pytorch分类模型绘制混淆矩阵以及可视化详解
目录
- Step 1. 获取混淆矩阵
- Step 2. 混淆矩阵可视化
- 其它分类指标的获取
- 总结
Step 1. 获取混淆矩阵
#首先定义一个 分类数*分类数 的空混淆矩阵
conf_matrix = torch.zeros(Emotion_kinds, Emotion_kinds)
# 使用torch.no_grad()可以显著降低测试用例的GPU占用
with torch.no_grad():
for step, (imgs, targets) in enumerate(test_loader):
# imgs: torch.Size([50, 3, 200, 200]) torch.FloatTensor
# targets: torch.Size([50, 1]), torch.LongTensor 多了一维,所以我们要把其去掉
targets = targets.squeeze() # [50,1] -----> [50]
# 将变量转为gpu
targets = targets.cuda()
imgs = imgs.cuda()
# print(step,imgs.shape,imgs.type(),targets.shape,targets.type())
out = model(imgs)
#记录混淆矩阵参数
conf_matrix = confusion_matrix(out, targets, conf_matrix)
conf_matrix=conf_matrix.cpu()
混淆矩阵的求取用到了confusion_matrix函数,其定义如下:
def confusion_matrix(preds, labels, conf_matrix):
preds = torch.argmax(preds, 1)
for p, t in zip(preds, labels):
conf_matrix[p, t] += 1
return conf_matrix
在当我们的程序执行结束 test_loader 后,我们可以得到本次数据的 混淆矩阵,接下来就要计算其 识别正确的个数以及混淆矩阵可视化:
conf_matrix=np.array(conf_matrix.cpu())# 将混淆矩阵从gpu转到cpu再转到np
corrects=conf_matrix.diagonal(offset=0)#抽取对角线的每种分类的识别正确个数
per_kinds=conf_matrix.sum(axis=1)#抽取每个分类数据总的测试条数
print("混淆矩阵总元素个数:{0},测试集总个数:{1}".format(int(np.sum(conf_matrix)),test_num))
print(conf_matrix)
# 获取每种Emotion的识别准确率
print("每种情感总个数:",per_kinds)
print("每种情感预测正确的个数:",corrects)
print("每种情感的识别准确率为:{0}".format([rate*100 for rate in corrects/per_kinds]))
执行此步的输出结果如下所示:

Step 2. 混淆矩阵可视化
对上边求得的混淆矩阵可视化
# 绘制混淆矩阵
Emotion=8#这个数值是具体的分类数,大家可以自行修改
labels = ['neutral', 'calm', 'happy', 'sad', 'angry', 'fearful', 'disgust', 'surprised']#每种类别的标签
# 显示数据
plt.imshow(conf_matrix, cmap=plt.cm.Blues)
# 在图中标注数量/概率信息
thresh = conf_matrix.max() / 2 #数值颜色阈值,如果数值超过这个,就颜色加深。
for x in range(Emotion_kinds):
for y in range(Emotion_kinds):
# 注意这里的matrix[y, x]不是matrix[x, y]
info = int(conf_matrix[y, x])
plt.text(x, y, info,
verticalalignment='center',
horizontalalignment='center',
color="white" if info > thresh else "black")
plt.tight_layout()#保证图不重叠
plt.yticks(range(Emotion_kinds), labels)
plt.xticks(range(Emotion_kinds), labels,rotation=45)#X轴字体倾斜45°
plt.show()
plt.close()
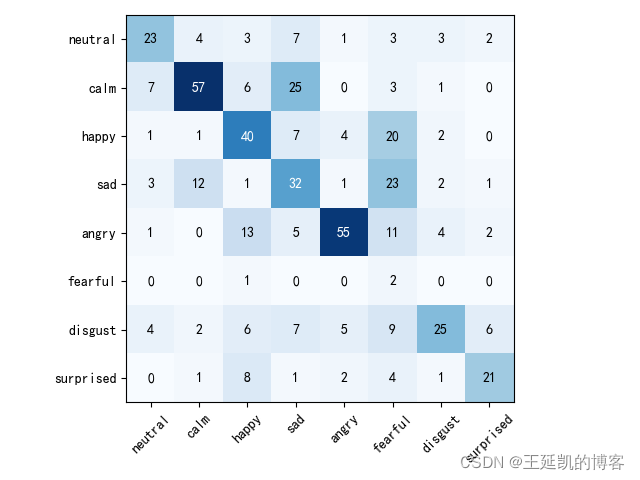
好了,以下就是最终的可视化的混淆矩阵啦:
其它分类指标的获取
例如 F1分数、TP、TN、FP、FN、精确率、召回率 等指标, 待补充哈(因为暂时还没用到)~

总结
到此这篇关于pytorch分类模型绘制混淆矩阵以及可视化详的文章就介绍到这了,更多相关pytorch绘制混淆矩阵内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Pytorch可视化的几种实现方法
一,利用 tensorboardX 可视化网络结构 参考 https://github.com/lanpa/tensorboardX 支持scalar, image, figure, histogram, audio, text, graph, onnx_graph, embedding, pr_curve and video summaries. 例子要求tensorboardX>=1.2 and pytorch>=0.4 安装 pip install tensorboardX 或 pip
-
pytorch 模型可视化的例子
如下所示: 一. visualize.py from graphviz import Digraph import torch from torch.autograd import Variable def make_dot(var, params=None): """ Produces Graphviz representation of PyTorch autograd graph Blue nodes are the Variables that require gra
