Dubbo实现分布式日志链路追踪
技术场景
在日常的开发、测试或运维的过程中,经常存在这样的场景,开发人员在代码中使用日志工具(log4j、slf4j)记录日志,比如请求ID、IP等,方便在线上快速、精准的定位问题,通过完整的日志链路清晰的进行信息定位。
一般的项目都是分层的、分布式的,在众多的日志信息中,如何区分哪些日志信息是同一请求发出来的,详细的实现如下。
技术框架
项目框架:Spring boot
分布式协调:Zookeeper、Dubbo
日志工具:Sf4j
构建工具:Maven
开发工具:IDEA
项目框架

mdc-dubbo-api:接口服务
mdc-dubbo-provider:服务端服务
mdc-dubbo-consumer:消费端服务
项目配置
mdc-dubbo-api
提供一个接口
public interface OrderService {
String getOrder(String orderid);
}
mdc-dubbo-consumer
在服务端,在Controller层使用MDC工具类放入一个TRACE_LOG_ID信息,在此请求的service层、mdc-dubbo-provider中使用该信息。
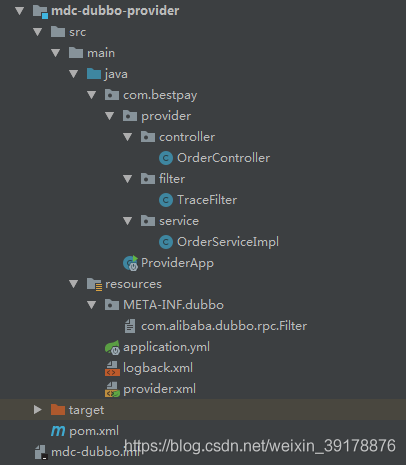
项目分为Controller、Service、Filter等各层:
Controller层:存放TRACE_LOG_ID, 打印
@GetMapping("get/{id}")
public String get(@PathVariable("id") String id){
String uuid = UUID.randomUUID().toString().replaceAll("-", "");
MDC.put(Constants.TRACE_LOG_ID, uuid);
LOGGER.info("controller->param:{}", id);
return consumerService.getName(id);
}
Service层:打印TRACE_LOG_ID
@Override
public String getName(String id) {
LOGGER.info("consumer->service->param:{}", id);
return orderService.getOrder(id);
}
Filter:
public class TraceFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
//从MDC中获取
String logId = MDC.get(Constants.TRACE_LOG_ID);
Map<String, String> attachments = invocation.getAttachments();
attachments.put(Constants.TRACE_LOG_ID, logId);
return invoker.invoke(invocation);
}
需要过滤器配置在resources->MATE-INF->dobbo文件夹下
![过滤器配置https://img-blog.csdnimg.cn/20181219100406136.png)
traceFilter=com.bestpay.provider.filter.TraceFilter
此处注意 此处使用到了Dubbo中spi机制,文件名必须是com.alibaba.dubbo.rpc.Filter
dubbo配置文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:dubbo="http://code.alibabatech.com/schema/dubbo"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://code.alibabatech.com/schema/dubbo
http://code.alibabatech.com/schema/dubbo/dubbo.xsd">
<!--过滤器配置-->
<!-- <dubbo:provider filter="traceFilter" />-->
<!-- 应用名-->
<dubbo:application name="dmc-dubbo-provider"/>
<!--zookeeper注册中心-->
<dubbo:registry address="zookeeper://127.0.0.1:2181"/>
<dubbo:protocol name="dubbo" port="20880"/>
<!--服务注册-->
<dubbo:service interface="com.bestpay.service.OrderService" ref="orderService" timeout="10000" **filter="traceFilter"**/>
<bean id="orderService" class="com.bestpay.provider.service.OrderServiceImpl" />
</beans>
