将Swagger2文档导出为HTML或markdown等格式离线阅读解析

网上有很多《使用swagger2构建API文档》的文章,该文档是一个在线文档,需要使用HTTP访问。但是在我们日常使用swagger接口文档的时候,有的时候需要接口文档离线访问,如将文档导出为html、markdown格式。又或者我们不希望应用系统与swagger接口文档使用同一个服务,而是导出HTML之后单独部署,这样做保证了对接口文档的访问不影响业务系统,也一定程度提高了接口文档的安全性。核心的实现过程就是:
- 在swagger2接口文档所在的应用内,利用swagger2markup将接口文档导出为adoc文件,也可以导出markdown文件。
- 然后将adoc文件转换为静态的html格式,可以将html发布到nginx或者其他的web应用容器,提供访问(本文不会讲html静态部署,只讲HTML导出)。
注意:adoc是一种文件格式,不是我的笔误。不是doc文件也不是docx文件。
一、maven依赖类库
在已经集成了swagger2的应用内,通过maven坐标引入相关依赖类库,pom.xml代码如下:
<dependency> <groupId>io.github.swagger2markup</groupId> <artifactId>swagger2markup</artifactId> <version>1.3.1</version> </dependency> <dependency> <groupId>io.swagger</groupId> <artifactId>swagger-core</artifactId> <version>1.5.16</version> </dependency> <dependency> <groupId>io.swagger</groupId> <artifactId>swagger-models</artifactId> <version>1.5.16</version> </dependency>
swagger2markup用于将swagger2在线接口文档导出为html,markdown,adoc等格式文档,用于静态部署或离线阅读。其中第一个maven坐标是必须的。后两个maven坐标,当你在执行后面的代码过程中报下图中的ERROR,或者有的类无法import的时候使用。

产生异常的原因已经有人在github的issues上给出解释了:当你使用swagger-core版本大于等于1.5.11,并且swagger-models版本小于1.5.11就会有异常发生。所以我们显式的引入这两个jar,替换掉swagger2默认引入的这两个jar。

二、生成adoc格式文件
下面的代码是通过编码方式实现的生成adoc格式文件的方式
@RunWith(SpringRunner.class)
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.DEFINED_PORT)
public class DemoApplicationTests {
@Test
public void generateAsciiDocs() throws Exception {
// 输出Ascii格式
Swagger2MarkupConfig config = new Swagger2MarkupConfigBuilder()
.withMarkupLanguage(MarkupLanguage.ASCIIDOC) //设置生成格式
.withOutputLanguage(Language.ZH) //设置语言中文还是其他语言
.withPathsGroupedBy(GroupBy.TAGS)
.withGeneratedExamples()
.withoutInlineSchema()
.build();
Swagger2MarkupConverter.from(new URL("http://localhost:8888/v2/api-docs"))
.withConfig(config)
.build()
.toFile(Paths.get("src/main/resources/docs/asciidoc"));
}
}
使用RunWith注解和SpringBootTest注解,启动应用服务容器。 SpringBootTest.WebEnvironment.DEFINED_PORT表示使用application.yml定义的端口,而不是随机使用一个端口进行测试,这很重要。
Swagger2MarkupConfig 是输出文件的配置,如文件的格式和文件中的自然语言等
Swagger2MarkupConverter的from表示哪一个HTTP服务作为资源导出的源头(JSON格式),可以自己访问试一下这个链接。8888是我的服务端口,需要根据你自己的应用配置修改。
toFile表示将导出文件存放的位置,不用加后缀名。也可以使用toFolder表示文件导出存放的路径。二者区别在于使用toFolder导出为文件目录下按标签TAGS分类的多个文件,使用toFile是导出一个文件(toFolder多个文件的合集)。
