详解Python可视化神器Yellowbrick使用
机器学习中非常重要的一环就是数据的可视化分析,从源数据的可视化到结果数据的可视化都离不开可视化工具的使用,sklearn+matplotlib的组合在日常的工作中已经满足了绝对大多数的需求,今天主要介绍的是一个基于sklearn和matplotlib模块进行扩展的可视化工具Yellowbrick。
Yellowbrick的官方文档在这里。Yellowbrick是由一套被称为"Visualizers"组成的可视化诊断工具组成的套餐,其由Scikit-Learn API延伸而来,对模型选择过程其指导作用。总之,Yellowbrick结合了Scikit-Learn和Matplotlib并且最好得传承了Scikit-Learn文档,对 你的 模型进行可视化!
Yellowbrick主要包含的组件如下:
Visualizers Visualizers也是estimators(从数据中习得的对象),其主要任务是产生可对模型选择过程有更深入了解的视图。从Scikit-Learn来看,当可视化数据空间或者封装一个模型estimator时,其和转换器(transformers)相似,就像"ModelCV" (比如 RidgeCV, LassoCV )的工作原理一样。Yellowbrick的主要目标是创建一个和Scikit-Learn类似的有意义的API。其中最受欢迎的visualizers包括: 特征可视化 Rank Features: 对单个或者两两对应的特征进行排序以检测其相关性 Parallel Coordinates: 对实例进行水平视图 Radial Visualization: 在一个圆形视图中将实例分隔开 PCA Projection: 通过主成分将实例投射 Feature Importances: 基于它们在模型中的表现对特征进行排序 Scatter and Joint Plots: 用选择的特征对其进行可视化 分类可视化 Class Balance: 看类的分布怎样影响模型 Classification Report: 用视图的方式呈现精确率,召回率和F1值 ROC/AUC Curves: 特征曲线和ROC曲线子下的面积 Confusion Matrices: 对分类决定进行视图描述 回归可视化 Prediction Error Plot: 沿着目标区域对模型进行细分 Residuals Plot: 显示训练数据和测试数据中残差的差异 Alpha Selection: 显示不同alpha值选择对正则化的影响 聚类可视化 K-Elbow Plot: 用肘部法则或者其他指标选择k值 Silhouette Plot: 通过对轮廓系数值进行视图来选择k值 文本可视化 Term Frequency: 对词项在语料库中的分布频率进行可视化 t-SNE Corpus Visualization: 用随机邻域嵌入来投射文档
这里以癌症数据集为例绘制ROC曲线,如下:
def testFunc1(savepath='Results/breast_cancer_ROCAUC.png'): ''' 基于癌症数据集的测试 ''' data=load_breast_cancer() X,y=data['data'],data['target'] X_train, X_test, y_train, y_test = train_test_split(X, y) viz=ROCAUC(LogisticRegression()) viz.fit(X_train, y_train) viz.score(X_test, y_test) viz.poof(outpath=savepath)
