解决python 出现unknown encoding: idna 的问题
这个问题是编码的问题在开头导入个包就行了,简答粗暴
import encodings.idna
补充:执行Python出现LookupError: unknown encoding: cp65001解决办法
在执行fetch v8时出现
E:\GitProject\svn_v8>fetch v8
Running: 'E:\GitProject\libcef\depot_tools\python276_bin\python.exe' 'E:\GitProj
ect\libcef\depot_tools\gclient.py' root
Traceback (most recent call last):
File "E:\GitProject\libcef\depot_tools\\fetch.py", line 353, in <module>
sys.exit(main())
File "E:\GitProject\libcef\depot_tools\\fetch.py", line 348, in main
return run(options, spec, root)
File "E:\GitProject\libcef\depot_tools\\fetch.py", line 342, in run
return checkout.init()
File "E:\GitProject\libcef\depot_tools\\fetch.py", line 134, in init
self.run_gclient('config', '--spec', self._format_spec())
File "E:\GitProject\libcef\depot_tools\\fetch.py", line 76, in run_gclient
return self.run(cmd_prefix + cmd, **kwargs)
File "E:\GitProject\libcef\depot_tools\\fetch.py", line 63, in run
print 'Running: %s' % (' '.join(pipes.quote(x) for x in cmd))
LookupError: unknown encoding: cp65001
LookupError: unknown encoding: cp65001
出现此错误后改变编码方式即可解决:
chcp 1252
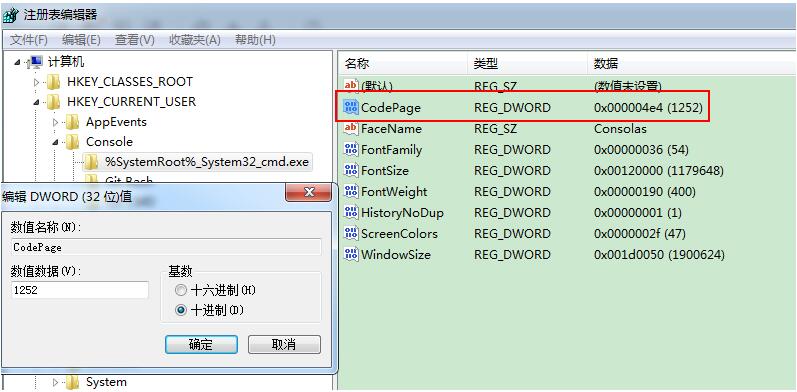
也可以通过修改注册表CodePage值来设置默认字符编码
HKEY_CURRENT_USER\Console\%SystemRoot%_system32_cmd.exe\CodePage
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

使用pycallgraph分析python代码函数调用流程以及框架解析
技术背景 在上一篇博客中,我们介绍了使用量子计算模拟器ProjectQ去生成一个随机数,也介绍了随机数的应用场景等.但是有些时候我们希望可以打开这里面实现的原理,去看看在产生随机数的过程中经历了哪些运算,调用了哪些模块.只有梳理清楚这些相关的内容,我们才能够更好的使用这个产生随机数的功能.这里我们就引入一个工具pycallgraph,可以根据执行的代码,给出这些代码背后所封装和调用的所有函数.类的关系图,让我们一起来了解下这个工具的安装和使用方法. Manjaro Linux平台安装graphv
-
使用python模块plotdigitizer抠取论文图片中的数据实例详解
技术背景 对于各行各业的研究人员来说,经常会面临这样的一个问题:有一篇不错的文章里面有很好的数据,但是这个数据在文章中仅以图片的形式出现.而假如我们希望可以从该图片中提取出数据,这样就可以用我们自己的形式重新来展现这些数据,还可以额外再附上自己优化后的数据.因此从论文图片中提取数据,是一个非常实际的需求.这里以前面写的量子退火的博客为例,博客中有这样的一张图片: 在这篇文章中,我们将介绍如何使用python从图片上把数据抠取出来. plotdigitizer的安装 这里我们使用pip来安装pyt
-
Python中docx2txt库的使用说明
docx2txt的Github地址 docx2txt是基于python的从docx文件中提取文本和图片的库. 代码是从python-docx中获取的.它也可以从页眉,页脚和超链接中提取文本.它现在也可以提取图像. 安装 pip install docx2txt 运行 1.命令行运行 # extract text docx2txt file.docx # extract text and images docx2txt -i /tmp/img_dir file.docx 2.在python中调用
-
python docx的超链接网址和链接文本操作
我就废话不多说了,大家还是直接看代码吧~ from docx import Document from docx import RT import re d=Document("./liu2.docx") for p in d.paragraphs: rels = d.part.rels for rel in rels: if rels[rel].reltype == RT.HYPERLINK: print("\n 超链接文本为", rels[rel], "
-
python flask框架详解
Flask是一个Python编写的Web 微框架,让我们可以使用Python语言快速实现一个网站或Web服务.本文参考自Flask官方文档, 英文不好的同学也可以参考中文文档 1.安装flask pip install flask 2.简单上手 一个最小的 Flask 应用如下: from flask import Flask app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello World' if __na
-
python encode和decode的妙用
>>> "hello".encode("hex") '68656c6c6f' 相应的还可以 >>> '68656c6c6f'.decode("hex") 'hello' 查了一下手册,还有这些codec可用 Codec Aliases Operand type Purpose base64_codec base64, base-64 byte string Convert operand to MIME bas