@Test
public void generateMarkdownDocsToFile() throws Exception {
// 输出Markdown到单文件
Swagger2MarkupConfig config = new Swagger2MarkupConfigBuilder()
.withMarkupLanguage(MarkupLanguage.MARKDOWN)
.withOutputLanguage(Language.ZH)
.withPathsGroupedBy(GroupBy.TAGS)
.withGeneratedExamples()
.withoutInlineSchema()
.build();
Swagger2MarkupConverter.from(new URL("http://localhost:8888/v2/api-docs"))
.withConfig(config)
.build()
.toFile(Paths.get("src/main/resources/docs/markdown"));
}
上面的这一段代码是生成markdown格式接口文件的代码。执行上面的2段单元测试代码,就可以生产对应格式的接口文件。
还有一种方式是通过maven插件的方式,生成adoc和markdown格式的接口文件。笔者不常使用这种方式,没有使用代码生成的方式配置灵活,很多配置都放到pom.xml感觉很臃肿。但还是介绍一下,首先配置maven插件swagger2markup-maven-plugin。
<plugin> <groupId>io.github.swagger2markup</groupId> <artifactId>swagger2markup-maven-plugin</artifactId> <version>1.3.1</version> <configuration> <swaggerInput>http://localhost:8888/v2/api-docs</swaggerInput><!---swagger-api-json路径--> <outputDir>src/main/resources/docs/asciidoc</outputDir><!---生成路径--> <config> <swagger2markup.markupLanguage>ASCIIDOC</swagger2markup.markupLanguage><!--生成格式--> </config> </configuration> </plugin>
然后运行插件就可以了,如下图:

三、通过maven插件生成HTML文档
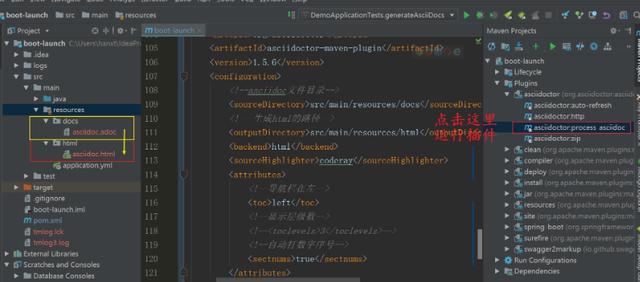
<plugin> <groupId>org.asciidoctor</groupId> <artifactId>asciidoctor-maven-plugin</artifactId> <version>1.5.6</version> <configuration> <!--asciidoc文件目录--> <sourceDirectory>src/main/resources/docs</sourceDirectory> <!---生成html的路径--> <outputDirectory>src/main/resources/html</outputDirectory> <backend>html</backend> <sourceHighlighter>coderay</sourceHighlighter> <attributes> <!--导航栏在左--> <toc>left</toc> <!--显示层级数--> <!--<toclevels>3</toclevels>--> <!--自动打数字序号--> <sectnums>true</sectnums> </attributes> </configuration> </plugin>
adoc的sourceDirectory路径必须和第三小节中生成的adoc文件路径一致。然后按照下图方式运行插件。
HTMl接口文档显示的效果如下,有了HTML接口文档你想转成其他各种格式的文档就太方便了,有很多工具可以使用。这里就不一一介绍了。

总结
以上所述是小编给大家介绍的将Swagger2文档导出为HTML或markdown等格式离线阅读解析,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

CommonMark 使用教程:将 Markdown 语法转成 Html
Markdown写作 从 2016年 开始写博客,我的写作方式一直在改变,准确的说一直在进步,因为效率越来越高. 最初在 CSDN 上写东西时非常蹩脚,在他们编辑器上写点然后调整格式,再写,碰到图片还得将图片插入进去,调整图片大小位置等等,调整完继续写. 效率非常低. 后面了解到 Markdown ,改用 MD 写东西,效率快很多.后面在 Markdown 基础上慢慢优化找到自己的写作方式. 一般我用 MD 语法写完后,得到的是一堆带 MD 符号的文字,以下简称 MD文本. 然后会通过工具转成对