结果如下:
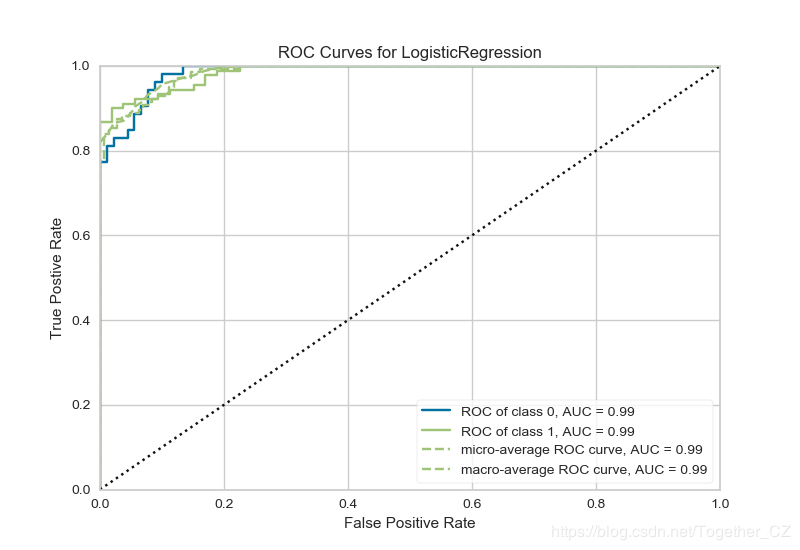
结果看起来也是挺美观的。
之后用平行坐标的方法对高维数据进行作图,数据集同上:
def testFunc2(savepath='Results/breast_cancer_ParallelCoordinates.png'): ''' 用平行坐标的方法对高维数据进行作图 ''' data=load_breast_cancer() X,y=data['data'],data['target'] print 'X_shape: ',X.shape #X_shape: (569L, 30L) visualizer=ParallelCoordinates() visualizer.fit_transform(X,y) visualizer.poof(outpath=savepath)
结果如下:
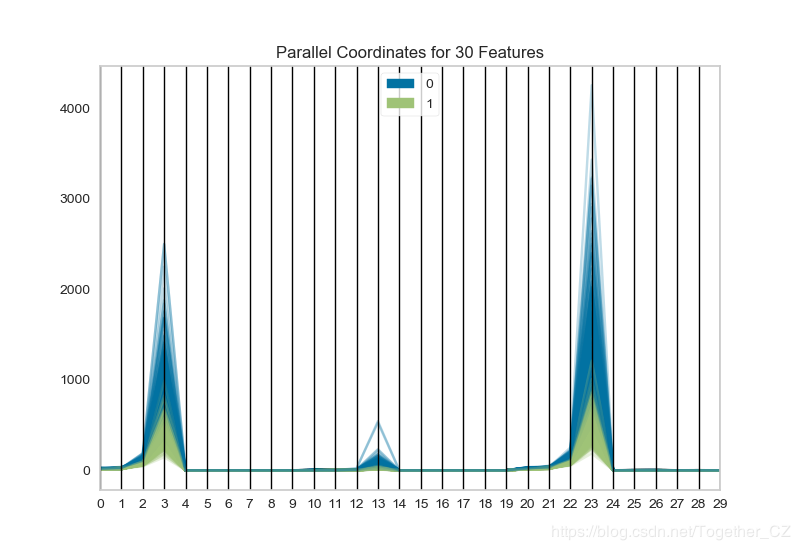
这个最初没有看明白什么意思,其实就是高维特征数据的可视化分析,这个功能还可以对原始数据进行采样,之后再绘图。
基于癌症数据集,使用逻辑回归模型来分类,绘制分类报告
def testFunc3(savepath='Results/breast_cancer_LR_report.png'): ''' 基于癌症数据集,使用逻辑回归模型来分类,绘制分类报告 ''' data=load_breast_cancer() X,y=data['data'],data['target'] model=LogisticRegression() visualizer=ClassificationReport(model) X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3,random_state=42) visualizer.fit(X_train,y_train) visualizer.score(X_test,y_test) visualizer.poof(outpath=savepath)
结果如下:
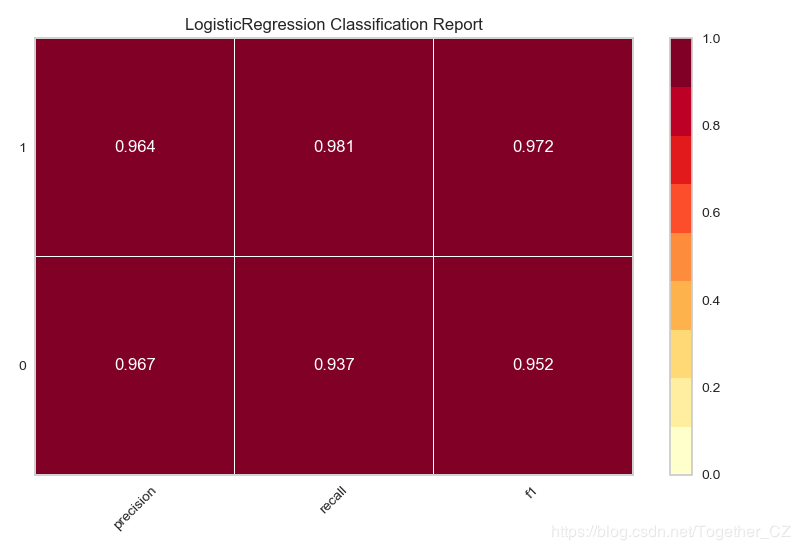
这样的结果展现方式还是比较美观的,在使用的时候发现了这个模块的一个不足的地方,就是:如果连续绘制两幅图片的话,第一幅图片就会累加到第二幅图片中去,多幅图片绘制亦是如此,在matplotlib中可以使用plt.clf()方法来清除上一幅图片,这里没有找到对应的API,希望有找到的朋友告知一下。
接下来基于共享单车数据集进行租借预测,具体如下:
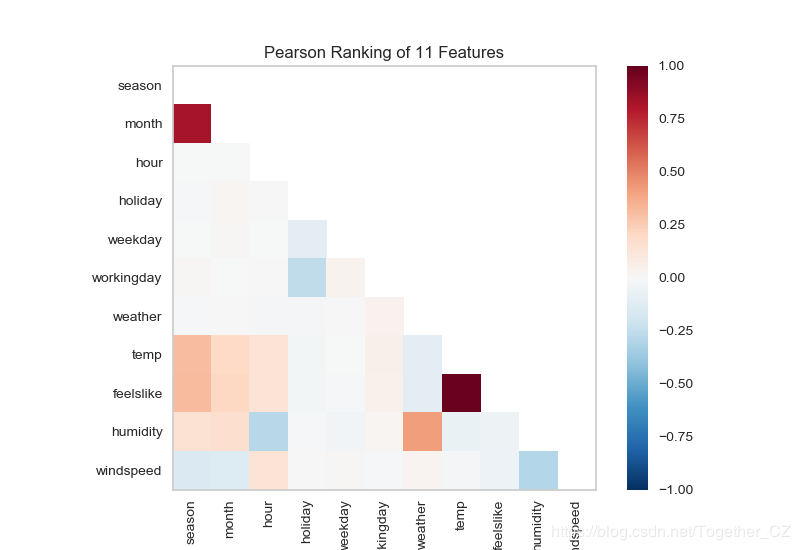
首先基于特征对相似度分析方法来分析共享单车数据集中两两特征之间的相似度
def testFunc5(savepath='Results/bikeshare_Rank2D.png'):
'''
共享单车数据集预测
'''
data=pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"
]]
y=data["riders"]
visualizer=Rank2D(algorithm="pearson")
