python 实现存储数据到txt和pdf文档及乱码问题的解决
第一、几种常用方法
读取TXT文档:urlopen()
读取PDF文档:pdfminer3k
第二、乱码问题
(1)、
from urllib.request import urlopen
#访问wiki内容
html = urlopen("https://en.wikipedia.org/robots.txt")
print(html.read())
输出的结果中出现乱码原因:
计算机只能处理0和1两个数字,所以想要处理文本,必须把文本变成0和1这样的数字,最早的计算机使用八个0和1表示一个字节,所以最大能够表示整数是255=11111111.如果想要表示更大的数,必须使用更多的字节。
由于计算机是美国人发明的,所以最早只有127个字符被编写进计算机,即常见的阿拉伯数字,字母大小写,以及键盘上的符号。此编码被称为ASCII编码,比如大写字母A的ASCII编码是65,65再被转换二进制01000001,即是计算机处理的东西。
显然,ASCII不能表示中文,故中国制定了自己的GB2312编码,并且兼容ASCII编码。问题是:使用GB2312编码的慕课网三个字,假设编码为61,62,63.但在ASCII码表可能是其他字符。如下图示,日文中的616263编码成其他字符,打开后意思出错。

解决方法:
国际上的unicode编码,整合全世界所有编码。故unicode编码的内容在任一台计算机用unicode仍正常打开
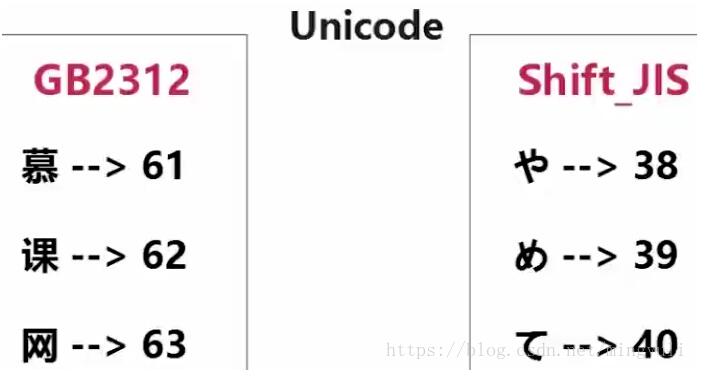
又对于A,ASCII编码为01000001,Unicode编码:0000000001000001此时浪费空间
故出现UTF-8编码:01000001此时用两个八位存储中文。
(2)、记事本使用unicode编码,将记事本存到计算机时,将转化为utf-8储存。
在计算机中打开文本时,将转化为unicode编码
存储原因:使用utf-8储存节省空间,使用unicode打开保证最大的兼容
(3)、服务器读取uncode编码的文档,转化为utf-8格式传给浏览器。因为网络带宽昂贵,转化为了减少负担。
(4)、python3字符串默认使用Unicode编码,所以python3支持多种语言
以Unicode表示的str通过encode()方法可以编码为指定的bytes
如果bytes使用ASCII编码,遇到ASCII码表没有的字符会以\x##表示,此时只用‘\x##'.decode('utf-8')即可
(5)、解决方法
from urllib.request import urlopen
#访问wiki内容
html = urlopen("https://en.wikipedia.org/robots.txt")
print(html.read().decode("utf-8"))
第三、pdfminer3k安装
法一:
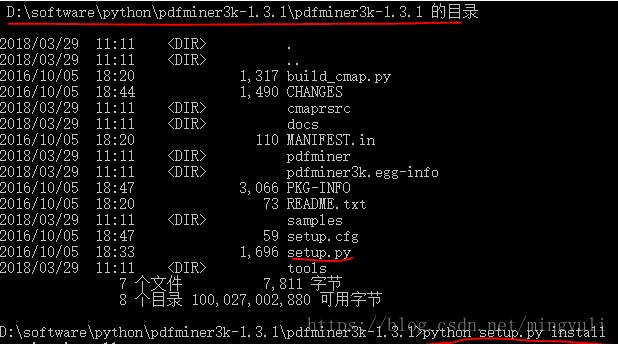
(1)、进入网址直接下载并解压:https://pypi.python.org/pypi/pdfminer3k/
