多长时间
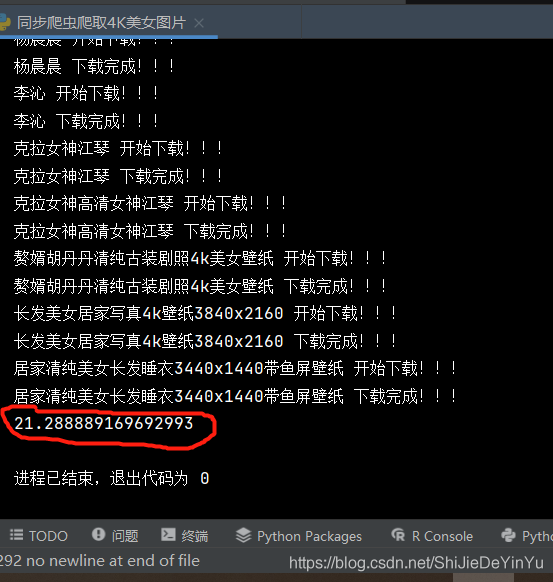
然后再让我们看看使用线程池的异步爬虫爬取这些图片需要多久
五、使用线程池的异步爬虫爬取4K美女图片
import requests
import time
import os
from lxml import etree
from multiprocessing import Pool
def save_photo(src_title):
# UA伪装
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
# 发送请求
url = src_title[0]
title = src_title[1]
photo = requests.get(url=url, headers=header).content
# 创建路径,避免重复下载
if not os.path.exists("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能异步爬虫\\线程池\\异步爬虫爬取4K美女图片\\" + title + ".jpg"):
with open("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能异步爬虫\\线程池\\异步爬虫爬取4K美女图片\\" + title + ".jpg", "wb") as fp:
print(title, "开始下载!!!")
fp.write(photo)
print(title, "下载完成!!!")
if __name__ == '__main__':
start = time.time()
# 创建文件夹
if not os.path.exists("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能异步爬虫\\线程池\\异步爬虫爬取4K美女图片"):
os.mkdir("C:\\Users\\ASUS\\Desktop\\CSDN\\高性能异步爬虫\\线程池\\异步爬虫爬取4K美女图片")
# UA伪装
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"
}
# 指定url
url = "https://pic.netbian.com/4kmeinv/"
# 发送请求,获取源码
page = requests.get(url = url, headers = header).text
# xpath 解析,获取图片的下载地址的列表
tree = etree.HTML(page)
url_list = tree.xpath('//*[@id="main"]/div[3]/ul/li/a/@href')
# 存储最后的网址和标题的列表
src_list = []
title_list = []
# 通过下载地址获取高清图片的地址和图片名称
for href in url_list:
new_url = "https://pic.netbian.com" + href
# 再一次发送请求
page = requests.get(url = new_url, headers = header).text
# 再一次 xpath 解析
new_tree = etree.HTML(page)
src = "https://pic.netbian.com" + new_tree.xpath('//*[@id="img"]/img/@src')[0]
src_list.append(src)
title = new_tree.xpath('//*[@id="img"]/img/@title')[0].split(" ")[0]
# 编译文字
title = title.encode("iso-8859-1").decode("gbk")
title_list.append(title)
# 下载,保存。使用线程池
pool = Pool()
src_title = zip(src_list, title_list)
pool.map(save_photo, list(src_title))
end = time.time()
print(end - start)
让我们来看看运行的结果
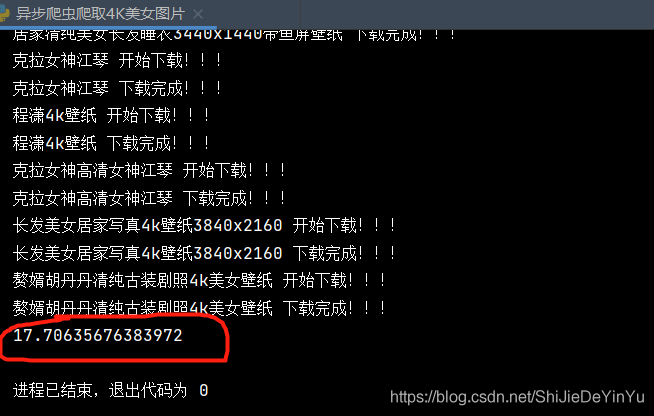
只用了 17 秒,可不要小瞧这几秒,如果数据太大,这些差距后来就会更大了。
注意
不过我们必须要明白 线程池 是有上限的,这就是说数据太大,线程池的效率也会降低,所以这就要用到协程模块了。
到此这篇关于Python爬虫之线程池的使用的文章就介绍到这了,更多相关Python线程池的使用内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python Event事件、进程池与线程池、协程解析