visualizer.fit_transform(X)
visualizer.poof(outpath=savepath)
基于线性回归模型实现预测分析
def testFunc7(savepath='Results/bikeshare_LinearRegression_ResidualsPlot.png'):
'''
基于共享单车数据使用线性回归模型预测
'''
data = pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"]]
y=data["riders"]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
visualizer=ResidualsPlot(LinearRegression())
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof(outpath=savepath)
结果如下:

基于共享单车数据使用AlphaSelection
def testFunc8(savepath='Results/bikeshare_RidgeCV_AlphaSelection.png'):
'''
基于共享单车数据使用AlphaSelection
'''
data=pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"]]
y=data["riders"]
alphas=np.logspace(-10, 1, 200)
visualizer=AlphaSelection(RidgeCV(alphas=alphas))
visualizer.fit(X, y)
visualizer.poof(outpath=savepath)
结果如下:
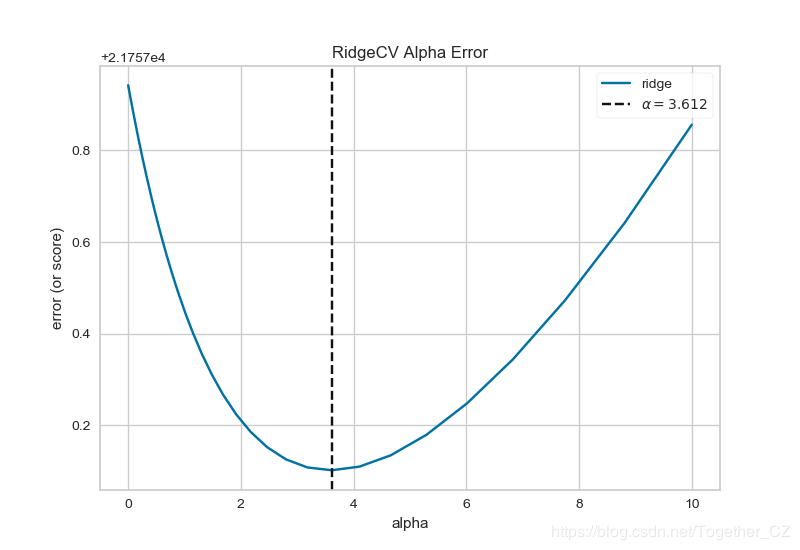
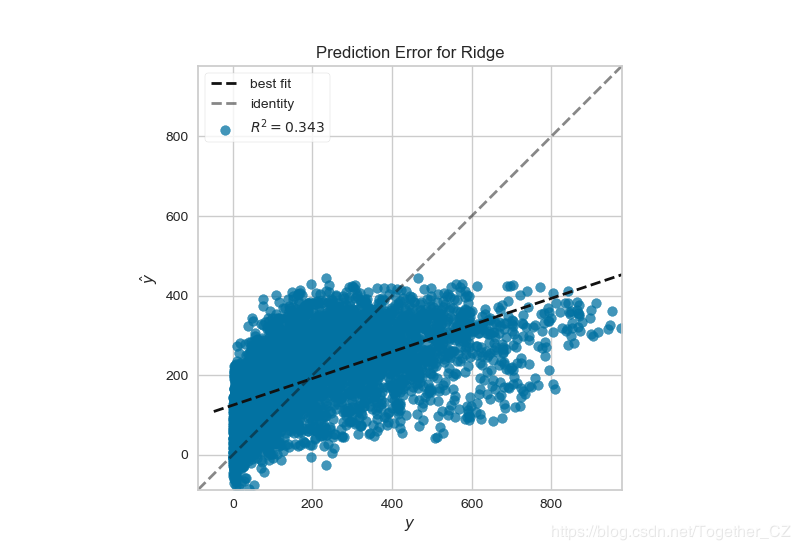
基于共享单车数据绘制预测错误图
def testFunc9(savepath='Results/bikeshare_Ridge_PredictionError.png'):
'''
基于共享单车数据绘制预测错误图
'''
data=pd.read_csv('bikeshare/bikeshare.csv')
X=data[["season", "month", "hour", "holiday", "weekday", "workingday",
"weather", "temp", "feelslike", "humidity", "windspeed"]]
y=data["riders"]
X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.3)
visualizer=PredictionError(Ridge(alpha=3.181))
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof(outpath=savepath)
blog.csdn.net/Together_CZ/article/details/86640784
结果如下:
今天先记录到这里,之后有时间继续更新学习!
总结
以上所述是小编给大家介绍的Python可视化神器Yellowbrick使用,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
