JVM中四种GC算法案例详解
目录
- 介绍
- 引用计数算法(Reference counting)
- 算法思想:
- 核心思想:
- 优点:
- 缺点:
- 例子如图:
- 标记–清除算法(Mark-Sweep)
- 算法思想:
- 优点
- 缺点
- 例子如图
- 标记–整理算法
- 算法思想
- 优点
- 缺点
- 例子
- 复制算法
- 算法思想
- 优点
- 缺点
- 总结
介绍
程序在运行过程中,会产生大量的内存垃圾(一些没有引用指向的内存对象都属于内存垃圾,因为这些对象已经无法访问,程序用不了它们了,对程序而言它们已经死亡),为了确保程序运行时的性能,java虚拟机在程序运行的过程中不断地进行自动的垃圾回收(GC)。关于 JVM 的 GC 算法主要有下面四种:
引用计数算法(Reference counting)
算法思想:
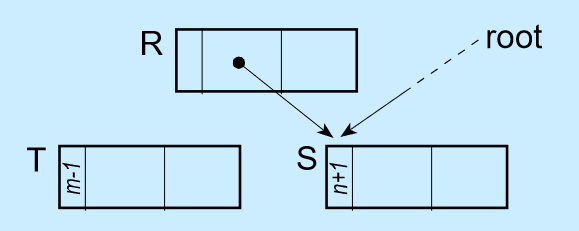
每个对象在创建的时候,就给这个对象绑定一个计数器。每当有一个引用指向该对象时,计数器加一;每当有一个指向它的引用被删除时,计数器减一。这样,当没有引用指向该对象时,该对象死亡,计数器为0,这时就应该对这个对象进行垃圾回收操作。
核心思想:
为每个对象额外存储一个计数器 RC ,根据 RC 的值来判断对象是否死亡,从而判断是否执行 GC 操作。
优点:
- 简单
- 计算代价分散
- “幽灵时间”短(幽灵时间指对象死亡到回收的这段时间,处于幽灵状态)
缺点:
- 不全面(容易漏掉循环引用的对象)
- 并发支持较弱
- 占用额外内存空间
例子如图:
初始状态:
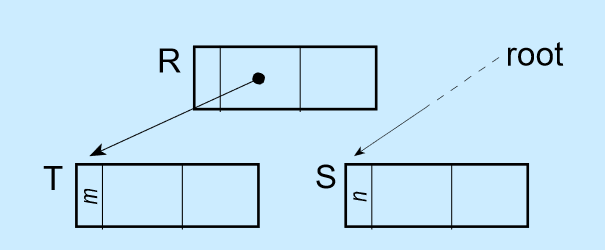
改变引用后:
标记–清除算法(Mark-Sweep)
算法思想:
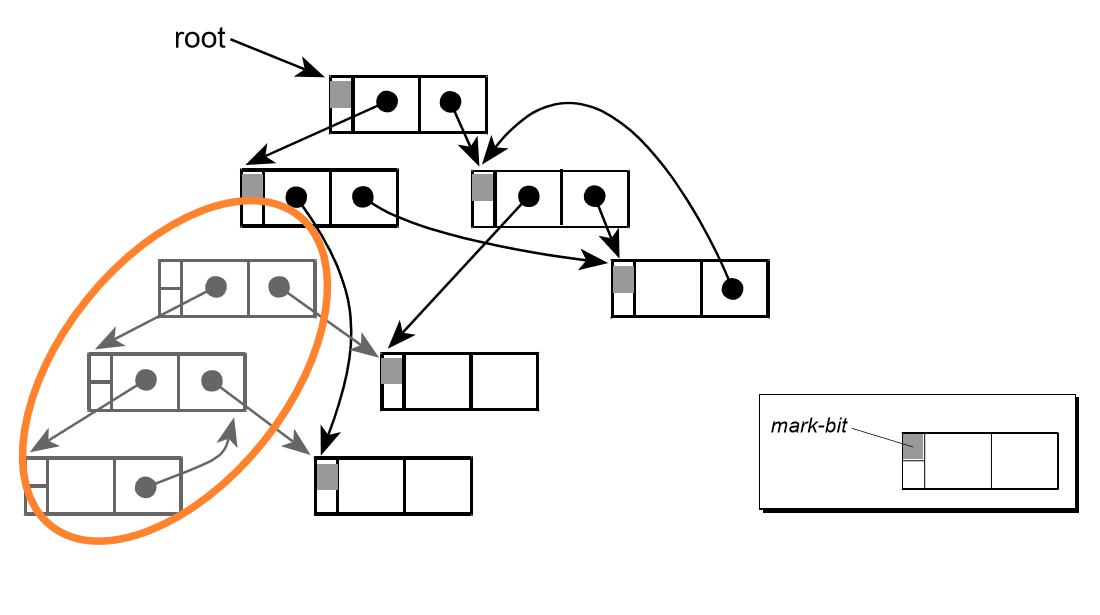
为每个对象存储一个标记位,记录对象的状态(活着或是死亡)。分为两个阶段,一个是标记阶段,这个阶段内,为每个对象更新标记位,检查对象是否死亡;第二个阶段是清除阶段,该阶段对死亡的对象进行清除,执行 GC 操作。
优点
- 最大的优点是,相比于引用计数法,标记—清除算法中每个活着的对象的引用只需要找到一个即可,找到一个就可以判断它为活的。
- 此外,这个算法相比于引用计数法更全面,在指针操作上也没有太多的花销。更重要的是,这个算法并不移动对象的位置(后面俩算法涉及到移动位置的问题)。
缺点
- 很长的幽灵时间,判断对象已经死亡,消耗了很多时间,这样从对象死亡到对象被回收之间的时间过长。
