分布式调度XXL-Job整合Springboot2.X实战操作
一、定时任务的使用场景和常见的定时任务
二、如何选择哪一个分布式任务调度平台
三、xxl-job的设计思想
四、XXL-Job具有哪些特性
五、XXL-Job实战操作
一、定时任务的使用场景和常见的定时任务
某个时间定时处理某个任务、发邮件、短信、消息提醒、订单通知、统计报表等
定时任务划分
单机定时任务:
单机的容易实现,但应用于集群环境做分布式部署,就会带来重复执行
解决方案有很多比如加锁、数据库等,但是增加了很多非业务逻辑
分布式调度:
把需要处理的计划任务放入到统一的平台,实现集群管理调度与分布式部署的定时任务 叫做分布式定时任务
支持集群部署、高可用、并行调度、分片处理等
常见定时任务:
单机:Java自带的java.util.Timer类配置比较麻烦,时间延后问题
单机:ScheduledExecutorService
是基于线程池来进行设计的定时任务类,在这里每个调度的任务都会分配到线程池里的一个线程去执行该任务,并发执行,互不影响单机:SpringBoot框架自带
SpringBoot使用注解方式开启定时任务
启动类里面 @EnableScheduling开启定时任务,自动扫描
定时任务业务类 加注解 @Component被容器扫描
定时执行的方法加上注解 @Scheduled(fixedRate=2000) 定期执行一次分布式任务调度框架 Elastic-Job/XXL-Job/Quartz
二、如何选择哪一个分布式任务调度平台
Elastic-job和XXL-JOB对比图

XXL-Job和Elastic-Job都具有广泛的用户基础和完善的技术文档,都可以满足定时任务的基本功能需求
xxl-job侧重在业务实现简单和管理方便,容易学习,失败与路由策略丰富, 推荐使用在用户基数相对较少,服务器的数量在一定的范围内的场景下使用elastic-job关注的点在数据,添加了弹性扩容和数据分片的思路,更方便利用分布式服务器的资源, 但是学习难度较大,推荐在数据量庞大,服务器数量多的时候使用
三、xxl-job的设计思想
将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
将任务抽象成分散的JobHandler,交由“执行器”统一管理
“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。
因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性
架构系统组成:
调度中心
负责管理调度的信息,按照调度的配置来发出调度请求
支持可视化、简单的动态管理调度信息,包括新建、删除、更新等,这些操作都会实时生效,同时也支持监控调度结果以及执行日志。
执行器
负责接收请求并且执行任务的逻辑。任务模块专注于任务的执行操作等等,使得开发和维护更加的简单与高效
架构图(图片来源是xxl-job官网)

四、XXL-Job具有哪些特性
调度中心HA(中心式):调度采用了中心式进行设计,“调度中心”支持集群部署,可保证调度中心HA
执行器HA(分布式):任务分布式的执行,任务执行器支持集群部署,可保证任务执行HA
触发策略:有Cron触发、固定间隔触发、固定延时触发、API事件触发、人工触发、父子任务触发
路由策略:执行器在集群部署的时候提供了丰富的路由策略,如:第一个、最后一个、轮询、随机、一致性HASH、最不经常使用LFU、最久未使用LRU、故障转移等等
故障转移:如果执行器集群的一台机器发生故障,会自动切换到一台正常的执行器发送任务调度
Rolling实时日志的监控:支持rolling方式查看输入的完整执行日志
脚本任务:支持GLUE模式开发和运行脚本任务,包括Shell、python、node.js、php等等类型脚本
五、XXL-Job实战操作
搭建XXL-Job相关环境步骤:
创建数据库脚本
部署XXL-Job服务端
客户端项目添加依赖
注意
Client-Server通信,需要网络互通才行
所以不能一个是阿里云ECS,一个是本地电脑
建议:本地电脑安装Docker,或者本地Linux虚拟机安装Docker部署
本博文是直接拉取的源码然后在本地win7打包部署的。
步骤一: 进入GitHub - xuxueli/xxl-job at 2.2.0 地址,根项目需求拉取对应版本代码