Python干货:分享Python绘制六种可视化图表
可视化图表,有相当多种,但常见的也就下面几种,其他比较复杂一点,大都也是基于如下几种进行组合,变换出来的.对于初学者来说,很容易被这官网上众多的图表类型给吓着了,由于种类太多,几种图表的绘制方法很有可能会混淆起来. 因此,在这里,我特地总结了六种常见的基本图表类型,你可以通过对比学习,打下坚实的基础. 01. 折线图 绘制折线图,如果你数据不是很多的话,画出来的图将是曲折状态,但一旦你的数据集大起来,比如下面我们的示例,有100个点,所以我们用肉眼看到的将是一条平滑的曲线. 这里我绘制三条线,只
-

Python的地形三维可视化Matplotlib和gdal使用实例
我是以Python开门的,我还是觉得Python也可以进行地形三维可视化,当然这里需要借助第三方库,so,我就来介绍:Python一个很重要可视化插件,Matplotlib. Matplotlib是Python最著名的绘图库,它提供了一整套友好的命令,十分适合交互式地进行制图.而且也可以方便地将它作为绘图控件,嵌入GUI应用程序中.你会发现Matplotlib和matlab相似,但是你知道matlab强大是很强大,但是安装包就有7G,一下就让我失去玩弄他的兴趣. Matplotlib的二维图形非
-
VTK与Python实现机械臂三维模型可视化详解
三维可视化系统的建立依赖于三维图形平台, 如 OpenGL.VTK.OGRE.OSG等, 传统的方法多采用OpenGL进行底层编程,即对其特有的函数进行定量操作, 需要开发人员熟悉相关函数, 从而造成了开发难度大. 周期长等问题.VTK. ORGE.OSG等平台使用封装更好的函数简化了开发过程.下面将使用Python与VTK进行机器人上位机监控界面的快速原型开发. 完整的上位机程序需要有三维显示模块.机器人信息监测模块(位置/角度/速度/电量/温度/错误信息...).通信模块(串口/USB/WI
-
利用Python代码实现数据可视化的5种方法详解
前言 数据科学家并不逊色于艺术家.他们用数据可视化的方式绘画,试图展现数据内隐藏的模式或表达对数据的见解.更有趣的是,一旦接触到任何可视化的内容.数据时,人类会有更强烈的知觉.认知和交流. 数据可视化是数据科学家工作中的重要组成部分.在项目的早期阶段,你通常会进行探索性数据分析(Exploratory Data Analysis,EDA)以获取对数据的一些理解.创建可视化方法确实有助于使事情变得更加清晰易懂,特别是对于大型.高维数据集.在项目结束时,以清晰.简洁和引人注目的方式展现最终结果是非常
-
Python实现简单层次聚类算法以及可视化
本文实例为大家分享了Python实现简单层次聚类算法,以及可视化,供大家参考,具体内容如下 基本的算法思路就是:把当前组间距离最小的两组合并成一组. 算法的差异在算法如何确定组件的距离,一般有最大距离,最小距离,平均距离,马氏距离等等. 代码如下: import numpy as np import data_helper np.random.seed(1) def get_raw_data(n): _data=np.random.rand(n,2) #生成数据的格式是n个(x,y) _grou
-
Python数据可视化库seaborn的使用总结