Event事件 用来控制线程的执行 出现e.wait(),就会把这个线程设置为False,就不能执行这个任务: 只要有一个线程出现e.set(),就会告诉Event对象,把有e.wait的用户全部改为True,剩余的任务就会立马去执行.由一些线程去控制另一些线程,中间通过Event. from threading import Event from threading import Thread import time # 调用Event实例化出对象 e = Event() # # # 若该方法
-
python线程池 ThreadPoolExecutor 的用法示例
前言 从Python3.2开始,标准库为我们提供了 concurrent.futures 模块,它提供了 ThreadPoolExecutor (线程池)和ProcessPoolExecutor (进程池)两个类. 相比 threading 等模块,该模块通过 submit 返回的是一个 future 对象,它是一个未来可期的对象,通过它可以获悉线程的状态主线程(或进程)中可以获取某一个线程(进程)执行的状态或者某一个任务执行的状态及返回值: 主线程可以获取某一个线程(或者任务的)的状态,以及返
-
python爬虫线程池案例详解(梨视频短视频爬取)
python爬虫-梨视频短视频爬取(线程池) 示例代码 import requests from lxml import etree import random from multiprocessing.dummy import Pool # 多进程要传的方法,多进程pool.map()传的第二个参数是一个迭代器对象 # 而传的get_video方法也要有一个迭代器参数 def get_video(dic): headers = { 'User-Agent':'Mozilla/5.0 (Wind
-

Python mutiprocessing多线程池pool操作示例
本文实例讲述了Python mutiprocessing多线程池pool操作.分享给大家供大家参考,具体如下: python - mutiprocessing 多线程 pool 脚本代码: root@72132server:~/python/multiprocess# ls multiprocess_pool.py multprocess.py root@72132server:~/python/multiprocess# cat multiprocess_pool.py #!/usr/bin/
-
python爬虫 线程池创建并获取文件代码实例
本实例主要进行线程池创建,多线程获取.存储视频文件 梨视频:利用线程池进行视频爬取 #爬取梨视频数据 import requests import re from lxml import etree from multiprocessing.dummy import Pool import random # 定义获取视频数据方法 def getVideoData(url): # url为列表中的视频url return requests.get(url=url,headers=headers).
-
python爬虫之线程池和进程池功能与用法详解
本文实例讲述了python爬虫之线程池和进程池功能与用法.分享给大家供大家参考,具体如下: 一.需求 最近准备爬取某电商网站的数据,先不考虑代理.分布式,先说效率问题(当然你要是请求的太快就会被封掉,亲测,400个请求过去,服务器直接拒绝连接,心碎),步入正题.一般情况下小白的我们第一个想到的是for循环,这个可是单线程啊.那我们考虑for循环直接开他个5个线程,问题来了,如果有一个url请求还没有回来,后面的就干等,这么用多线程等于没用,到处贴创可贴. 二.性能考虑 确定要用多线程或者多进程了
-
php与python实现的线程池多线程爬虫功能示例
本文实例讲述了php与python实现的线程池多线程爬虫功能.分享给大家供大家参考,具体如下: 多线程爬虫可以用于抓取内容了这个可以提升性能了,这里我们来看php与python 线程池多线程爬虫的例子,代码如下: php例子 <?php class Connect extends Worker //worker模式 { public function __construct() { } public function getConnection() { if (!self::$ch) { sel
-
Python 线程池用法简单示例
本文实例讲述了Python 线程池用法.分享给大家供大家参考,具体如下: # -*- coding:utf-8 -*- #! python3 ''' Created on 2019-10-2 @author: Administrator ''' from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor import os,time,random def task(n): print('%s is runing' %