-
python使用html2text库实现从HTML转markdown的方法详解
如果PyPi上搜html2text的话,找到的是另外一个库:Alir3z4/html2text.这个库是从aaronsw/html2text fork过来,并在此基础上对功能进行了扩展.因此是直接用pip安装的,因此本文主要来讲讲这个库. 首先,进行安装: pip install html2text 命令行方式使用html2text 安装完后,就可以通过命令html2text进行一系列的操作了. html2text命令使用方式为:html2text [(filename|url) [encodi
-
Django渲染Markdown文章目录的方法示例
对会读书的人来说,读一本书要做的第一件事,就是仔细阅读这本书的目录.阅读目录可以对整体内容有所了解,并清楚地知道感兴趣的部分在哪里,提高阅读质量. 博文也是同样的,好的目录对博主和读者都很有帮助.更进一步的是,还可以在目录中设置锚点,点击标题就立即前往该处,非常的方便. 文中的目录 之前我们已经为博文支持了Markdown语法,现在继续增强其功能. 有折腾代码高亮的痛苦经历之后,设置Markdown的目录扩展就显得特别轻松了. 修改文章详情视图: article/views.py ... # 文
-
PyCharm安装Markdown插件的两种方法
Markdown是一种可以使用普通文本编辑器编写的标记语言,通过简单的标记语法,它可以使普通文本内容具有一定的格式. 从github下载的代码一般都会带有README.md文件,该文件是一个Markdown格式的文件.PyCharm是默认没有安装Markdown插件的,所以不能按照Markdown格式显示文本,显示的是原始文本.下面已github库PyWatchlog的代码为例介绍两种安装Markdown的方法. 方法一: 在PyCharm打开PyWatchlog工程后打开README.md文件
-
Vuejs中使用markdown服务器端渲染的示例
啊哈,又是来推荐一个 vuejs 的 package,miaolz123/vue-markdown. 对应的应用场景是:你想使用一个编辑器或者是在评论系统中支持 markdown.这个 package 的有点还是挺多了,比如默认就支持 emoji,这个就很完美啦!laravist 的新版就使用了 vue-markdown 来渲染评论. 安装 直接使用 npm 来安装: npm install --save vue-markdown 使用 也是很简单的,可以直接这样: import VueMark
-
JS加载解析Markdown文档过程详解
网上有很多网站会通过.md文档来做页面内容,很好奇,这是怎么做的? 出于好奇,建了一个test.md文件: # Hello World! asdfa asd *斜体文本* **粗体文本** ***斜粗体文本*** 分隔线(如下) *** * * * **** - - - ----------- GOOGLE.COM ~~删除线~~ <u>下划线</u> 用浏览器打开之后,结果就被原封不动的输出来了,浏览器根本不会解析这玩意... 跟阮老师的blog相差好大啊~呵呵~还是太天真了!
-
vue-cli3项目展示本地Markdown文件的方法
[版本] vue-cli3 webpack@4.33.0 [步骤]1.安装插件vue-markdown-loader npm i vue-markdown-loader -D ps:这个插件是基于markdown-it的,不需要单独安装markdown-it. 2.修改vue.config.js配置文件(如果没有,在项目根目录新建一个): module.exports = { chainWebpack: config => { config.module.rule('md') .test(/\.
-
将Swagger2文档导出为HTML或markdown等格式离线阅读解析
网上有很多<使用swagger2构建API文档>的文章,该文档是一个在线文档,需要使用HTTP访问.但是在我们日常使用swagger接口文档的时候,有的时候需要接口文档离线访问,如将文档导出为html.markdown格式.又或者我们不希望应用系统与swagger接口文档使用同一个服务,而是导出HTML之后单独部署,这样做保证了对接口文档的访问不影响业务系统,也一定程度提高了接口文档的安全性.核心的实现过程就是: 在swagger2接口文档所在的应用内,利用swagger2markup将接口文
-
Java使用itext5实现PDF表格文档导出
最近拿到一个需求,需要导出PDF文档,市面上可以实现的方法有很多,经过测试和调研决定使用itext5来实现,话不多说,说干就干. 1.依赖导入 <!-- https://mvnrepository.com/artifact/com.itextpdf/itextpdf --> <dependency> <groupId>com.itextpdf</groupId> <artifactId>itextpdf</artifactId> &l
