python3爬虫GIL修改多线程实例讲解
我们打开程序后,会发现电脑的内存和cpu发生了变化。在对于前者上面,自然是希望内容占用小,cpu的利用越高越好。那有没有什么方法可以让我们的cpu达到满状态的运行效果呢?这就得用到我们所学的多线程中的知识了,再正式开始讲解之前,我们先来说说操作的思路吧,然后进行代码对比。
我们都知道,比方我有一个4核的CPU,那么这样一来,在单位时间内每个核只能跑一个线程,然后时间片轮转切换。但是Python不一样,它不管你有几个核,单位时间多个核只能跑一个线程,然后时间片轮转。看起来很不可思议?但是这就是GIL搞的鬼。任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释器。我们不妨做个试验:
#coding=utf-8
from multiprocessing import Pool
from threading import Thread
from multiprocessing import Process
def loop():
while True:
pass
if __name__ == '__main__':
for i in range(3):
t = Thread(target=loop)
t.start()
while True:
pass
我的电脑是4核,所以我开了4个线程,看一下CPU资源占有率:

我们发现CPU利用率并没有占满,大致相当于单核水平。
而如果我们变成进程呢?
我们改一下代码:
#coding=utf-8
from multiprocessing import Pool
from threading import Thread
from multiprocessing import Process
def loop():
while True:
pass
if __name__ == '__main__':
for i in range(3):
t = Process(target=loop)
t.start()
Pass
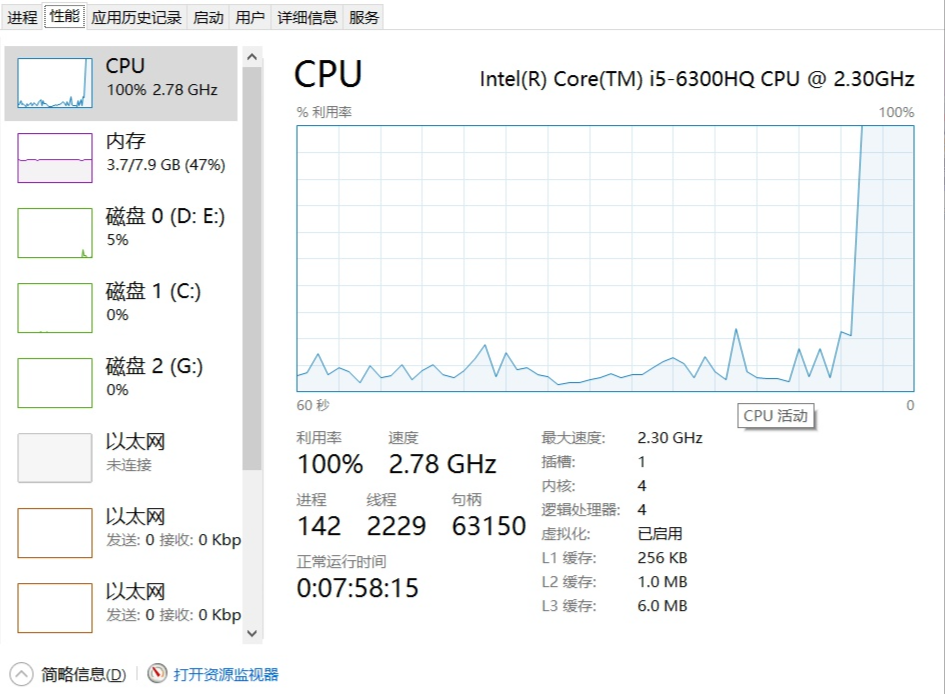
结果直接飙到了100%,说明进程是可以利用多核的!
以上就是python3爬虫GIL修改多线程实例讲解的详细内容,更多关于python3爬虫中的GIL修改多线程的资料请关注我们其它相关文章!