seaborn是python中的一个非常强大的数据可视化库,它集成了matplotlib,下图为seaborn的官网,如果遇到疑惑的地方可以到官网查看.http://seaborn.pydata.org/ 从官网的主页我们就可以看出,seaborn在数据可视化上真的非常强大. 1.首先我们还是需要先引入库,不过这次要用到的python库比较多. import numpy as np import pandas as pd import matplotlib as mpl import matpl
-
详解Python可视化神器Yellowbrick使用
机器学习中非常重要的一环就是数据的可视化分析,从源数据的可视化到结果数据的可视化都离不开可视化工具的使用,sklearn+matplotlib的组合在日常的工作中已经满足了绝对大多数的需求,今天主要介绍的是一个基于sklearn和matplotlib模块进行扩展的可视化工具Yellowbrick. Yellowbrick的官方文档在这里.Yellowbrick是由一套被称为"Visualizers"组成的可视化诊断工具组成的套餐,其由Scikit-Learn API延伸而来,对模型选择
-
Python 可视化神器Plotly详解
文 | 潮汐 来源:Python 技术「ID: pythonall」 学习Python是做数分析的最基础的一步,数据分析离不开数据可视化.Python第三方库中我们最常用的可视化库是 pandas,matplotlib,pyecharts, 当然还有 Tableau,另外最近在学习过程中发现另一款可视化神器-Plotly,它是一款用来做数据分析和可视化的在线平台,功能非常强大, 可以在线绘制很多图形比如条形图.散点图.饼图.直方图等等.除此之外,它还支持在线编辑,以及多种语言 python.ja
-
详解python实现可视化的MD5、sha256哈希加密小工具
本文主要介绍了详解python实现可视化的MD5.sha256哈希加密小工具,分享给大家,具体如下: 效果图: 刚启动的状态 输入文本.触发加密按钮后支持复制 超过十条不全量显示 代码 import hashlib import tkinter as tk #窗口控制 windowss=tk.Tk() windowss.title('Python_md5')#窗口title,并非第一行 windowss.geometry('820x550') windowss.resizable(width=T
-
详解Python中四种关系图数据可视化的效果对比
python关系图的可视化主要就是用来分析一堆数据中,每一条数据的节点之间的连接关系从而更好的分析出人物或其他场景中存在的关联关系. 这里使用的是networkx的python非标准库来测试效果展示,通过模拟出一组DataFrame数据实现四种关系图可视化. 其余还包含了pandas的数据分析模块以及matplotlib的画图模块. 若是没有安装这三个相关的非标准库使用pip的方式安装一下即可. pip install pandas -i https://pypi.tuna.tsinghua.e
-
Python可视化神器pyecharts绘制柱状图
目录 主题介绍 图表参数 主题详解 柱状图模板系列 海量数据柱状图动画展示 收入支出柱状图(适用于记账) 三维数据叠加 柱状图与折线图多维展示(同屏展示) 单列多维数据展示 3D柱状图 主题介绍 pyecharts里面有很多的主题可以供我们选择,我们可以根据自己的需要完成主题的配置,这样就告别了软件的限制,可以随意的发挥自己的艺术细胞了. 图表参数 ''' def add_yaxis( # 系列名称,用于 tooltip 的显示,legend 的图例筛选. series_name: str, #