-
SpringBoot基于Swagger2构建API文档过程解析
一.添加依赖 <!--SpringBoot使用Swagger2构建API文档的依赖--> <dependency> <groupId>io.springfox</groupId> <artifactId>springfox-swagger2</artifactId> <version>2.7.0</version> </dependency> <dependency> <group
-
Springboot中整合knife4j接口文档的过程详解
目录 什么是knife4j 界面欣赏 主页 接口文档 调试界面 参数实体 整合 knife4j 引入 maven 依赖 knife4j 配置文件 配置API接口 knife4j 常用特性 全局参数 离线文档 在项目开发过程中,web项目的前后端分离开发,APP开发,需要由前端后端工程师共同定义接口,编写接口文档,之后大家都根据这个接口文档进行开发. 什么是knife4j 简单说knife4j就swagger的升级版API文档的一个框架,但是用起来比swagger方便多了,UI更加丰富. 界面欣赏
-
得到XML文档大小的方法
XML文档从格式到大小都是不是确定的.有的可能只有几行,而有的却有好几兆字节.你也许会怀疑是不是需要了解XML文档的大小.而当性能成为首要问题时,知道XML文档大小就是件必须要作的事情了. 从性能角度讲,有两类处理XML文档的方法.批量处理方式需要较短的时间,解析成组的文档.实时方式就是实时的处理文档.批处理方式的性能可以通过在一定时间内处理多少文档来测量,而实时模式的性能也采用类似的测量方式,不过是以处理一个文档需要多长时间来计算的. Scenarios场景 想象一下,你有一个实时工作的系统,
-
如何得到XML文档大小
XML文档从格式到大小都是不是确定的.有的可能只有几行,而有的却有好几兆字节.你也许会怀疑是不是需要了解XML文档的大小.而当性能成为首要问题时,知道XML文档大小就是件必须要作的事情了. 从性能角度讲,有两类处理XML文档的方法.批量处理方式需要较短的时间,解析成组的文档.实时方式就是实时的处理文档.批处理方式的性能可以通过在一定时间内处理多少文档来测量,而实时模式的性能也采用类似的测量方式,不过是以处理一个文档需要多长时间来计算的. Scenarios场景想象一下,你有一个实时工作的系统,比
-
文档对象模型DOM通俗讲解
在开始之前先说一点,DOM是非常容易理解的,但是大家说的太官方,让人很是难于理解,我们就用非常简单的语言翻译一遍.加深对DOM的理解,从而对它有一个全面的认识. 什么是DOM DOM的全称是Document Object Model,即文档对象模型,它允许脚本控制Web页面.窗口和文档. 如果没有DOM,JavaScript将是另外一种脚本语言:而有了DOM,它将成为制作动态页面的强有力工具.DOM不是JavaScript语言的一部分,而是内置在浏览器中的一个应用程序接口.当然,我们可以简单的理
-
java中四种生成和解析XML文档的方法详解(介绍+优缺点比较+示例)
众所周知,现在解析XML的方法越来越多,但主流的方法也就四种,即:DOM.SAX.JDOM和DOM4J 下面首先给出这四种方法的jar包下载地址 DOM:在现在的Java JDK里都自带了,在xml-apis.jar包里 SAX:http://sourceforge.net/projects/sax/ JDOM:http://jdom.org/downloads/index.html DOM4J:http://sourceforge.net/projects/dom4j/ 一.介绍及优缺点分析
-
基于PHP与XML的PDF文档生成技术
摘要 本论文简要介绍了PHP.XML.PDF等技术的原理以及它们的应用情况.力图运用PHP面向对象的特性,构建出一套基于PHP和XML的在线PDF文档生成系统.文中详细探讨了整个系统的组成部分以及各自的实现过程.并在最后给出一个运用这套系统实现的动态创建报表的实例. AbstractThis article introduced the fundamentls of PHP,XML and PDF and their application situation at present,expect
-
java简单实现用语音读txt文档方法总结
最近比较无聊,随便翻着博客,无意中看到了有的人用VBS读文本内容,也就是读几句中文,emmm,挺有趣的,实现也很简单,都不需要安装什么环境,直接新建txt文件,输入一些简单的vbs读文本的代码,然后将新建的文件后缀改为.vbs,然后双击一下就可以有效果了.... 于是我就想啊,java行不行呢?查了一些资料,还真的行,我就将我试验的过程说一下,就当作娱乐娱乐! 1.依赖 随便新建一个maven项目,导入依赖 <dependency> <groupId>com.hynnet</