C#中实现PriorityQueue优先级队列的代码
前言
前段时间看到有大佬对.net 6.0新出的PriorityQueue(优先级队列)数据结构做了解析,但是没有源码分析,所以本着探究源码的心态,看了看并分享出来。它不像普通队列先进先出(FIFO),而是根据优先级出队。
ps:读者多注意代码的注释。
D叉树的认识(d-ary heap)
首先我们在表示一个堆(大顶堆或小顶堆)的时候,实际上是通过一个一维数组来维护一个二叉树(d=2,d表示每个父节点最多有几个子节点),首先看下图的二叉树,数字代表索引:
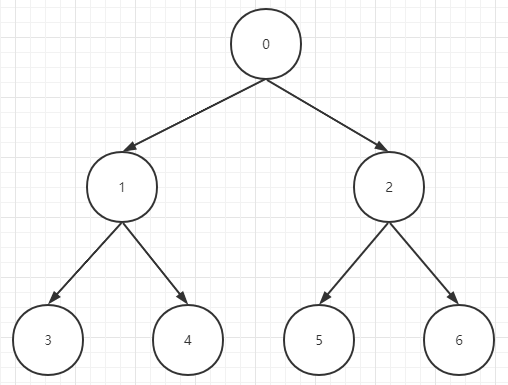
任意一个节点的父节点的索引为:(index - 1) / d任意一个节点的左子节点的索引为:(index * d) + 1任意一个节点的右子节点的索引为:(index * d) + 2它的时间复杂度为O(logndn)
通过以上公式,我们就可以轻松通过一个数组来表达一个堆,只需保证能拿到正确的索引即可进行快速的插入和删除。
源码解析
构造初始化
关于这部分主要介绍关键的字段和方法,比较器的初始化以及堆的初始化,请看如下代码:
public class PriorityQueue<TElement, TPriority>
{
/// <summary>
/// 保存所有节点的一维数组且每一项是个元组
/// </summary>
private (TElement Element, TPriority Priority)[] _nodes;
/// <summary>
/// 优先级比较器,这里用的泛型,比较器可以自己实现
/// </summary>
private readonly IComparer<TPriority>? _comparer;
/// <summary>
/// 当前堆的大小
/// </summary>
private int _size;
/// <summary>
/// 版本号
/// </summary>
private int _version;
/// <summary>
/// 代表父节点最多有4个子节点,也就是d=4(d=4时好像效率最高)
/// </summary>
private const int Arity = 4;
/// <summary>
/// 使用位运算符,表示左移2或右移2(效率更高),即相当于除以4,
/// </summary>
private const int Log2Arity = 2;
/// <summary>
/// 构造函数初始化堆和比较器
/// </summary>
public PriorityQueue()
{
_nodes = Array.Empty<(TElement, TPriority)>();
_comparer = InitializeComparer(null);
}
/// <summary>
/// 重载构造函数,来定义比较器否则使用默认的比较器
/// </param>
public PriorityQueue(IComparer<TPriority>? comparer)
{
_nodes = Array.Empty<(TElement, TPriority)>();
_comparer = InitializeComparer(comparer);
}
private static IComparer<TPriority>? InitializeComparer(IComparer<TPriority>? comparer)
{
//如果是值类型,如果是默认比较器则返回null
if (typeof(TPriority).IsValueType)
{
if (comparer == Comparer<TPriority>.Default)
{
return null;
}
return comparer;
}
//否则就使用自定义的比较器
else
{
return comparer ?? Comparer<TPriority>.Default;
}
}
/// <summary>
/// 获取索引的父节点
/// </summary>
private int GetParentIndex(int index) => (index - 1) >> Log2Arity;
/// <summary>
/// 获取索引的左子节点
/// </summary>
private int GetFirstChildIndex(int index) => (index << Log2Arity) + 1;
}
单元总结:
- 实际所有元素使用一维数组来维护这个堆。
- 调用方可以自定义比较器,但是类型得一致。
- 如果没有比较器,则使用默认的比较器。
- 默认一个父节点最多有4个子节点,D=4时效率好像是最好的。
- 获取父节点索引位置和子节点索引位置使用位运算符,效率更高。
入队操作
入队操作操作相对简单,主要是做扩容和插入处理,请看如下代码:
public void Enqueue(TElement element, TPriority priority)
{