其中filter="traceFilter是引用dobbo目录下配置中的key
logback配置
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>[%date{yyyy-MM-dd HH:mm:ss}] [%-5level] %logger %line --%mdc{client} [%X{TRACE_LOG_ID}] %msg%n</pattern>
<!-- 控制台也要使用UTF-8,不要使用GBK,否则会中文乱码 -->
<charset>UTF-8</charset>
</encoder>
</appender>
TRACE_LOG_ID对应放入MDC中的key
mdc-dubbo-provider
配置和## mdc-dubbo-consumer类似,其中在Filter上稍微有些差别
public class TraceFilter implements Filter {
@Override
public Result invoke(Invoker<?> invoker, Invocation invocation) throws RpcException {
String logId = invocation.getAttachment(Constants.TRACE_LOG_ID);
MDC.put(Constants.TRACE_LOG_ID, logId);
return invoker.invoke(invocation);
}
}
项目运行
mdc-dubbo-consumer日志:
[2018-12-19 10:16:56] [INFO ] com.bestpay.comsumer.controller.ConsumerController 33 – [d88ecba6581c47b1b3ade78d2821d13a] controller->param:223
[2018-12-19 10:16:56] [INFO ] com.bestpay.comsumer.service.impl.ComsumerServiceImpl 20 – [d88ecba6581c47b1b3ade78d2821d13a] consumer->service->param:223mdc-dubbo-provider日志:
[2018-12-19 10:16:56] [INFO ] com.bestpay.provider.service.OrderServiceImpl 13 – [d88ecba6581c47b1b3ade78d2821d13a] provider->service->param:223
以上,完成了dubbo分布式服务之间日志的完整链路。为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
详解spring cloud分布式日志链路跟踪
首先要明白一点,为什么要使用链路跟踪? 当我们微服务之间调用的时候可能会出错,但是我们不知道是哪个服务的问题,这时候就可以通过日志链路跟踪发现哪个服务出错. 它还有一个好处:当我们在企业中,可能每个人都负责一个服务,我们可以通过日志来检查自己所负责的服务不会出错,当调用其它服务时,这时候出现错误,那么就可以判定出不是自己的服务出错,从而也可以发现责任不是自己的. 基于微服务之间的调用开始,如果看不懂的小伙伴,请先参考我上篇博客:spring cloud中微服务之间的调用以及eureka的自我保护
-
spring cloud 分布式链路追踪的方法
一篇讲了微服务之间的调用spring cloud eureka 微服务之间的调用 微服务之间进行调用 那么如果我负责一个模块 别人负责另一个模块 我调用了他的方法 测试那边却报了错 那是我的问题还是他的问题 这个时候大家应该就能想到日志可以解决这个问题 如何使用日志呢 先在配置文件中加 logging: path: D:\logs\poppy-mall #日志的存放地址 最好再加个项目名的文件夹 可以更容易的区分 level: org.poppy.mall: info #日志的级别 org.po
-
springboot整合dubbo设置全局唯一ID进行日志追踪的示例代码
1.新建项目 利用idea创建一个父项目,三个子项目,其中一个项目为生产者,一个项目为消费者,一个为接口等公共服务项目,生产者和消费者需要有web依赖,可以作为tomcat容器启动. 2.项目依赖 <dependencies> <dependency> <groupId>org.apache.dubbo</groupId> <artifactId>dubbo-spring-boot-starter</artifactId> <v
-
SpringBoot+Dubbo+Seata分布式事务实战详解
前言 Seata 是 阿里巴巴开源的分布式事务中间件,以高效并且对业务0侵入的方式,解决微服务场景下面临的分布式事务问题. 事实上,官方在GitHub已经给出了多种环境下的Seata应用示例项目,地址:https://github.com/seata/seata-samples. 为什么笔者要重新写一遍呢,主要原因有两点: 官网代码示例中,依赖太多,分不清哪些有什么作用 Seata相关资料较少,笔者在搭建的过程中,遇到了一些坑,记录一下 一.环境准备 本文涉及软件环境如下: SpringBoot