相关推荐
-
python3爬虫GIL修改多线程实例讲解
我们打开程序后,会发现电脑的内存和cpu发生了变化.在对于前者上面,自然是希望内容占用小,cpu的利用越高越好.那有没有什么方法可以让我们的cpu达到满状态的运行效果呢?这就得用到我们所学的多线程中的知识了,再正式开始讲解之前,我们先来说说操作的思路吧,然后进行代码对比. 我们都知道,比方我有一个4核的CPU,那么这样一来,在单位时间内每个核只能跑一个线程,然后时间片轮转切换.但是Python不一样,它不管你有几个核,单位时间多个核只能跑一个线程,然后时间片轮转.看起来很不可思议?但是这就是GI
-

Python3操作SQL Server数据库(实例讲解)
1.前言 前面学完了SQL Server的基本语法,接下来学习如何在程序中使用sql,毕竟不能在程序中使用的话,实用性就不那么大了. 2.最基本的SQL查询语句 python是使用pymssql这个模块来操作SQL Server数据库的,所有需要先安装pymssql. 这个直接在命令行里输入pip install pymssql安装就行了 然后还要配置好自己本地的SQL Server数据库,进入Microsoft SQL Server Management Studio中可以进行设置.如果你选择
-
Java 多线程实例讲解(一)
Java多线程(一) 多线程作为Java中很重要的一个知识点,在此还是有必要总结一下的. 一.线程的生命周期及五种基本状态 关于Java中线程的生命周期,首先看一下下面这张较为经典的图: 上图中基本上囊括了Java中多线程各重要知识点.掌握了上图中的各知识点,Java中的多线程也就基本上掌握了.主要包括: Java线程具有五中基本状态 新建状态(New):当线程对象对创建后,即进入了新建状态,如:Thread t = new MyThread(); 就绪状态(Runnable):当调用线程对象的
-
Python3.6 Schedule模块定时任务(实例讲解)
一,编程环境 PyCharm2016,Anaconda3 Python3.6 需要安装schedule模块,该模块网址:https://pypi.python.org/pypi/schedule 打开Anaconda Prompt,输入:conda install schedule 提示:Package Not Found Error 于是,使用 pip 安装.由于Anaconda3 中已经自带了pip,如下图: 于是 cmd 命令行切换到 scripts 目录,执行 pip.exe insta
-
python爬虫scrapy图书分类实例讲解
我们去图书馆的时候,会直接去自己喜欢的分类栏目找寻书籍.如果其中的分类不是很细致的话,想找某一本书还是有一些困难的.同样的如果我们获取了一些图书的数据,原始的文件里各种数据混杂在一起,非常不利于我们的查找和使用.所以今天小编教大家如何用python爬虫中scrapy给图书分类,大家一起学习下: spider抓取程序: 在贴上代码之前,先对抓取的页面和链接做一个分析: 网址:http://category.dangdang.com/pg4-cp01.25.17.00.00.00.html 这个是当
-
celery在python爬虫中定时操作实例讲解
使用定时功能对于我们想要快速获取某个数据来说,是一个非常好的方法.这样我们就不用苦苦守在电脑屏幕前,只为蹲到某个想要的东西.在之前我们已经讲过time函数进行定时操作,这算是time函数的比较基础的一个用法了.其实定时功能同样可以用celery实现,具体的方法我们往下看: 爬虫由于其特殊性,可能需要定时做增量抓取,也可能需要定时做模拟登陆,以防止cookie过期,而celery恰恰就实现了定时任务的功能.在上述基础上,我们将`tasks.py`文件改成如下内容 from celery impor
-
Python3爬虫ChromeDriver的安装实例
Python爬虫不仅仅可以爬取静态网页,也可以爬取抓取动态网页.但是新版的Selenium不支持PhantomJS,无法进行动态网页的爬取,因此要放弃PhantomJS,直接用headless ChromeDriver.本文介绍安装ChromeDriver的过程. 1.为什么要安装ChromeDriver? 使用Python的第三方库selenium需要对应的浏览器驱动器ChromeDriver. 2.相关链接 官方网站:https://sites.google.com/a/chromium.o
-
Python3.5文件修改操作实例分析
本文实例讲述了Python3.5文件修改操作.分享给大家供大家参考,具体如下: 1.文件修改的两种方式 (1)像vim一样将文件加载到内存中,修改完之后再写回源文件. (2)打开文件,修改后写入到一个新的文件中. 注:这里操作的txt文本文件可参考前面一篇 Python3.5文件读与写操作 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:ZhengzhengLiu f = open("song",'r',encoding=&q
-
Python3实现简单可学习的手写体识别(实例讲解)
1.前言 版本:Python3.6.1 + PyQt5 + SQL Server 2012 以前一直觉得,机器学习.手写体识别这种程序都是很高大上很难的,直到偶然看到了这个视频,听了老师讲的思路后,瞬间觉得原来这个并不是那么的难,原来我还是有可能做到的. 于是我开始顺着思路打算用Python.PyQt.SQLServer做一个出来,看看能不能行.然而中间遇到了太多的问题,数据库方面的问题有十几个,PyQt方面的问题有接近一百个,还有数十个Python基础语法的问题.但好在,通过不断的Google
-
Java 多线程实例详解(三)
本文主要接着前面多线程的两篇文章总结Java多线程中的线程安全问题. 一.一个典型的Java线程安全例子 public class ThreadTest { public static void main(String[] args) { Account account = new Account("123456", 1000); DrawMoneyRunnable drawMoneyRunnable = new DrawMoneyRunnable(account, 700); Thr