下载压缩包,这里下载的版本需要跟后面依赖的版本一致, 切换到2.2.0版本下载压缩包。

第二步:
下载后再idea中打开
第三步 打开doc文件夹,找到里面的db tables_xxl_job.sql,然后拿到navicat中运行
数据库脚本(使用mysql8)
xxl_job 的数据库里有如下几个表
xxl_job_group:执行器信息表,用于维护任务执行器的信息
xxl_job_info:调度扩展信息表,主要是用于保存xxl-job的调度任务的扩展信息,比如说像任务分组、任务名、机器的地址等等
xxl_job_lock:任务调度锁表
xxl_job_log:日志表,主要是用在保存xxl-job任务调度历史信息,像调度结果、执行结果、调度入参等等
xxl_job_log_report:日志报表,会存储xxl-job任务调度的日志报表,会在调度中心里的报表功能里使用到
xxl_job_logglue:任务的GLUE日志,用于保存GLUE日志的更新历史变化,支持GLUE版本的回溯功能
xxl_job_registry:执行器的注册表,用在维护在线的执行器与调度中心的地址信息
xxl_job_user:系统的用户表

更改刚拉下代码配置中的数据库连接:

本地打包启动:
mvn install

jar -jar win7启动xxl-job服务包

第四步:
访问地址:http://127.0.0.1:8080/xxl-job-admin/ admin/123456
初次进来的运行报表:
以图形化来展示了整体的任务执行情况
任务数量:能够看到调度中心运行的任务数量
调度次数:调度中心所触发的调度次数
执行器数量:在整个调度中心中,在线的执行器数量有多少

第五步 开始跟项目代码整合:
pom.xml依赖引入
<xxl-job.version>2.2.0</xxl-job.version><!-- https://mvnrepository.com/artifact/com.xuxueli/xxl-job-core --> <dependency> <groupId>com.xuxueli</groupId> <artifactId>xxl-job-core</artifactId> <version>${xxl-job.version}</version> </dependency>第六步 新增logback.xml
<?xml version="1.0" encoding="UTF-8"?><configuration debug="false" scan="true" scanPeriod="1 seconds"> <contextName>logback</contextName> <property name="log.path" value="./data/logs/xxl-job/app.log"/> <appender name="console" class="ch.qos.logback.core.ConsoleAppender"> <encoder> <pattern>%d{HH:mm:ss.SSS} %contextName [%thread] %-5level %logger{36} - %msg%n</pattern> </encoder> </appender> <appender name="file" class="ch.qos.logback.core.rolling.RollingFileAppender"> <file>${log.path}</file> <rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"> <fileNamePattern>${log.path}.%d{yyyy-MM-dd}.zip</fileNamePattern> </rollingPolicy> <encoder> <pattern>%date %level [%thread] %logger{36} [%file : %line] %msg%n </pattern> </encoder> </appender> <root level="info"> <appender-ref ref="console"/> <appender-ref ref="file"/> </root></configuration>第七步 application.properties增加配置项
#----------xxl-job配置--------------logging.config=classpath:logback.xml#调度中心部署地址,多个配置逗号分隔 "http://address01,http://address02"xxl.job.admin.addresses=http://127.0.0.1:8080/xxl-job-admin#执行器token,非空时启用 xxl-job, access token。需要跟xxl-job-master服务中的同配置一模一样xxl.job.accessToken=xxxxx.net168# 执行器app名称,和控制台那边配置一样的名称,不然注册不上去xxl.job.executor.appname=traffic-app-executor# [选填]执行器注册:优先使用该配置作为注册地址,为空时使用内嵌服务 ”IP:PORT“ 作为注册地址。#从而更灵活的支持容器类型执行器动态IP和动态映射端口问题。xxl.job.executor.address=#[选填]执行器IP :默认为空表示自动获取IP(即springboot容器的ip和端口,可以自动获取,也可以指定),多网卡时可手动设置指定IP,该IP不会绑定Host仅作为通讯实用;地址信息用于 "执行器注册" 和 "调度中心请求并触发任务",xxl.job.executor.ip=# [选填]执行器端口号:小于等于0则自动获取;默认端口为9999,单机部署多个执行器时,注意要配置不同执行器端口;xxl.job.executor.port=9999#执行器日志文件存储路径,需要对该路径拥有读写权限;为空则使用默认路径xxl.job.executor.logpath=./data/logs/xxl-job/executor#执行器日志保存天数xxl.job.executor.logretentiondays=30配置图解:
1.上述 配置xxl.job.accessToken=xxxxx.net168的值 和 xxl-job-2.2.0里面的配置xxl.job.accessToken的值需要一模一样