- 每个活着的对象都要在标记阶段遍历一遍;所有对象都要在清除阶段扫描一遍,因此算法复杂度较高。
- 没有移动对象,导致可能出现很多碎片空间无法利用的情况。
例子如图
这个图中,圆圈内灰色的对象就是已经死亡的对象,被标记为死亡,等待清除。
标记–整理算法
算法思想
标记-整理法是标记-清除法的一个改进版。同样,在标记阶段,该算法也将所有对象标记为存活和死亡两种状态;不同的是,在第二个阶段,该算法并没有直接对死亡的对象进行清理,而是将所有存活的对象整理一下,放到另一处空间,然后把剩下的所有对象全部清除。这样就达到了标记-整理的目的。
优点
- 该算法不会像标记-清除算法那样产生大量的碎片空间。
缺点
- 如果存活的对象过多,整理阶段将会执行较多复制操作,导致算法效率降低。
例子
如图:

上面是标记阶段,下面是整理之后的状态。可以看到,该算法不会产生大量碎片内存空间。
复制算法
算法思想
该算法将内存平均分成两部分,然后每次只使用其中的一部分,当这部分内存满的时候,将内存中所有存活的对象复制到另一个内存中,然后将之前的内存清空,只使用这部分内存,循环下去。
注意:
这个算法与标记-整理算法的区别在于,该算法不是在同一个区域复制,而是将所有存活的对象复制到另一个区域内。
优点
- 实现简单
- 不产生内存碎片
缺点
- 每次运行,总有一半内存是空的,导致可使用的内存空间只有原来的一半。
总结
不同算法有不同的优点和缺点,除了引用计数法不常用外,其他三种算法在现在的java虚拟机上也是很常见的,间接说明了这几个经典算法还是有其适用性的。
理解 JVM 的 GC 算法能够帮助我们更好地理解java的垃圾回收机制,例如,在 JVM 的年轻代使用的是复制算法来进行垃圾回收(由于其中的存活对象比例较小);而在老年代,使用的却是标记-清除法或标记-整理法(由于每次回收都只回收少量对象)
到此这篇关于JVM中四种GC算法案例详解的文章就介绍到这了,更多相关JVM中四种GC算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

java基础学习JVM中GC的算法
在java学习到JVM时候,总会很多朋友问到关于GC算法的问题,小编在此给大家整理关于JVM中GC算法的原理以及图文详细分析,希望能够帮助你对这个GC算法的理解. JVM内存组成结构: (1)堆 所有通过new创建的对象都是在堆中分配内存,其大小可以通过-Xmx和-Xms来控制,堆被划分为新生代和旧生代,新生代又被进一步划分为Eden和Survivor区.Survivor被划分为from space 和 to space组成,结构图如下: (2)栈 每个线程 执行每个方法的时候都会在栈中申请一个