//拿到最大位置的索引,然后再将数组长度+1
int currentSize = _size++;
_version++;
//如果长度相等,说明已经到达最大位置,数组需要扩容了才能容下更多的元素
if (_nodes.Length == currentSize)
{
//扩容,参数是代表数组最小容量
Grow(currentSize + 1);
}
if (_comparer == null)
{
MoveUpDefaultComparer((element, priority), currentSize);
}
else
{
MoveUpCustomComparer((element, priority), currentSize);
}
}
private void Grow(int minCapacity)
{
//增长倍数
const int GrowFactor = 2;
//每次扩容的最小值
const int MinimumGrow = 4;
//每次扩容都2倍扩容
int newcapacity = GrowFactor * _nodes.Length;
//数组不能大于最大长度
if ((uint)newcapacity > Array.MaxLength) newcapacity = Array.MaxLength;
//使用他们两个的最大值
newcapacity = Math.Max(newcapacity, _nodes.Length + MinimumGrow);
//如果比参数小,则使用参数的最小值
if (newcapacity < minCapacity) newcapacity = minCapacity;
//重新分配内存,设置大小,因为数组的保存在内存中是连续的
Array.Resize(ref _nodes, newcapacity);
}
private void MoveUpDefaultComparer((TElement Element, TPriority Priority) node, int nodeIndex)
{
//nodes保存副本
(TElement Element, TPriority Priority)[] nodes = _nodes;
//这里入队操作是从空闲索引第一个位置开始插入
while (nodeIndex > 0)
{
//找父节点索引位置
int parentIndex = GetParentIndex(nodeIndex);
(TElement Element, TPriority Priority) parent = nodes[parentIndex];
//插入节点和父节点比较,如果小于0(默认比较器情况下构建的小顶堆),则交换位置
if (Comparer<TPriority>.Default.Compare(node.Priority, parent.Priority) < 0)
{
nodes[nodeIndex] = parent;
nodeIndex = parentIndex;
}
//算是性能优化吧,不必检查所有节点,当发现大于时,就直接退出就可以了
else
{
break;
}
}
//将插入节点放到它应该的位置
nodes[nodeIndex] = node;
}
单元总结:
- 首先记录当前元素最大的索引位置,根据适当的情况来扩容。
- 扩容正常情况下是以2倍的增长速度扩容。
- 插入数据时,从最后一个节点的父节点向上还是找,比较元素的Priority,交换位置,默认情况下是构建小顶堆。
出队操作
出队操作简单来说就是将根元素返回并移除(也就是数组的第一个元素),然后根据比较器将最小或最大的元素放到堆顶,请看如下代码:
public TElement Dequeue()
{
if (_size == 0)
{
throw new InvalidOperationException(SR.InvalidOperation_EmptyQueue);
}
//将堆顶元素返回
TElement element = _nodes[0].Element;
//然后调整堆
RemoveRootNode();
return element;
}
private void RemoveRootNode()
{
//记录最后一个元素的索引位置,并且将堆的大小-1
int lastNodeIndex = --_size;
_version++;
if (lastNodeIndex > 0)
{
//堆的大小已经被减1,所以将最后一个元素作为副本,开始从堆顶重新整理堆
(TElement Element, TPriority Priority) lastNode = _nodes[lastNodeIndex];
if (_comparer == null)
{
MoveDownDefaultComparer(lastNode, 0);
}
else
{
MoveDownCustomComparer(lastNode, 0);
}
}
if (RuntimeHelpers.IsReferenceOrContainsReferences<(TElement, TPriority)>())