-
解决python 出现unknown encoding: idna 的问题
这个问题是编码的问题在开头导入个包就行了,简答粗暴 import encodings.idna 补充:执行Python出现LookupError: unknown encoding: cp65001解决办法 在执行fetch v8时出现 E:\GitProject\svn_v8>fetch v8 Running: 'E:\GitProject\libcef\depot_tools\python276_bin\python.exe' 'E:\GitProj ect\libcef\depot_too
-
解决python文件字符串转列表时遇到空行的问题
文件内容如下: Alex 100000 Rain 80000 Egon 50000 Yuan 30000 #此处有一个空行! 现在看如何处理并转成列表! salary_info = open("salaryinfo.txt", "r+", encoding="UTF-8") salary_info_list = [] for line in salary_info.readlines(): if line == '\n': pass else:
-
解决Python requests库编码 socks5代理的问题
编码问题 response = requests.get(URL, params=params, headers=headers, timeout=10) print 'self.encoding',response.encoding output: self.encoding ISO-8859-1 查了一些相关的资料,看了下requests的源码,只有在服务器响应的头部包含有Content-Type,且里面有charset信息,requests能够正确识别,否则就会使用默认的 ISO-8859
-
解决Python 写文件报错TypeError的问题
处理上传的文件: f1 = request.FILES['pic'] fname = '%s/%s' % (settings.MEDIA_ROOT, f1.name) with open(fname, 'w') as pic: for c in f1.chunks(): pic.write(c) 测试报错: TypeError at /upload/ write() argument must be str, not bytes 把之前的打开语句修改为用二进制方式打开: f1 = request
-
解决python中文乱码问题方法总结
在运行这样类似的代码: #!/usr/bin/env pythons="中文"print s 最近经常遇到这样的问题: 问题一: SyntaxError: Non-ASCII character '\xe4' in file E:\coding\python\Untitled 6.py on line 3, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details 问题二: Un
-
解决Python 遍历字典时删除元素报异常的问题
错误的代码① d = {'a':1, 'b':0, 'c':1, 'd':0} for key, val in d.items(): del(d[k]) 错误的代码② -- 对于Python3 d = {'a':1, 'b':0, 'c':1, 'd':0} for key, val in d.keys(): del(d[k]) 正确的代码 d = {'a':1, 'b':0, 'c':1, 'd':0} keys = list(d.keys()) for key, val in keys: d
-
解决Python中字符串和数字拼接报错的方法
前言 众所周知Python不像JS或者PHP这种弱类型语言里在字符串连接时会自动转换类型,如果直接将字符串和数字拼接会直接报错. 如以下的代码: # coding=utf8 str = '你的分数是:' num = 82 text = str+num+'分 | 琼台博客' print text 执行结果 直接报错:TypeError: cannot concatenate 'str' and 'int' objects 解决这个方法只有提前把num转换为字符串类型,可以使用bytes函数把int
-
简单解决Python文件中文编码问题
读写中文 需要读取utf-8编码的中文文件,先利用sublime text软件将它改成无DOM的编码,然后用以下代码: with codecs.open(note_path, 'r+','utf-8') as f: line=f.readline() print line 这样就可以正确地读出文件里面的中文字符了. 同样的,如果要在创建的文件中写入中文,最好也和上面差不多: with codecs.open(st,'a+','utf-8') as book_note: book_note.wri
-
解决Python字典写入文件出行首行有空格的问题
模拟购物车程序,判断用户薪资是否是0 如果是0就需要输入薪资,并记录到文件内. 可以预先存个字典格式的字符串,然后去读取文件的时候读到的是字字符串然后再去用eval去转换成字典. 当我们覆盖写到文件的时候就会发现首行会有空格,当我们再去读取eval的时候就会报错,那怎么样可以解决这个问题呢! import json info = { 'lisi':0, 'zhangshan':100, } f = open('json.txt','w') f.write(json.dumps(info)) {"
-
完美解决python遍历删除字典里值为空的元素报错问题
exam = { 'math': '95', 'eng': '96', 'chn': '90', 'phy': '', 'chem': '' } 使用下列遍历的方法删除: 1. for e in exam: 2. if exam[e] == '': 3. del exam[e] 结果出现下列错误,怎么解决: Traceback (most recent call last): File "Untitled.py", line 3, in <module> for e in