Python实现遗传算法(二进制编码)求函数最优值方式
目标函数
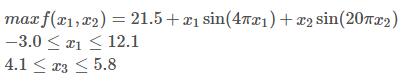
编码方式
本程序采用的是二进制编码精确到小数点后五位,经过计算可知对于 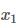 其编码长度为18,对于
其编码长度为18,对于  其编码长度为15,因此每个基于的长度为33。
其编码长度为15,因此每个基于的长度为33。
参数设置
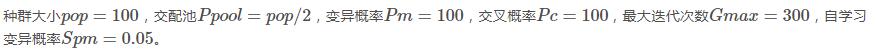
算法步骤
设计的程序主要分为以下步骤:1、参数设置;2、种群初始化;3、用轮盘赌方法选择其中一半较好的个体作为父代;4、交叉和变异;5、更新最优解;6、对最有个体进行自学习操作;7结果输出。其算法流程图为:

算法结果
由程序输出可知其最终优化结果为38.85029, 
输出基因编码为[1 1 0 0 1 0 1 1 1 1 1 1 1 0 1 1 1 1 0 1 0 1 1 0 1 0 0 1 0 1 1 1 1]。
代码
import numpy as np
import random
import math
import copy
class Ind():
def __init__(self):
self.fitness = 0
self.x = np.zeros(33)
self.place = 0
self.x1 = 0
self.x2 = 0
def Cal_fit(x, upper, lower): #计算适应度值函数
Temp1 = 0
for i in range(18):
Temp1 += x[i] * math.pow(2, i)
Temp2 = 0
for i in range(18, 33, 1):
Temp2 += math.pow(2, i - 18) * x[i]
x1 = lower[0] + Temp1 * (upper[0] - lower[0])/(math.pow(2, 18) - 1)
x2 = lower[1] + Temp2 * (upper[1] - lower[1])/(math.pow(2, 15) - 1)
if x1 > upper[0]:
x1 = random.uniform(lower[0], upper[0])
if x2 > upper[1]:
x2 = random.uniform(lower[1], upper[1])
return 21.5 + x1 * math.sin(4 * math.pi * (x1)) + x2 * math.sin(20 * math.pi * x2)
def Init(G, upper, lower, Pop): #初始化函数
for i in range(Pop):
for j in range(33):
G[i].x[j] = random.randint(0, 1)
G[i].fitness = Cal_fit(G[i].x, upper, lower)
G[i].place = i
def Find_Best(G, Pop):
Temp = copy.deepcopy(G[0])
for i in range(1, Pop, 1):
if G[i].fitness > Temp.fitness:
Temp = copy.deepcopy(G[i])
return Temp
def Selection(G, Gparent, Pop, Ppool): #选择函数
fit_sum = np.zeros(Pop)
fit_sum[0] = G[0].fitness
for i in range(1, Pop, 1):
fit_sum[i] = G[i].fitness + fit_sum[i - 1]
fit_sum = fit_sum/fit_sum.max()
for i in range(Ppool):
rate = random.random()
Gparent[i] = copy.deepcopy(G[np.where(fit_sum > rate)[0][0]])
def Cross_and_Mutation(Gparent, Gchild, Pc, Pm, upper, lower, Pop, Ppool): #交叉和变异
for i in range(Ppool):
place = random.sample([_ for _ in range(Ppool)], 2)
parent1 = copy.deepcopy(Gparent[place[0]])
parent2 = copy.deepcopy(Gparent[place[1]])
parent3 = copy.deepcopy(parent2)
if random.random() < Pc:
num = random.sample([_ for _ in range(1, 32, 1)], 2)
num.sort()
if random.random() < 0.5:
for j in range(num[0], num[1], 1):
parent2.x[j] = parent1.x[j]
else:
for j in range(0, num[0], 1):
parent2.x[j] = parent1.x[j]
for j in range(num[1], 33, 1):
parent2.x[j] = parent1.x[j]
num = random.sample([_ for _ in range(1, 32, 1)], 2)
num.sort()
num.sort()
if random.random() < 0.5:
for j in range(num[0], num[1], 1):
parent1.x[j] = parent3.x[j]
else:
for j in range(0, num[0], 1):
parent1.x[j] = parent3.x[j]
for j in range(num[1], 33, 1):
parent1.x[j] = parent3.x[j]
for j in range(33):
if random.random() < Pm:
parent1.x[j] = (parent1.x[j] + 1) % 2
if random.random() < Pm:
parent2.x[j] = (parent2.x[j] + 1) % 2
parent1.fitness = Cal_fit(parent1.x, upper, lower)
parent2.fitness = Cal_fit(parent2.x, upper, lower)
Gchild[2 * i] = copy.deepcopy(parent1)
Gchild[2 * i + 1] = copy.deepcopy(parent2)
def Choose_next(G, Gchild, Gsum, Pop): #选择下一代函数
for i in range(Pop):
Gsum[i] = copy.deepcopy(G[i])
Gsum[2 * i + 1] = copy.deepcopy(Gchild[i])
Gsum = sorted(Gsum, key = lambda x: x.fitness, reverse = True)
for i in range(Pop):
G[i] = copy.deepcopy(Gsum[i])
G[i].place = i
def Decode(x): #解码函数
Temp1 = 0
for i in range(18):
Temp1 += x[i] * math.pow(2, i)
Temp2 = 0
for i in range(18, 33, 1):
Temp2 += math.pow(2, i - 18) * x[i]
x1 = lower[0] + Temp1 * (upper[0] - lower[0]) / (math.pow(2, 18) - 1)
x2 = lower[1] + Temp2 * (upper[1] - lower[1]) / (math.pow(2, 15) - 1)
if x1 > upper[0]:
x1 = random.uniform(lower[0], upper[0])
if x2 > upper[1]:
x2 = random.uniform(lower[1], upper[1])
return x1, x2
def Self_Learn(Best, upper, lower, sPm, sLearn): #自学习操作
num = 0
Temp = copy.deepcopy(Best)
while True:
num += 1
for j in range(33):
if random.random() < sPm:
Temp.x[j] = (Temp.x[j] + 1)%2
Temp.fitness = Cal_fit(Temp.x, upper, lower)
if Temp.fitness > Best.fitness:
Best = copy.deepcopy(Temp)
num = 0
if num > sLearn:
break
return Best
if __name__ == '__main__':
upper = [12.1, 5.8]
lower = [-3, 4.1]
Pop = 100
Ppool = 50
G_max = 300
Pc = 0.8
Pm = 0.1
sPm = 0.05
sLearn = 20
G = np.array([Ind() for _ in range(Pop)])
Gparent = np.array([Ind() for _ in range(Ppool)])
Gchild = np.array([Ind() for _ in range(Pop)])
Gsum = np.array([Ind() for _ in range(Pop * 2)])
Init(G, upper, lower, Pop) #初始化
Best = Find_Best(G, Pop)
for k in range(G_max):
Selection(G, Gparent, Pop, Ppool) #使用轮盘赌方法选择其中50%为父代
Cross_and_Mutation(Gparent, Gchild, Pc, Pm, upper, lower, Pop, Ppool) #交叉和变异生成子代
Choose_next(G, Gchild, Gsum, Pop) #选择出父代和子代中较优秀的个体
Cbest = Find_Best(G, Pop)
if Best.fitness < Cbest.fitness:
Best = copy.deepcopy(Cbest) #跟新最优解
else:
G[Cbest.place] = copy.deepcopy(Best)
Best = Self_Learn(Best, upper, lower, sPm, sLearn)
print(Best.fitness)
x1, x2 = Decode(Best.x)
print(Best.x)
print([x1, x2])
以上这篇Python实现遗传算法(二进制编码)求函数最优值方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
TensorFlow 多元函数的极值实例
flyfish python实现 设函数 的某个邻域内有定义,对于该邻域内异于的点,如果都适合不等式 则称函数在点有极大值. 如果都适合不等式 则称函数在点有极小值. 极大值.极小值统称为极值.使函数取得极值的点称为极值点. 有极小值的例子 函数 在点(0,0)处有极小值.因为对于点 (0,0)的任一邻域内异于(0,0)的点,函数值都为正,而在点(0,0)处的函数值为零.从几何上看这是显然的,因为点(0,0,0)是开口朝上的椭圆抛物面 的顶点. 代码 from matplotlib import
-
使用Python实现牛顿法求极值
对于一个多元函数 用牛顿法求其极小值的迭代格式为 其中 为函数 的梯度向量, 为函数 的Hesse(Hessian)矩阵. 上述牛顿法不是全局收敛的.为此可以引入阻尼牛顿法(又称带步长的牛顿法). 我们知道,求极值的一般迭代格式为 其中 为搜索步长, 为搜索方向(注意所有的迭代格式都是先计算搜索方向,再计算搜索步长,如同瞎子下山一样,先找到哪个方向可行下降,再决定下几步). 取下降方向 即得阻尼牛顿法,只不过搜索步长 不确定,需要用线性搜索技术确定一个较优的值,比如精确线性搜索或者Goldste