-
Python爬虫之线程池的使用
一.前言 学到现在,我们可以说已经学习了爬虫的基础知识,如果没有那些奇奇怪怪的反爬虫机制,基本上只要有时间分析,一般的数据都是可以爬取的,那么到了这个时候我们需要考虑的就是爬取的效率了,关于提高爬虫效率,也就是实现异步爬虫,我们可以考虑以下两种方式:一是线程池的使用(也就是实现单进程下的多线程),一是协程的使用(如果没有记错,我所使用的协程模块是从python3.4以后引入的,我写博客时使用的python版本是3.9). 今天我们先来讲讲线程池. 二.同步代码演示 我们先用普通的同步的形式写一段
-
用python实现的线程池实例代码
python3标准库里自带线程池ThreadPoolExecutor和进程池ProcessPoolExecutor. 如果你用的是python2,那可以下载一个模块,叫threadpool,这是线程池.对于进程池可以使用python自带的multiprocessing.Pool. 当然也可以自己写一个threadpool. # coding:utf-8 import Queue import threading import sys import time import math class W
-
python爬虫利用代理池更换IP的方法步骤
0. 前言 周日在爬一个国外网站的时候,发现用协程并发请求,并且请求次数太快的时候,会出现对方把我的服务器IP封掉的情况.于是网上找了一下开源的python代理池,这里选择的是star数比较多的proxy_pool 1. 安装环境 # 安装python虚拟环境, python环境最好为python3.6,再往上的话,安装依赖时会报错 sudo apt update sudo apt install python3.6 pip3 install virtualenv virtualenv venv
-
Python学习之线程池与GIL全局锁详解
目录 线程池 线程池的创建 - concurrent 线程池的常用方法 线程池演示案例 线程锁 利用线程池实现抽奖小案例 GIL全局锁 GIL 的作用 线程池 线程池的创建 - concurrent concurrent 是 Python 的内置包,使用它可以帮助我们完成创建线程池的任务. 方法名 介绍 示例 futures.ThreadPoolExecutor 创建线程池 tpool=ThreadPoolExecutor(max_workers) 通过调用 concurrent 包的 futu
-
python中ThreadPoolExecutor线程池和ProcessPoolExecutor进程池
目录 1.ThreadPoolExecutor多线程 <1>为什么需要线程池呢? <2>标准库concurrent.futures模块 <3>简单使用 <4>as_completed(一次性获取所有的结果) <5>map()方法 <6>wait()方法 2.ProcessPoolExecutor多进程 <1>同步调用方式: 调用,然后等返回值,能解耦,但是速度慢 <2>异步调用方式:只调用,不等返回值,可能存在
-
Python爬虫代理IP池实现方法
在公司做分布式深网爬虫,搭建了一套稳定的代理池服务,为上千个爬虫提供有效的代理,保证各个爬虫拿到的都是对应网站有效的代理IP,从而保证爬虫快速稳定的运行,当然在公司做的东西不能开源出来.不过呢,闲暇时间手痒,所以就想利用一些免费的资源搞一个简单的代理池服务. 1.问题 代理IP从何而来? 刚自学爬虫的时候没有代理IP就去西刺.快代理之类有免费代理的网站去爬,还是有个别代理能用.当然,如果你有更好的代理接口也可以自己接入. 免费代理的采集也很简单,无非就是:访问页面页面 -> 正则/xpath提
-
python线程池threadpool实现篇
本文为大家分享了threadpool线程池中所有的操作,供大家参考,具体内容如下 首先介绍一下自己使用到的名词: 工作线程(worker):创建线程池时,按照指定的线程数量,创建工作线程,等待从任务队列中get任务: 任务(requests):即工作线程处理的任务,任务可能成千上万个,但是工作线程只有少数.任务通过 makeRequests来创建 任务队列(request_queue):存放任务的队列,使用了queue实现的.工作线程从任务队列中get任务进行处理: 任务处理函
-
详解python中的线程与线程池
线程 进程和线程 什么是进程? 进程就是正在运行的程序, 一个任务就是一个进程, 进程的主要工作是管理资源, 而不是实现功能 什么是线程? 线程的主要工作是去实现功能, 比如执行计算. 线程和进程的关系就像员工与老板的关系, 老板(进程) 提供资源 和 工作空间, 员工(线程) 负责去完成相应的任务 特点 一个进程至少由一个线程, 这一个必须存在的线程被称为主线程, 同时一个进程也可以有多个线程, 即多线程 当我们我们遇到一些需要重复执行的代码时, 就可以使用多线程分担一些任务, 进而加快运行速