(2)、以管理员身份运行命令行窗口,进入软件解压缩位置,运行python setup.py install
法二:
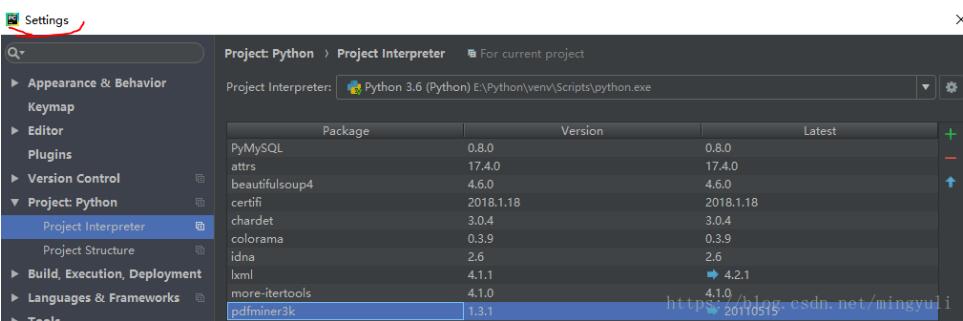
(3)、直接在pycharm中安装
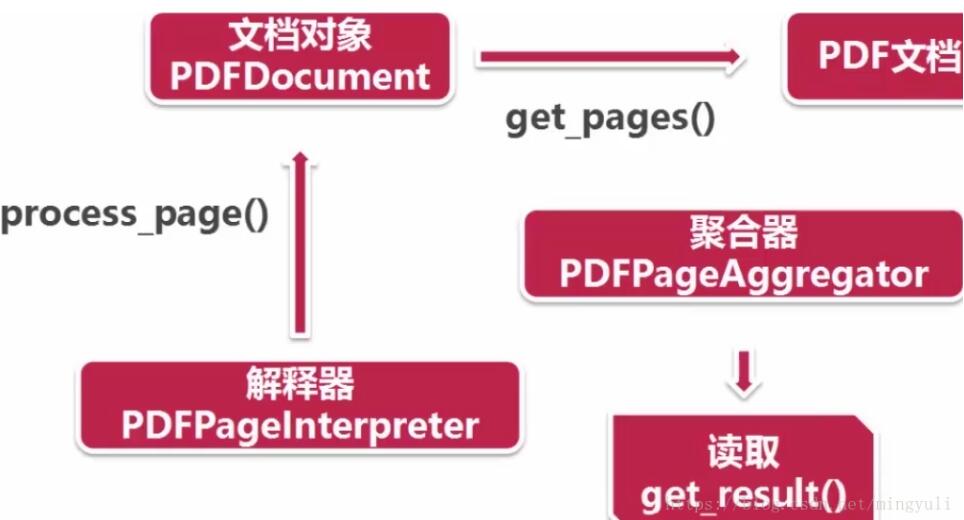
(4)、读取pdf过程:首先创建一个分析器pdfparser和文档对象pdfdocument,并通过两个方法相互关联,然后调用文档对象的初始化方法(可以传参数),此时资源内容被加载到文档对象中。
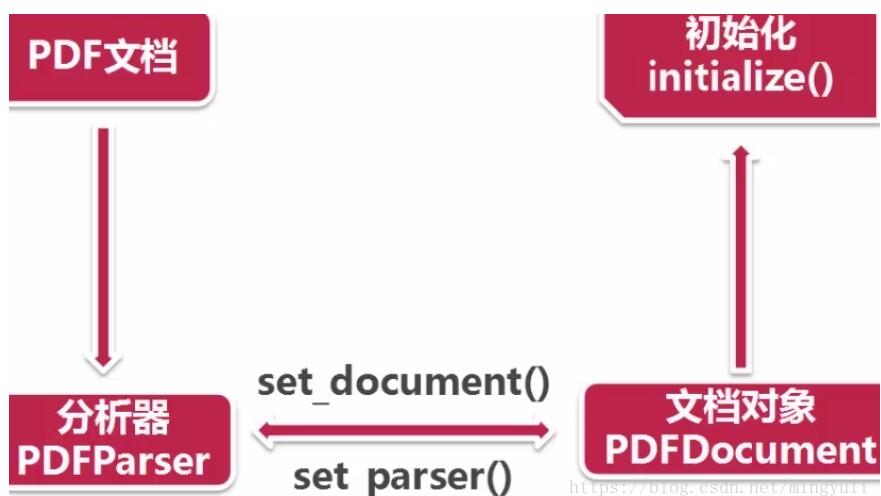
创建资源管理器和参数分析器,然后创建聚合器(整合资源管理器和参数分析器),通过聚合器创建解释器(对pdf文档进行编码,解释成python能识别的格式)
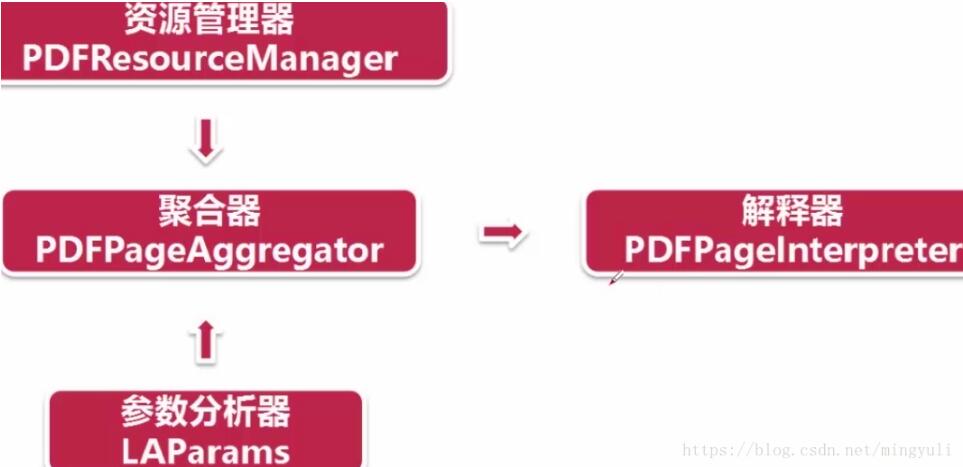
(5)、读取pdf文档:通过文档对象的get_pages()方法得到pdf每一页的内容,通过解释器的process_page()方法读取一页一页。
(6)、实例演示
from pdfminer.converter import PDFPageAggregator
from pdfminer.layout import LAParams
from pdfminer.pdfparser import PDFParser, PDFDocument
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter
from pdfminer.pdfdevice import PDFDevice
#获得文档对象,以二进制读方式打开
fp = open("naacl06-shinyama.pdf", "rb")
#创建一个与文档关联的分析器
parser = PDFParser(fp)
#创建一个pdf文档的对象
doc = PDFDocument()
#连接解释器与文档对象
parser.set_document(doc)
doc.set_parser(parser)
#初始化文档,如果文档有密码,写与此。
doc.initialize("")
#创建pdf资源管理器
resource = PDFResourceManager()
#参数分析器
laparam = LAParams()
#创建聚合器
device = PDFPageAggregator(resource, laparams=laparam)
#创建pdf页面解释器
interpreter = PDFPageInterpreter(resource, device)
#使用文档对象得到页面的集合
for page in doc.get_pages():
#使用页面解释器读取
interpreter.process_page(page)
#使用聚合器来获得内容
layout = device.get_result()
for out in layout:
if hasattr(out, "get_text"):
print(out.get_text())
一下用于读取网站上pdf内容
fp = urlopen(http://www.tencent.com/zh-cn/articles/8003251479983154.pdf)
补充内容:
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

Python读写txt文本文件的操作方法全解析
一.文件的打开和创建 >>> f = open('/tmp/test.txt') >>> f.read() 'hello python!\nhello world!\n' >>> f <open file '/tmp/test.txt', mode 'r' at 0x7fb2255efc00> 二.文件的读取 步骤:打开 -- 读取 -- 关闭 >>> f = open('/tmp/test.txt') >>&
-
Python3将数据保存为txt文件的方法
Python3将数据保存为txt文件的方法,具体内容如下所示: f = open("data/model_Weight.txt",'a') #若文件不存在,系统自动创建.'a'表示可连续写入到文件,保留原内容,在原 #内容之后写入.可修改该模式('w+','w','wb'等) f.write("hello,sha") #将字符串写入文件中 f.write("\n") #换行 if __name__=='__main__': fw = open(&
-
python学习将数据写入文件并保存方法
python将文件写入文件并保存的方法: 使用python内置的open()函数将文件打开,用write()函数将数据写入文件,最后使用close()函数关闭并保存文件,这样就可以将数据写入文件并保存了. 示例代码如下: file = open("ax.txt", 'w') file.write('hskhfkdsnfdcbdkjs') file.close() 执行结果: 内容扩展: python将字典中的数据保存到文件中 d = {'a':'aaa','b':'bbb'} s =
-
Python3 解决读取中文文件txt编码的问题
问题描述 尝试用Python写一个Wordcloud的时候,出现了编码问题. 照着网上某些博客的说法添添改改后,结果是变成了"UnicodeDecodeError: 'utf-8' codec can't decode byte-"这个错误. 捣鼓了一天啊,TXT(此处为本人现下内心表情).最后,干脆写个最简单的文件读取,竟然还是报错.于是就考虑是不是txt的编码问题,因为读取的txt文件是在Mac上面新建的纯文本文件,一时没找到在哪里查看编码,最后拷贝到Windows系统上,查看了t
-
python 实现存储数据到txt和pdf文档及乱码问题的解决