-

Dubbo实现分布式日志链路追踪
技术场景 在日常的开发.测试或运维的过程中,经常存在这样的场景,开发人员在代码中使用日志工具(log4j.slf4j)记录日志,比如请求ID.IP等,方便在线上快速.精准的定位问题,通过完整的日志链路清晰的进行信息定位. 一般的项目都是分层的.分布式的,在众多的日志信息中,如何区分哪些日志信息是同一请求发出来的,详细的实现如下. 技术框架 项目框架:Spring boot 分布式协调:Zookeeper.Dubbo 日志工具:Sf4j 构建工具:Maven 开发工具:IDEA 项目框架 mdc-
-
SpringBoot 项目添加 MDC 日志链路追踪的执行流程
目录 1. 线程池配置 2. 拦截器配置 3. 日志文件配置 4. 使用方法示例 4.1. 异步使用 4.2. 定时任务 日志链路追踪的意思就是将一个标志跨线程进行传递,在一般的小项目中也就是在你新起一个线程的时候,或者使用线程池执行任务的时候会用到,比如追踪一个用户请求的完整执行流程. 这里用到MDC和ThreadLocal,分别由下面的包提供: java.lang.ThreadLocal org.slf4j.MDC 直接上代码: 1. 线程池配置 如果你直接通过手动新建线程来执行异步任务,想
-
ASP.Net Core中的日志与分布式链路追踪
目录 .NET Core 中的日志 控制台输出 非侵入式日志 Microsoft.Extensions.Logging ILoggerFactory ILoggerProvider ILogger Logging Providers 怎么使用 日志等级 Trace.Debug 链路跟踪 OpenTracing 上下文和跟踪功能 跟踪单个功能 将多个跨度合并到一条轨迹中 传播过程中的上下文 分布式链路跟踪 在不同进程中跟踪 在 ASP.NET Core 中跟踪 OpenTracing API 和
-
skywalking分布式服务调用链路追踪APM应用监控
目录 前言 skywalking是什么,有什么用? skywalaking总体架构分为三部分 如何快速开始? 第一步:进入官方release地址 第二步:配置需要监控的应用的agent探针 系统使用图例 其他 前言 当企业应用进入分布式微服务时代,应用服务依赖会越来越多,skywalking可以很好的解决服务调用链路追踪的问题,而且基于java探针技术,基本对应用零侵入零耦合. skywalking是什么,有什么用? Skywalking 是一个APM系统,即应用性能监控系统,为微服务架构和云原
-
微服务分布式架构实现日志链路跟踪的方法
Logback 背景 Logback是由log4j创始人设计的另一个开源日志组件,官方网站:http://logback.qos.ch.它当前分为下面下个模块: logback-core:其它两个模块的基础模块 logback-classic:它是log4j的一个改良版本,同时它完整实现了slf4j API使你可以很方便地更换成其它日志系统如log4j或JDK14 Logging logback-access:访问模块与Servlet容器集成提供通过Http来访问日志的功能 普通debug日志
-
.NET Core分布式链路追踪框架的基本实现原理
分布式追踪 什么是分布式追踪 分布式系统 当我们使用 Google 或者 百度搜索时,查询服务会将关键字分发到多台查询服务器,每台服务器在自己的索引范围内进行搜索,搜索引擎可以在短时间内获得大量准确的搜索结果:同时,根据关键字,广告子系统会推送合适的相关广告,还会从竞价排名子系统获得网站权重.通常一个搜索可能需要成千上万台服务器参与,需要经过许多不同的系统提供服务. 多台计算机通过网络组成了一个庞大的系统,这个系统即是分布式系统. 在微服务或者云原生开发中,一般认为分布式系统是通过各种中间件/服
-
.NET Core分布式链路追踪框架的基本实现原理
目录 分布式追踪 什么是分布式追踪 分布式系统 分布式追踪 分布式追踪有什么用呢 Dapper 分布式追踪系统的实现 跟踪树和 span Jaeger 和 OpenTracing OpenTracing Jaeger 结构 OpenTracing 数据模型 Span 格式 Trace Span OpenTracing API 分布式追踪 什么是分布式追踪 分布式系统 当我们使用 Google 或者 百度搜索时,查询服务会将关键字分发到多台查询服务器,每台服务器在自己的索引范围内进行搜索,搜索引擎
-
Go 分布式链路追踪实现原理解析
目录 为什么需要分布式链路追踪系统 微服务架构给运维.排障带来新挑战 分布式链路追踪系统如何帮助我们 分布式链路追踪系统架构概览 核心概念 一般架构 协议标准和开源实现 应用侧调用链跟踪实现方案概览 应用侧核心任务 基于 OTEL 库实现调用拦截 HttpServer Handler 生成 Span 过程 HttpClient 请求生成 Span 过程 基于 OTEL 库实现调用链跟踪总结 非侵入调用链跟踪实现思路 Go 非侵入链路追踪实现原理 在分布式.微服务架构下,应用一个请求往往贯穿多个分