-
详解Python进行数据相关性分析的三种方式
目录 相关性实现 NumPy 相关性计算 SciPy 相关性计算 Pandas 相关性计算 线性相关实现 线性回归:SciPy 实现 等级相关 排名:SciPy 实现 等级相关性:NumPy 和 SciPy 实现 等级相关性:Pandas 实现 相关性的可视化 带有回归线的 XY 图 相关矩阵的热图 matplotlib 相关矩阵的热图 seaborn 相关性实现 统计和数据科学通常关注数据集的两个或多个变量(或特征)之间的关系.数据集中的每个数据点都是一个观察值,特征是这些观察值的属性或属性.
-
详解Python中matplotlib模块的绘图方式
目录 1.matplotlib之父简介 2.matplotlib图形结构 3.matplotlib两种画绘图方法 方法一:使用matplotlib.pyplot 方法二:面向对象方法 1.matplotlib之父简介 matplotlib之父John D. Hunter已经去世,他的一生辉煌而短暂,但是他开发的的该开源库还在继续着辉煌.国内介绍的资料太少了,查阅了一番整理如下: 1968 出身于美国的田纳西州代尔斯堡. 之后求学于普林斯顿大学. 2003年发布Matplotlib 0.1版,初衷
-
详解Python OpenCV图像分割算法的实现
目录 前言 1.图像二值化 2.自适应阈值分割算法 3.Otsu阈值分割算法 4.基于轮廓的字符分离 4.1轮廓检测 4.2轮廓绘制 4.3包围框获取 4.4矩形绘制 前言 图像分割是指根据灰度.色彩.空间纹理.几何形状等特征把图像划分成若干个互不相交的区域. 最简单的图像分割就是将物体从背景中分割出来 1.图像二值化 cv2.threshold是opencv-python中的图像二值化方法,可以实现简单的分割功能. retval, dst = cv2.threshold(src, thresh
-
一文详解Python灰色预测模型实现示例
目录 前言 一.模型理论 特点 二.模型场景 1.预测种类 2.适用条件 三.建模流程 1.级比校验 3.系数求解 4.残差检验与级比偏差检验 四.Python实例实现 总结 前言 博主参与过大大小小十次数学建模比赛,也获得了不少建模奖项.对于一些小批量样本数据去做预测或者是评估其规律性的话,比较适合的模型一般都是选择灰色预测模型.该模型解释性强而且易于理解,建模手段也比较简单.在一些不确定是否存在相关标量或者是存在位置特征的时候,用灰色预测模型尤为明显,牵扯太多变量时候可以以量曾量减的方式显现
-
详解python里使用正则表达式的分组命名方式
详解python里使用正则表达式的分组命名方式 分组匹配的模式,可以通过groups()来全部访问匹配的元组,也可以通过group()函数来按分组方式来访问,但是这里只能通过数字索引来访问,如果某一天产品经理需要修改需求,让你在它们之中添加一个分组,这样一来,就会导致匹配的数组的索引的变化,作为开发人员的你,必须得一行一行代码地修改.因此聪明的开发人员又想到一个好方法,把这些分组进行命名,只需要对名称进行访问分组,不通过索引来访问了,就可以避免这个问题.那么怎么样来命名呢?可以采用(?P<nam