第一.几种常用方法 读取TXT文档:urlopen() 读取PDF文档:pdfminer3k 第二.乱码问题 (1). from urllib.request import urlopen #访问wiki内容 html = urlopen("https://en.wikipedia.org/robots.txt") print(html.read()) 输出的结果中出现乱码原因: 计算机只能处理0和1两个数字,所以想要处理文本,必须把文本变成0和1这样的数字,最早的计算机使用八个0和1
-
详解Java生成PDF文档方法
最近项目需要实现PDF下载的功能,由于没有这方面的经验,从网上花了很长时间才找到相关的资料.整理之后,发现有如下几个框架可以实现这个功能. 1. 开源框架支持 iText,生成PDF文档,还支持将XML.Html文件转化为PDF文件: Apache PDFBox,生成.合并PDF文档: docx4j,生成docx.pptx.xlsx文档,支持转换为PDF格式. 比较: iText开源协议为AGPL,而其他两个框架协议均为Apache License v2.0. 使用PDFBox生成PDF就像画图
-
Python实现pdf文档转txt的方法示例
本文实例讲述了Python实现pdf文档转txt的方法.分享给大家供大家参考,具体如下: 首先,这是一个比较粗糙的版本,因为已经够用了,而且对pdf的格式不熟悉,所以暂时没有进一步优化. 还有,这是转成txt的,所以如果是有图片的pdf是无法保存图片的. 至于本来就是图片的文本,这里是无法分析出来的.那些图片的pdf,估计要用图形匹配的方式来处理,类似于超速拍摄的车牌识别. 不过这样的程度,已经不是文本处理了.扯远了... 转出来的文字,好像按照pdf里面的所展示的来换行了,看不到有什么规则还原
-
利用python程序生成word和PDF文档的方法
一.程序导出word文档的方法 将web/html内容导出为world文档,再java中有很多解决方案,比如使用Jacob.Apache POI.Java2Word.iText等各种方式,以及使用freemarker这样的模板引擎这样的方式.php中也有一些相应的方法,但在python中将web/html内容生成world文档的方法是很少的.其中最不好解决的就是如何将使用js代码异步获取填充的数据,图片导出到word文档中. 1. unoconv 功能: 1.支持将本地html文档转换为docx
-
python 使用pdfminer3k 读取PDF文档的例子
1.安装 pdfminer3k 通过pip安装: pip install pdfminer3k 下载安装:在网页 https://pypi.org/project/pdfminer3k/1.3.1/#files 进行下载,解压.然后cmd命令进入到当前文件夹: 可以直接在资源管理器的路径栏直接输入cmd进入到当前目录.然后执行 python setup.py install 等待安装完成 2.读取pdf中的TXT代码示例: from pdfminer.converter import PDFPa
-
Python利用PyPDF2快速拆分PDF文档
