pytorch 如何打印网络回传梯度
需求:
打印梯度,检查网络学习情况
net = your_network().cuda()
def train():
...
outputs = net(inputs)
loss = criterion(outputs, targets)
loss.backward()
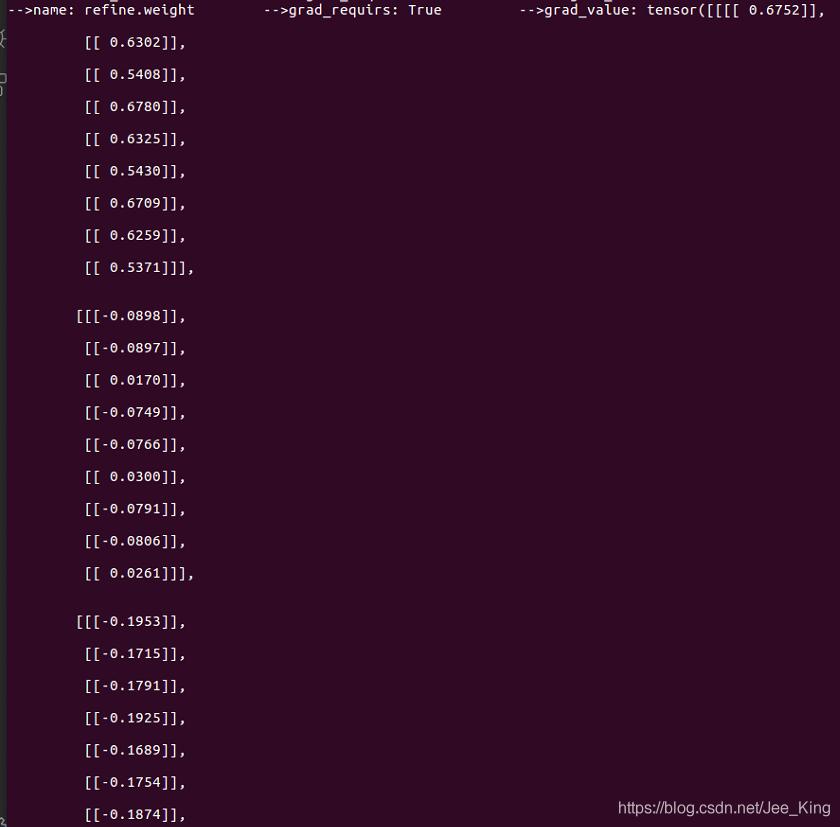
for name, parms in net.named_parameters():
print('-->name:', name, '-->grad_requirs:',parms.requires_grad, \
' -->grad_value:',parms.grad)
...
打印结果如下:
name表示网络参数的名字; parms.requires_grad 表示该参数是否可学习,是不是frozen的; parm.grad 打印该参数的梯度值。
补充:pytorch的梯度计算
看代码吧~
import torch
from torch.autograd import Variable
x = torch.Tensor([[1.,2.,3.],[4.,5.,6.]]) #grad_fn是None
x = Variable(x, requires_grad=True)
y = x + 2
z = y*y*3
out = z.mean()
#x->y->z->out
print(x)
print(y)
print(z)
print(out)
#结果:
tensor([[1., 2., 3.],
[4., 5., 6.]], requires_grad=True)
tensor([[3., 4., 5.],
[6., 7., 8.]], grad_fn=<AddBackward>)
tensor([[ 27., 48., 75.],
[108., 147., 192.]], grad_fn=<MulBackward>)
tensor(99.5000, grad_fn=<MeanBackward1>)
若是关于graph leaves求导的结果变量是一个标量,那么gradient默认为None,或者指定为“torch.Tensor([1.0])”
若是关于graph leaves求导的结果变量是一个向量,那么gradient是不能缺省的,要是和该向量同纬度的tensor
out.backward()
print(x.grad)
#结果:
tensor([[3., 4., 5.],
[6., 7., 8.]])
#如果是z关于x求导就必须指定gradient参数:
gradients = torch.Tensor([[2.,1.,1.],[1.,1.,1.]])
z.backward(gradient=gradients)
#若z不是一个标量,那么就先构造一个标量的值:L = torch.sum(z*gradient),再关于L对各个leaf Variable计算梯度
#对x关于L求梯度
x.grad
#结果:
tensor([[36., 24., 30.],
[36., 42., 48.]])