-
python 遗传算法求函数极值的实现代码
废话不多说,大家直接看代码吧! """遗传算法实现求函数极大值-Zjh""" import numpy as np import random import matplotlib.pyplot as plt class Ga(): """求出二进制编码的长度""" def __init__(self): self.boundsbegin = -2 self.boundsend = 3 p
-
Python实现遗传算法(二进制编码)求函数最优值方式
目标函数 编码方式 本程序采用的是二进制编码精确到小数点后五位,经过计算可知对于 其编码长度为18,对于 其编码长度为15,因此每个基于的长度为33. 参数设置 算法步骤 设计的程序主要分为以下步骤:1.参数设置:2.种群初始化:3.用轮盘赌方法选择其中一半较好的个体作为父代:4.交叉和变异:5.更新最优解:6.对最有个体进行自学习操作:7结果输出.其算法流程图为: 算法结果 由程序输出可知其最终优化结果为38.85029, 输出基因编码为[1 1 0 0 1 0 1 1 1 1 1 1 1 0
-
python装饰器相当于函数的调用方式
1. 普通装饰器 import logging 1. foo = use_loggine(foo) def use_loggine(func): def wrapper(): logging.warn("%s is running " % func.__name__) return func() return wrapper @use_loggine def foo(): print "aaa" foo() print foo.__name__ 2. func 需要
-
利用jupyter网页版本进行python函数查询方式
我就废话不多说了,还是直接看代码吧! import numpy world_alchol=numpy.genfromtxt("world_alcohol.txt",delimter=".",dtype=str) print(type(world_alcohol)) print(world_alcohol) print(help(numpy.genfromtxt)) 实现函数查询. 补充知识:Jupyter Notebook 中查看当前 运行哪个python 在运行
-
python 轮询执行某函数的2种方式
目标:python中每隔特定时间执行某函数 方法1:使用python的Thread类的子类Timer,该子类可控制指定函数在特定时间后执行一次: 所以为了实现多次定时执行某函数,只需要在一个while循环中多次新建Timer即可. from threading import Timer import time def printHello(): print ("Hello") print("当前时间戳是", time.time()) def loop_func(fu
-
python微元法计算函数曲线长度的方法
计算曲线长度,根据线积分公式: ,令积分函数 f(x,y,z) 为1,即计算曲线的长度,将其微元化: 其中 根据此时便可在python编程实现,给出4个例子,代码中已有详细注释,不再赘述 ''' 计算曲线长度,根据线积分公式: \int_A^Bf(x,y,z)dl,令积分函数为1,即计算曲线的长度 ''' import numpy as np from mpl_toolkits.mplot3d import * import matplotlib.pyplot as plt ## 求二维圆周长,
-

书写Python代码的一种更优雅方式(推荐!)
目录 1 简介 2 在Python中配合pipe灵活使用链式写法 2.1 pipe中常用的管道操作函数 2.1.1 使用traverse()展平嵌套数组 2.1.2 使用dedup()进行顺序去重 2.1.3 使用filter()进行值过滤 2.1.4 使用groupby()进行分组运算 2.1.5 使用select()对上一步结果进行自定义遍历运算 2.1.6 使用sort()进行排序 总结 1 简介 一些比较熟悉pandas的读者朋友应该经常会使用query().eval().pipe().
-
简单了解Python中的几种函数
几个特殊的函数(待补充) python是支持多种范型的语言,可以进行所谓函数式编程,其突出体现在有这么几个函数: filter.map.reduce.lambda.yield lambda >>> g = lambda x,y:x+y #x+y,并返回结果 >>> g(3,4) 7 >>> (lambda x:x**2)(4) #返回4的平方 16 lambda函数的使用方法: 在lambda后面直接跟变量 变量后面是冒号 冒号后面是表达式,表达式计算
-
详解python里使用正则表达式的分组命名方式
详解python里使用正则表达式的分组命名方式 分组匹配的模式,可以通过groups()来全部访问匹配的元组,也可以通过group()函数来按分组方式来访问,但是这里只能通过数字索引来访问,如果某一天产品经理需要修改需求,让你在它们之中添加一个分组,这样一来,就会导致匹配的数组的索引的变化,作为开发人员的你,必须得一行一行代码地修改.因此聪明的开发人员又想到一个好方法,把这些分组进行命名,只需要对名称进行访问分组,不通过索引来访问了,就可以避免这个问题.那么怎么样来命名呢?可以采用(?P<nam
-
Python基于time模块求程序运行时间的方法
本文实例讲述了Python基于time模块求程序运行时间的方法.分享给大家供大家参考,具体如下: 要记录程序的运行时间可以利用Unix系统中,1970.1.1到现在的时间的毫秒数,这个时间戳轻松完成. 方法是程序开始的时候取一次存入一个变量,在程序结束之后取一次再存入一个变量,与程序开始的时间戳相减则可以求出. Python中取这个时间戳的方法为引入time类之后,使用time.time();就能够拿出来.也就是Java中的System.currentTimeMillis(). 由于Python