目录 安装PyPDF2模块 创建文件,准备PDF文档 万事俱备,准备开拆 文档的拆分思路 python拆分计算公式: 具体怎么拆? 完整拆分程序: 列表拆分法实现拆分PDF 写在最后 "人生苦短,快学Python",因为这句口号,我也加入了学习Python的浩浩大军,但由于Python真的是可以做的事情太多了,一时迷了眼,不知道自己应该去专攻哪个方向. 经过多方向试探,我还是选择了广而不深的web开发,Python的web开发自然离不开大名鼎鼎的Django,有一次突发奇想,下载了Dj
-
基于Python实现网页文章转PDF文档
我们有时候看到一篇好的文章,想去保存下来,传统方式一般是收藏书签.复制粘贴到文档或者直接复制链接保存,但这样一次两次还好,数量多了,比较麻烦不说,还可能不好找~ 这个时候,Python的作用就来了,直接抓下来导出为PDF,直接把整个网站的内容都导下来都行~ 话不多说,我们直接上代码! import requests import parsel import pdfkit import os import re html_str = """ <!doctype html&
-
python解析html提取数据,并生成word文档实例解析
简介 今天试着用ptyhon做了一个抓取网页内容,并生成word文档的功能,功能很简单,做一下记录以备以后用到. 生成word用到了第三方组件python-docx,所以先进行第三方组件的安装.由于windows下安装的python默认不带setuptools这个模块,所以要先安装setuptools这个模块. 安装 1.在python官网上找到 https://bootstrap.pypa.io/ez_setup.py ,把代码保存到本地并执行: python ez_setup.py 2.下载
-
python输出pdf文档的实例
python导出pdf,参考诸多资料,发现pdfkit是效果比较好的. 故下载后进行了实现,多次失败后终于成功了,现将其中经验总结如下: """ 需要安装pdfkit,另外需要安装可执行文件wkhtmltopdf.exe, pdfkit核心命令是调用wkhtmltopdf.exe实现转pdf 有三个接口: pdfkit.from_url pdfkit.from_string pdfkit.from_file 需要注意的是,pdfkit主要是用来将html转pdf,所以文件也是
-
Python一键实现PDF文档批量转Word
目录 实现效果 环境准备 代码实现 无论是在工作还是学习当中,大家都会遇到这样一个问题,将“PDF当中的内容(文本和图片)转换为Word的格式”,也就是说从只读转换成可编辑的格式.网上绝大多数的工具也都是收费的,今天小编就给大家制作了一款批量将PDF文件转换为Word的神器,使用起来也是相当的方便. 实现效果 我们首先来看一下出来的效果,如下图所示 环境准备 用到的模块叫做pdf2docx,我们通过pip命令进行下载,如下 pip install pdf2docx 后续我们还可以为py文件打包,