2.xxl.job.executor.appname=traffic-app-executor 执行器的名称
需要跟调度中心执行器名称一模一样,不然注册不上去

properties配置加完后,需要增加一个.java的配置读取类:
package net.wnn.config;import com.xxl.job.core.executor.impl.XxlJobSpringExecutor;import lombok.extern.slf4j.Slf4j;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;@Configuration@Slf4jpublic class XxlJobConfig { @Value("${xxl.job.admin.addresses}") private String adminAddresses; @Value("${xxl.job.executor.appname}") private String appName; @Value("${xxl.job.executor.ip}") private String ip; @Value("${xxl.job.executor.port}") private int port; @Value("${xxl.job.accessToken}") private String accessToken; @Value("${xxl.job.executor.logpath}") private String logPath; @Value("${xxl.job.executor.logretentiondays}") private int logRetentionDays; @Bean public XxlJobSpringExecutor xxlJobSpringExecutor(){ log.info("》》》》》这是王姑娘的 xxl job 配置初始化 方法"); XxlJobSpringExecutor xxlJobSpringExecutor = new XxlJobSpringExecutor(); xxlJobSpringExecutor.setAdminAddresses(adminAddresses); xxlJobSpringExecutor.setAppname(appName); xxlJobSpringExecutor.setIp(ip); xxlJobSpringExecutor.setPort(port); xxlJobSpringExecutor.setAccessToken(accessToken); xxlJobSpringExecutor.setLogPath(logPath); xxlJobSpringExecutor.setLogRetentionDays(logRetentionDays); return xxlJobSpringExecutor; }}第八步 创建你的第一个XXL-Job分布式调度任务代码:
package net.wnn.job;import com.xxl.job.core.biz.model.ReturnT;import com.xxl.job.core.handler.annotation.XxlJob;import lombok.extern.slf4j.Slf4j;import net.wnn.service.TrafficService;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.stereotype.Component;@Component@Slf4jpublic class TrafficJobHandler { @Autowired private TrafficService trafficService; /** * 过期流量包处理 * @param param * @return */ @XxlJob(value = "trafficExpiredHandler",init = "init",destroy = "destroy") public ReturnT<String> execute(String param){ log.info(" execute 任务方法触发成功,删除过期流量包"); return ReturnT.SUCCESS; } private void init(){ log.info(" MyJobHandler init >>>>>"); } private void destroy(){ log.info(" MyJobHandler destroy >>>>>"); }}这步骤写完之后,需要启动下应用服务,将IP地址注册到xxl-job中,大概启动成功后30S才有。
第九步 :代码写完后,就需要进入客户端进行相关参数的配置了
执行器管理页面:
到xxl-job调度中心里的执行器管理->新增
第一步新增执行器
Appname:是每一个执行器的唯一表示AppName,执行器会以周期性为appname进行注册,为任务调度的时候使用
名称:执行器的名称,因为appname有限制字母与数字等等组成,可读性不强,这个名称就是为了提高执行器的可读性
注册方式:调度中心获取执行器地址的方式
自动注册:执行器自动进行执行器的注册,通过底层的注册表可以动态的发现执行器机器的地址
手动录入:人工手动录入执行器的地址信息,多地址使用逗号进行分割,供调度中心使用
机器地址:“注册方式”为手动录入的时候才能使用,支持人工维护执行器的地址
点击保存后可能要等30S左右才回显示机器的地址