{
//将最后一个位置的元素设置为默认值
_nodes[lastNodeIndex] = default;
}
}
private void MoveDownDefaultComparer((TElement Element, TPriority Priority) node, int nodeIndex)
{
(TElement Element, TPriority Priority)[] nodes = _nodes;
//堆的实际大小
int size = _size;
int i;
//当左子节点的索引小于堆的实际大小时
while ((i = GetFirstChildIndex(nodeIndex)) < size)
{
//左子节点元素
(TElement Element, TPriority Priority) minChild = nodes[i];
//当前左子节点的索引
int minChildIndex = i;
//这里即找到所有同一个父节点的相邻子节点,但是要判断是否超出了总的大小
int childIndexUpperBound = Math.Min(i + Arity, size);
//按照索引区间顺序查找,并根据比较器找到最小的子元素位置
while (++i < childIndexUpperBound)
{
(TElement Element, TPriority Priority) nextChild = nodes[i];
if (Comparer<TPriority>.Default.Compare(nextChild.Priority, minChild.Priority) < 0)
{
minChild = nextChild;
minChildIndex = i;
}
}
//如果最后一个节点的元素,比这个最小的元素还小,那么直接放到父节点即可
if (Comparer<TPriority>.Default.Compare(node.Priority, minChild.Priority) <= 0)
{
break;
}
//将最小的子元素赋值给父节点
nodes[nodeIndex] = minChild;
nodeIndex = minChildIndex;
}
//将最后一个节点放到空闲出来的索引位置
nodes[nodeIndex] = node;
}
单元总结:
- 返回根节点元素,然后移除根节点元素,调整堆。
- 从根节点开始,依次查找对应父节点的所有子节点,放到堆顶,也就是数组索引0的位置,然后如果树还有层数,继续循环查找。
- 将最后一个元素放到堆适当的位置,然后再将最后一个位置的元素置为默认值。
总结
通过源码的解读,除了了解类的设计之外,更对对优先级队列数据结构的实现有了更加深刻和清晰的认识。
这里也只是粘贴出主要的代码,需要看详细代码的请点击这里,笔者可能有一些解读错误的地方,欢迎评论指正。
到此这篇关于C#中PriorityQueue(优先级队列)的实现的文章就介绍到这了,更多相关C#优先级队列内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
C#中38个常用运算符的优先级的划分和理解
在C#中,一共有38个常用的运用符,根据它们所执行运算的特点和它们的优先级,为了便于记忆,我将它们归为七个等级:1.单元运算符和括号.2.常规算术运算符.3.位移运算符.4.比较运算符.5.逻辑运算符.6.各种赋值运算符.7.右位(后缀)单元运算符. 1.在这一级中,有++.--(做为前缀).().+.-(做为单元运算符).!.~.这一级中都是单元运算符,除了其中那一对特殊的具有改变任何运算优先级的括号.这此可以看出,在定义表达式中,那些单元运算符的优先级是很高的,可能是因为它们都直接作用于操作
-

C#中实现PriorityQueue优先级队列的代码
前言 前段时间看到有大佬对.net 6.0新出的PriorityQueue(优先级队列)数据结构做了解析,但是没有源码分析,所以本着探究源码的心态,看了看并分享出来.它不像普通队列先进先出(FIFO),而是根据优先级出队. ps:读者多注意代码的注释. D叉树的认识(d-ary heap) 首先我们在表示一个堆(大顶堆或小顶堆)的时候,实际上是通过一个一维数组来维护一个二叉树(d=2,d表示每个父节点最多有几个子节点),首先看下图的二叉树,数字代表索引: 任意一个节点的父节点的索引为:(inde
-
解析Java中PriorityQueue优先级队列结构的源码及用法
一.PriorityQueue的数据结构 JDK7中PriorityQueue(优先级队列)的数据结构是二叉堆.准确的说是一个最小堆. 二叉堆是一个特殊的堆, 它近似完全二叉树.二叉堆满足特性:父节点的键值总是保持固定的序关系于任何一个子节点的键值,且每个节点的左子树和右子树都是一个二叉堆. 当父节点的键值总是大于或等于任何一个子节点的键值时为最大堆. 当父节点的键值总是小于或等于任何一个子节点的键值时为最小堆. 下图是一个最大堆 priorityQueue队头就是给定顺序的最小元素. prio
-