错误情况
z.backward() print(x.grad) #报错:RuntimeError: grad can be implicitly created only for scalar outputs只能为标量创建隐式变量 x1 = Variable(torch.Tensor([[1.,2.,3.],[4.,5.,6.]])) x2 = Variable(torch.arange(4).view(2,2).type(torch.float), requires_grad=True) c = x2.mm(x1) c.backward(torch.ones_like(c)) # c.backward() #RuntimeError: grad can be implicitly created only for scalar outputs print(x2.grad)
从上面的例子中,out是常量,可以默认创建隐变量,如果反向传播的不是常量,要知道该矩阵的具体值,在网络中就是loss矩阵,方向传播的过程中就是拿该归一化的损失乘梯度来更新各神经元的参数。
看到一个博客这样说:loss = criterion(outputs, labels)对应loss += (label[k] - h) * (label[k] - h) / 2
就是求loss(其实我觉得这一步不用也可以,反向传播时用不到loss值,只是为了让我们知道当前的loss是多少)
我认为一定是要求loss的具体值,才能对比阈值进行分类,通过非线性激活函数,判断是否激活。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Pytorch实现将模型的所有参数的梯度清0
有两种方式直接把模型的参数梯度设成0: model.zero_grad() optimizer.zero_grad()#当optimizer=optim.Optimizer(model.parameters())时,两者等效 如果想要把某一Variable的梯度置为0,只需用以下语句: Variable.grad.data.zero_() 补充知识:PyTorch中在反向传播前为什么要手动将梯度清零?optimizer.zero_grad()的意义 optimizer.zero_grad()意思
-
在pytorch中实现只让指定变量向后传播梯度
pytorch中如何只让指定变量向后传播梯度? (或者说如何让指定变量不参与后向传播?) 有以下公式,假如要让L对xvar求导: (1)中,L对xvar的求导将同时计算out1部分和out2部分: (2)中,L对xvar的求导只计算out2部分,因为out1的requires_grad=False: (3)中,L对xvar的求导只计算out1部分,因为out2的requires_grad=False: 验证如下: #!/usr/bin/env python2 # -*- coding: utf-
-
Pytorch中的自动求梯度机制和Variable类实例
自动求导机制是每一个深度学习框架中重要的性质,免去了手动计算导数,下面用代码介绍并举例说明Pytorch的自动求导机制. 首先介绍Variable,Variable是对Tensor的一个封装,操作和Tensor是一样的,但是每个Variable都有三个属性:Varibale的Tensor本身的.data,对应Tensor的梯度.grad,以及这个Variable是通过什么方式得到的.grad_fn,根据最新消息,在pytorch0.4更新后,torch和torch.autograd.Variab
-

pytorch损失反向传播后梯度为none的问题
错误代码:输出grad为none a = torch.ones((2, 2), requires_grad=True).to(device) b = a.sum() b.backward() print(a.grad) 由于.to(device)是一次操作,此时的a已经不是叶子节点了 修改后的代码为: a = torch.ones((2, 2), requires_grad=True) c = a.to(device) b = c.sum() b.backward() print(a.grad)
-
pytorch 禁止/允许计算局部梯度的操作
一.禁止计算局部梯度 torch.autogard.no_grad: 禁用梯度计算的上下文管理器. 当确定不会调用Tensor.backward()计算梯度时,设置禁止计算梯度会减少内存消耗.如果需要计算梯度设置Tensor.requires_grad=True 两种禁用方法: 将不用计算梯度的变量放在with torch.no_grad()里 >>> x = torch.tensor([1.], requires_grad=True) >>> with torch.n
-
pytorch 如何打印网络回传梯度
需求: 打印梯度,检查网络学习情况 net = your_network().cuda() def train(): ... outputs = net(inputs) loss = criterion(outputs, targets) loss.backward() for name, parms in net.named_parameters(): print('-->name:', name, '-->grad_requirs:',parms.requires_grad, \ ' --
-
详解利用Pytorch实现ResNet网络
目录 正文 评估模型 训练 ResNet50 模型 正文 每个 batch 前清空梯度,否则会将不同 batch 的梯度累加在一块,导致模型参数错误. 然后我们将输入和目标张量都移动到所需的设备上,并将模型的梯度设置为零.我们调用model(inputs)来计算模型的输出,并使用损失函数(在此处为交叉熵)来计算输出和目标之间的误差.然后我们通过调用loss.backward()来计算梯度,最后调用optimizer.step()来更新模型的参数. 在训练过程中,我们还计算了准确率和平均损失.我们
-
pytorch 实现打印模型的参数值
对于简单的网络 例如全连接层Linear 可以使用以下方法打印linear层: fc = nn.Linear(3, 5) params = list(fc.named_parameters()) print(params.__len__()) print(params[0]) print(params[1]) 输出如下: 由于Linear默认是偏置bias的,所有参数列表的长度是2.第一个存的是全连接矩阵,第二个存的是偏置. 对于稍微复杂的网络 例如MLP mlp = nn.Sequential
-
pytorch教程之网络的构建流程笔记
目录 构建网络 定义一个网络 loss Function Backprop 更新权值 参考网址 构建网络 我们可以通过torch.nn包来构建网络,现在你已经看过了autograd,nn在autograd的基础上定义模型和求微分.一个nn.Module包括很多层,forward方法返回output. 一个典型的训练过程包括这么几步: 1.定义一个网络结构包含一些可训练的额参数 2.为数据集制定输入iterata 3.通过网络计算Output 4.计算loss 5.反向传播计算梯度 6.更新权值
-
pytorch 实现查看网络中的参数
可以通过model.state_dict()或者model.named_parameters()函数查看现在的全部可训练参数(包括通过继承得到的父类中的参数) 可示例代码如下: params = list(model.named_parameters()) (name, param) = params[28] print(name) print(param.grad) print('-------------------------------------------------') (name
-
Pytorch自定义CNN网络实现猫狗分类详解过程
目录 前言 一. 数据预处理 二. 定义网络 三. 训练模型 前言 数据集下载地址: 链接: https://pan.baidu.com/s/17aglKyKFvMvcug0xrOqJdQ?pwd=6i7m Dogs vs. Cats(猫狗大战)来源Kaggle上的一个竞赛题,任务为给定一个数据集,设计一种算法中的猫狗图片进行判别. 数据集包括25000张带标签的训练集图片,猫和狗各125000张,标签都是以cat or dog命名的.图像为RGB格式jpg图片,size不一样.截图如下: 一.
-
使用Pytorch训练two-head网络的操作
之前有写过一篇如何使用Pytorch实现two-head(多输出)模型 在那篇文章里,基本把two-head网络以及构建讲清楚了(如果不清楚请先移步至那一篇博文). 但是我后来发现之前的训练方法貌似有些问题. 以前的训练方法: 之前是把两个head分开进行训练的,因此每一轮训练先要对一个batch的数据进行划分,然后再分别训练两个头.代码如下: f_out_y0, _ = net(x0) _, f_out_y1 = net(x1) #实例化损失函数 criterion0 = Loss() cri