第二步 新建任务管理:
其中JobHandler需要和代码中的@xxljob value一模一样


新建完任务后就惦记保存,然后再列表页面的操作中下拉后选择执行一次:


选择启动模式的话,就是按设定的cron表达式执行: 上述任务设置的是一秒一次

调度成功日志:
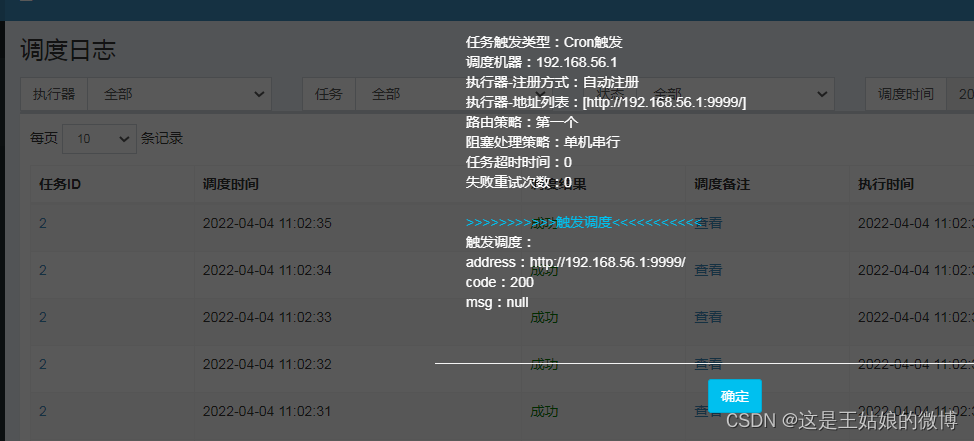
运行报表页面:

到这分布式调度XXL-Job就整合完毕啦~
相关推荐
-

分布式调度XXL-Job整合Springboot2.X实战操作
一.定时任务的使用场景和常见的定时任务 二.如何选择哪一个分布式任务调度平台 三.xxl-job的设计思想 四.XXL-Job具有哪些特性 五.XXL-Job实战操作 一.定时任务的使用场景和常见的定时任务 某个时间定时处理某个任务.发邮件.短信.消息提醒.订单通知.统计报表等 定时任务划分 单机定时任务: 单机的容易实现,但应用于集群环境做分布式部署,就会带来重复执行 解决方案有很多比如加锁.数据库等,但是增加了很多非业务逻辑 分布式调度: 把需要处理的计划任务放入
-
分布式调度XXL-Job整合Springboot2.X实战操作过程(推荐)
目录 一.定时任务的使用场景和常见的定时任务 二.如何选择哪一个分布式任务调度平台 三.xxl-job的设计思想 四.XXL-Job具有哪些特性 五.XXL-Job实战操作 一.定时任务的使用场景和常见的定时任务 某个时间定时处理某个任务.发邮件.短信.消息提醒.订单通知.统计报表等 定时任务划分 单机定时任务:单机的容易实现,但应用于集群环境做分布式部署,就会带来重复执行解决方案有很多比如加锁.数据库等,但是增加了很多非业务逻辑分布式调度:把需要处理的计划任务放入到统一的平台,实现集群管理调度
-
Spring整合Quartz分布式调度的示例代码
前言 为了保证应用的高可用和高并发性,一般都会部署多个节点:对于定时任务,如果每个节点都执行自己的定时任务,一方面耗费了系统资源, 另一方面有些任务多次执行,可能引发应用逻辑问题,所以需要一个分布式的调度系统,来协调每个节点执行定时任务. Spring整合Quartz Quartz是一个成熟的任务调度系统,Spring对Quartz做了兼容,方便开发,下面看看具体如何整合: 1.Maven依赖文件 <dependencies> <dependency> <groupId>
-
分布式医疗挂号系统整合Gateway网关解决跨域问题
目录 一.Gateway网关简介 二.Gateway使用步骤 步骤1:搭建模块并引入依赖 步骤2:添加配置文件 步骤3:创建启动类 网关初步测试 三.Gateway解决跨域问题 一.Gateway网关简介 API 网关是介于客户端和服务器端之间的中间层,所有的外部请求都会先经过API 网关这一层.也就是说,API 的实现方面更多的考虑业务逻辑,而安全.性能.监控可以交由 API 网关来做,这样既提高业务灵活性又不缺安全性. Spring cloud gateway是spring官方基于Sprin
-
玩转SpringBoot2快速整合拦截器的方法
概述 首先声明一下,这里所说的拦截器是 SpringMVC 的拦截器(HandlerInterceptor).使用SpringMVC 拦截器需要做如下操作: 创建拦截器类需要实现 HandlerInterceptor 在 xml 配置文件中配置该拦截器,具体配置代码如下: <mvc:interceptors> <mvc:interceptor> <!-- /test/** 这个是拦截路径以/test开头的所有的URL--> <mvc:mapping path=&q
-
SpringBoot2.0整合Shiro框架实现用户权限管理的示例
GitHub源码地址:知了一笑 https://github.com/cicadasmile/middle-ware-parent 一.Shiro简介 1.基础概念 Apache Shiro是一个强大且易用的Java安全框架,执行身份验证.授权.密码和会话管理.作为一款安全框架Shiro的设计相当巧妙.Shiro的应用不依赖任何容器,它不仅可以在JavaEE下使用,还可以应用在JavaSE环境中. 2.核心角色 1)Subject:认证主体 代表当前系统的使用者,就是用户,在Shiro的认证中,
-
SpringBoot2整合ElasticJob框架过程详解
一.ElasticJob 简介 1.定时任务 在前面的文章中,说过QuartJob这个定时任务,被广泛应用的定时任务标准.但Quartz核心点在于执行定时任务并不是在于关注的业务模式和场景,缺少高度自定义的功能.Quartz能够基于数据库实现任务的高可用,但是不具备分布式并行调度的功能. -> QuartJob定时任务 2.ElasticJob说明基础简介 Elastic-Job 是一个开源的分布式调度中间件,由两个相互独立的子项目 Elastic-Job-Lite 和 Elastic-Job-
-
SpringBoot2 整合Nacos组件及环境搭建和入门案例解析
目录 一.Nacos基础简介 1.概念简介 2.关键特性 3.专业术语解释 4.Nacos生态圈 二.Nacos环境搭建 1.环境版本 2.环境包下载 3.启动环境启动文件地址: 三.整合SpringBoot2 1.新建配置 2.核心依赖 3.Yml配置文件 4.启动类配置 5.核心配置类 6.基础API用例 四.源代码地址 本文源码:GitHub·点这里 || GitEE·点这里 一.Nacos基础简介 1.概念简介 Nacos 是构建以“服务”为中心的现代应用架构,如微服务范式.云原生范式等
-
php项目接入xxl-job调度系统的示例详解
目录 1. 部署xxl-job调度中心 2. 整合xxl-job调度系统 2.1 创建执行器项目 2.2 新增执行器 2.3 部署执行器项目 2.4 新增GLUE模式任务 2.5 编写php代码片段 1. 部署xxl-job调度中心 此处略,请自行百度.下面重点介绍如何将php项目接入xxl-job调度. 2. 整合xxl-job调度系统 核心是使用xxl-job的GLUE运行模式,通过一段php代码片段,调用远程的http资源. 2.1 创建执行器项目 参考执行器示例项目, xxl-job-
-
分布式任务调度xxl-job问题解决
目录 前言 xxl-job简介 功能如下 快速入门 2.1初始化“调度数据库” 2.2编译源码 2.3配置部署“调度中心” 2.4配置部署“执行器项目” 2.5开发第一个任务“HelloWorld” 前言 在单机应用时期,任务调度一般都是基于spring schedule和集成quartz来实现的,当系统发展成分布式服务,应用多实例的时候,任务就会出现多次调用的问题,很多时候我们任务并不需要跑多次.解决方案有很多,最最简单粗暴的就是可以设置应用开关.其次就是集中式话任务管理调度.当然,quart