Go 实战单队列到优先级队列实现图文示例
目录 优先级队列概述 为什么需要优先级队列 优先级队列实现原理 01 四个角色 02 队列-消费者模式 03 单队列-单消费者模式实现 3.1 队列的实现 3.2 工作单元--Job的实现 3.3 消费者Worker的实现 04 多队列-单消费者模式 05 多队列-多消费者模式 总结 优先级队列概述 队列,是数据结构中实现先进先出策略的一种数据结构.而优先队列则是带有优先级的队列,即先按优先级分类,然后相同优先级的再 进行排队.优先级高的队列中的元素会优先被消费.如下图所示: 在Go中,可以定义
-
Java数据结构之优先级队列(PriorityQueue)用法详解
目录 概念 PriorityQueue的使用 小试牛刀(最小k个数) 堆的介绍 优先级队列的模拟实现 Top-k问题 概念 优先级队列是一种先进先出(FIFO)的数据结构,与队列不同的是,操作的数据带有优先级,通俗的讲就是可以比较大小,在出队列的时候往往需要优先级最高或者最低的元素先出队列,这种数据结构就是优先级队列(PriorityQueue) PriorityQueue的使用 构造方法 这里只介绍三种常用的构造方法 构造方法 说明 PriorityQueue() 不带参数,默认容量为11 P
-
C++ 中"priority_queue" 优先级队列实例详解
C++ 中"priority_queue" 优先级队列实例详解 1. 简介 标准库队列使用了先进先出(FIFO)的存储和检索策略. 进入队列的对象被放置在尾部, 下一个被取出的元素则取自队列的首部. 标准库提供了两种风格的队列: FIFO 队列(FIFO queue, 简称 queue), 以及优先级队列(priority queue). priority_queue 允许用户为队列中存储的元素设置优先级. 这种队列不是直接将新元素放置在队列尾部, 而是放在比它优先级低的元素前面. 标
-
Python中栈、队列与优先级队列的实现方法
前言 栈.队列和优先级队列都是非常基础的数据结构.Python作为一种"编码高效"的语言,对这些基础的数据结构都有比较好的实现.在业务需求开发过程中,不应该重复造轮子,今天就来看看些数据结构都有哪些实现. 0x00 栈(Stack) 栈是一种LIFO(后进先出)的数据结构,有入栈(push).出栈(pop)两种操作,且只能操作栈顶元素. 在Python中有多种可以实现栈的数据结构. 1.list list是Python内置的列表数据结构,它支持栈的特性,有入栈和出栈操作.只不过用lis
-
C++ 中"priority_queue" 优先级队列实例详解
C++ 中"priority_queue" 优先级队列实例详解 1. 简介 标准库队列使用了先进先出(FIFO)的存储和检索策略. 进入队列的对象被放置在尾部, 下一个被取出的元素则取自队列的首部. 标准库提供了两种风格的队列: FIFO 队列(FIFO queue, 简称 queue), 以及优先级队列(priority queue). priority_queue 允许用户为队列中存储的元素设置优先级. 这种队列不是直接将新元素放置在队列尾部, 而是放在比它优先级低的元素前面. 标
-
Python实现优先级队列结构的方法详解
最简单的实现 一个队列至少满足2个方法,put和get. 借助最小堆来实现. 这里按"值越大优先级越高"的顺序. #coding=utf-8 from heapq import heappush, heappop class PriorityQueue: def __init__(self): self._queue = [] def put(self, item, priority): heappush(self._queue, (-priority, item)) def get(
-
Python cookbook(数据结构与算法)实现优先级队列的方法示例
本文实例讲述了Python实现优先级队列的方法.分享给大家供大家参考,具体如下: 问题:要实现一个队列,它能够以给定的优先级对元素排序,且每次pop操作时都会返回优先级最高的那个元素: 解决方案:采用heapq模块实现一个简单的优先级队列 # example.py # # Example of a priority queue import heapq class PriorityQueue: def __init__(self): self._queue = [] self._index =
-
Python实现一个优先级队列的方法
问题 怎样实现一个按优先级排序的队列? 并且在这个队列上面每次 pop 操作总是返回优先级最高的那个元素 解决方案 下面的类利用 heapq 模块实现了一个简单的优先级队列: import heapq class PriorityQueue: def __init__(self): self._queue = [] self._index = 0 def push(self, item, priority): heapq.heappush(self._queue, (-priority, sel