-
从JVM的内存管理角度分析Java的GC垃圾回收机制
一个优秀的Java程序员必须了解GC的工作原理.如何优化GC的性能.如何与GC进行有限的交互,因为有一些应用程序对性能要求较高,例如嵌入式系统.实时系统等,只有全面提升内存的管理效率 ,才能提高整个应用程序的性能.本篇文章首先简单介绍GC的工作原理之后,然后再对GC的几个关键问题进行深入探讨,最后提出一些Java程序设计建议,从GC角度提高Java程序的性能. GC的基本原理 Java的内存管理实际上就是对象的管理,其中包括对象的分配和释放. 对于程序员来说,分配对象使用
-
详解JVM中的GC调优
那些GC的默认值 其实GC或者说JVM的参数非常非常的多,有控制内存使用的: 有控制JIT的: 有控制分代比例的,也有控制GC并发的: 当然,大部分的参数其实并不需要我们自行去调整,JVM会很好的动态帮我们设置这些变量的值. 如果我们不去设置这些值,那么对GC性能比较有影响的参数和他们的默认值有哪些呢? GC的选择 我们知道JVM中的GC有很多种,不同的GC选择对java程序的性能影响还是比较大的. 在JDK9之后,G1已经是默认的垃圾回收器了. 我们看一下G1的调优参数. G1是基于分代技术的
-
JVM中四种GC算法案例详解
目录 介绍 引用计数算法(Reference counting) 算法思想: 核心思想: 优点: 缺点: 例子如图: 标记–清除算法(Mark-Sweep) 算法思想: 优点 缺点 例子如图 标记–整理算法 算法思想 优点 缺点 例子 复制算法 算法思想 优点 缺点 总结 介绍 程序在运行过程中,会产生大量的内存垃圾(一些没有引用指向的内存对象都属于内存垃圾,因为这些对象已经无法访问,程序用不了它们了,对程序而言它们已经死亡),为了确保程序运行时的性能,java虚拟机在程序运行的过程中不断地进行
-
Java DFA算法案例详解
1.背景 项目中需要对敏感词做一个过滤,首先有几个方案可以选择: 直接将敏感词组织成String后,利用indexOf方法来查询. 传统的敏感词入库后SQL查询. 利用Lucene建立分词索引来查询. 利用DFA算法来进行. 首先,项目收集到的敏感词有几千条,使用a方案肯定不行.其次,为了方便以后的扩展性尽量减少对数据库的依赖,所以放弃b方案.然后Lucene本身作为本地索引,敏感词增加后需要触发更新索引,并且这里本着轻量原则不想引入更多的库,所以放弃c方案.于是我们选定d方案为研究目标. 2.