-
pytorch分类模型绘制混淆矩阵以及可视化详解
目录 Step 1. 获取混淆矩阵 Step 2. 混淆矩阵可视化 其它分类指标的获取 总结 Step 1. 获取混淆矩阵 #首先定义一个 分类数*分类数 的空混淆矩阵 conf_matrix = torch.zeros(Emotion_kinds, Emotion_kinds) # 使用torch.no_grad()可以显著降低测试用例的GPU占用 with torch.no_grad(): for step, (imgs, targets) in enumerate(test_loader)
-
使用Python和scikit-learn创建混淆矩阵的示例详解
目录 一.混淆矩阵概述 1.示例1 2.示例2 二.使用Scikit-learn 创建混淆矩阵 1.相应软件包 2.生成示例数据集 3.训练一个SVM 4.生成混淆矩阵 5.可视化边界 一.混淆矩阵概述 在训练了有监督的机器学习模型(例如分类器)之后,您想知道它的工作情况. 这通常是通过将一小部分称为测试集的数据分开来完成的,该数据用作模型以前从未见过的数据. 如果它在此数据集上表现良好,那么该模型很可能在其他数据上也表现良好 - 当然,如果它是从与您的测试集相同的分布中采样的. 现在,当您测试
-
详解使用python绘制混淆矩阵(confusion_matrix)
Summary 涉及到分类问题,我们经常需要通过可视化混淆矩阵来分析实验结果进而得出调参思路,本文介绍如何利用python绘制混淆矩阵(confusion_matrix),本文只提供代码,给出必要注释. Code # -*-coding:utf-8-*- from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt import numpy as np #labels表示你不同类别的代号,比如这里的de
-
Matplotlib绘制混淆矩阵的实现
对于机器学习多分类模型来说,其评价指标除了精度之外,常用的还有混淆矩阵和分类报告,下面来展示一下如何绘制混淆矩阵,这在论文中经常会用到. 代码如下: import itertools import matplotlib.pyplot as plt import numpy as np # 绘制混淆矩阵 def plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blue
-
PyTorch深度学习模型的保存和加载流程详解
一.模型参数的保存和加载 torch.save(module.state_dict(), path):使用module.state_dict()函数获取各层已经训练好的参数和缓冲区,然后将参数和缓冲区保存到path所指定的文件存放路径(常用文件格式为.pt..pth或.pkl). torch.nn.Module.load_state_dict(state_dict):从state_dict中加载参数和缓冲区到Module及其子类中 . torch.nn.Module.state_dict()函数
-
Python数据分析之绘图和可视化详解
一.前言 matplotlib是一个用于创建出版质量图表的桌面绘图包(主要是2D方面).该项目是由John Hunter于2002年启动的,其目的是为Python构建一个MATLAB式的绘图接口.matplotlib和IPython社区进行合作,简化了从IPython shell(包括现在的Jupyter notebook)进行交互式绘图.matplotlib支持各种操作系统上许多不同的GUI后端,而且还能将图片导出为各种常见的矢量(vector)和光栅(raster)图:PDF.SVG.JPG
-
python机器学习朴素贝叶斯算法及模型的选择和调优详解
目录 一.概率知识基础 1.概率 2.联合概率 3.条件概率 二.朴素贝叶斯 1.朴素贝叶斯计算方式 2.拉普拉斯平滑 3.朴素贝叶斯API 三.朴素贝叶斯算法案例 1.案例概述 2.数据获取 3.数据处理 4.算法流程 5.注意事项 四.分类模型的评估 1.混淆矩阵 2.评估模型API 3.模型选择与调优 ①交叉验证 ②网格搜索 五.以knn为例的模型调优使用方法 1.对超参数进行构造 2.进行网格搜索 3.结果查看 一.概率知识基础 1.概率 概率就是某件事情发生的可能性. 2.联合概率 包
-
对Tensorflow中权值和feature map的可视化详解
前言 Tensorflow中可以使用tensorboard这个强大的工具对计算图.loss.网络参数等进行可视化.本文并不涉及对tensorboard使用的介绍,而是旨在说明如何通过代码对网络权值和feature map做更灵活的处理.显示和存储.本文的相关代码主要参考了github上的一个小项目,但是对其进行了改进. 原项目地址为(https://github.com/grishasergei/conviz). 本文将从以下两个方面进行介绍: 卷积知识补充 网络权值和feature map的可
-
python爬取各省降水量及可视化详解
在具体数据的选取上,我爬取的是各省份降水量实时数据 话不多说,开始实操 正文 1.爬取数据 使用python爬虫,爬取中国天气网各省份24时整点气象数据 由于降水量为动态数据,以js形式进行存储,故采用selenium方法经xpath爬取数据-ps:在进行数据爬取时,最初使用的方法是漂亮汤法(beautifulsoup)法,但当输出爬取的内容(<class = split>时,却空空如也.在源代码界面Ctrl+Shift+F搜索后也无法找到降水量,后查询得知此为动态数据,无法用该方法进行爬取
-
Python数据可视化详解
目录 一.Matplotlib模块 1.绘制基本图表 1. 绘制柱形图 2. 绘制条形图 3. 绘制折线图 4. 绘制面积图 5. 绘制散点图 6. 绘制饼图和圆环图 2.图表的绘制和美化技巧 1. 在一张画布中绘制多个图表 2. 添加图表元素 3. 添加并设置网格线 4. 调整坐标轴的刻度范围 3.绘制高级图表 1. 绘制气泡图 2. 绘制组合图 3. 绘制直方图 4. 绘制雷达图 5. 绘制树状图 6. 绘制箱形图 7. 绘制玫瑰图 二.pyecharts模块 1.图表配置项 2.绘制漏斗图