-
C++中std::allocator的使用案例详解
标准库中包含一个名为allocator的类,允许我们将分配和初始化分离.使用allocator通常会提供更好的性能和更灵活的内存管理能力. new有一些灵活性上的局限,其中一方面表现在它将内存分配和对象构造组合在了一起.类似的,delete将对象析构和内存释放组合在了一起.我们分配单个对象时,通常希望将内存分配和对象初始化组合在一起.因为在这种情况下,我们几乎肯定知道对象应有什么值.当分配一大块内存时,我们通常计划在这块内存上按需构造对象.在此情况下,我们希望将内存分配和对象构造
-
java 中模式匹配算法-KMP算法实例详解
java 中模式匹配算法-KMP算法实例详解 朴素模式匹配算法的最大问题就是太低效了.于是三位前辈发表了一种KMP算法,其中三个字母分别是这三个人名的首字母大写. 简单的说,KMP算法的对于主串的当前位置不回溯.也就是说,如果主串某次比较时,当前下标为i,i之前的字符和子串对应的字符匹配,那么不要再像朴素算法那样将主串的下标回溯,比如主串为"abcababcabcabcabcabc",子串为"abcabx".第一次匹配的时候,主串1,2,3,4,5字符都和子串相应的
-
MySQL 四种事务隔离级别详解及对比
MySQL 四种事务隔离级别详解及对比 按照SQL:1992 事务隔离级别,InnoDB默认是可重复读的(REPEATABLE READ).MySQL/InnoDB 提供SQL标准所描述的所有四个事务隔离级别.你可以在命令行用--transaction-isolation选项,或在选项文件里,为所有连接设置默认隔离级别. 例如,你可以在my.inf文件的[mysqld]节里类似如下设置该选项: transaction-isolation = {READ-UNCOMMITTED | READ-CO
-
C语言实现BF算法案例详解
BF算法: BF算法即暴风算法,是普通的模式匹配算法.BF算法的思想:将目标串S的第一个字符与模式串T的第一个字符进行匹配,若相等,则继续比较S的第二个字符和 T的第二个字符:若不相等,则比较S的第二个字符和T的第一个字符,依次比较下去,直到得出最后的匹配结果.BF算法是一种蛮力算法. 图示: #include <stdio.h> #include <string.h> int BF(const char *s, const char* sub, int pos)//
-
Python 中闭包与装饰器案例详解
项目github地址:bitcarmanlee easy-algorithm-interview-and-practice 1.Python中一切皆对象 这恐怕是学习Python最有用的一句话.想必你已经知道Python中的list, tuple, dict等内置数据结构,当你执行: alist = [1, 2, 3] 时,你就创建了一个列表对象,并且用alist这个变量引用它: 当然你也可以自己定义一个类: class House(object): def __init__(self, are
-
Python 经典贪心算法之Prim算法案例详解
最小生成树的Prim算法也是贪心算法的一大经典应用.Prim算法的特点是时刻维护一棵树,算法不断加边,加的过程始终是一棵树. Prim算法过程: 一条边一条边地加, 维护一棵树. 初始 E = {}空集合, V = {任选的一个起始节点} 循环(n – 1)次,每次选择一条边(v1,v2), 满足:v1属于V , v2不属于V.且(v1,v2)权值最小. E = E + (v1,v2) V = V + v2 最终E中的边是一棵最小生成树, V包含了全部节点. 以下图为例介绍Prim算法的执行过程
-
Java解析XML(4种方式)案例详解
目录 1.DOM方式 2.SAX方式 3.JDOM方式 4.DOM4J方式 总结 xml文件 <?xml version="1.0" encoding="utf-8" ?> <class> <student> <firstname>cxx1</firstname> <lastname>Bob1</lastname> <nickname>stars1</nicknam
-
Python中的tkinter库简单案例详解
目录 案例一 Label & Button 标签和按钮 案例二 Entry & Text 输入和文本框 案例三 Listbox 部件 案例四 Radiobutton 选择按钮 案例五 Scale 尺度 案例六 Checkbutton 勾选项 案例七 Canvas 画布 案例八 Menubar 菜单 案例九 Frame 框架 案例十 messagebox 弹窗 案例十一 pack grid place 放置 登录窗口 TKinterPython 的 GUI 库非常多,之所以选择 Tkinte